Quick Outline
This post will demonstrate the following:
How to Stream the Final Output of Agent in LangChain
- Step 1: Installing Frameworks
- Step 2: Setting OpenAI Environment
- Step 3: Importing Libraries
- Step 4: Building Language Model
- Step 5: Building & Initializing the Agent
- Step 6: Handling Custom Answer Prefix
- Step 7: Streaming the Final Output in Tokens
- Step 8: Streaming Prefix Tokens
How to Stream the Final Output of an Agent in LangChain?
Streaming the output means that each word is generated individually at a time and the model considers it as the token. These tokens are easy to manage and use for the model and the machine generates the output regularly. The user can also get the final input as a sentence after the stream is completed.
Streaming is the process of getting the output regularly as tokens consist of work in a sentence. The user gets the answers and makes decisions based on them to train the language model. Agents can understand the process better using the constant generation of data.
To learn the process of streaming the final output of an agent in LangChain, go through the following guide:
Step 1: Installing Frameworks
First of all, install the langchain-experimental dependencies to perform experiments in the natural language domain:
Install the Wikipedia module using the pip command to get the information asked by the user:
Also, install the OpenAI module that can be used to build the language models and add agents to them:
Step 2: Setting OpenAI Environment
Once the modules are installed, set up the environment for the OpenAI account using its API key:
import getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
Step 3: Importing Libraries
After that, import the libraries from the dependencies of LangChain to build the agents and get streams of the final output. The FinalStreamingStdOutCallbackHandler library is used to get the streams of the output of an agent:
#get library to generate the streams of the final output
from langchain.callbacks.streaming_stdout_final_only import (
FinalStreamingStdOutCallbackHandler,
)
#get library to build language models using the OpenAI environment
from langchain.llms import OpenAI
Step 4: Building Language Model
Start building the components like language model using the OpenAI() method with the streaming, FinalStreamingStdOutCallbackHandler(), and temperature arguments:
streaming=True, callbacks=[FinalStreamingStdOutCallbackHandler()], temperature=0
)
Step 5: Building & Initializing the Agent
Load the tools using the Wikipedia and llm_math arguments of using the tools in the language model. After that, initialize the tools using its method with the tools, llm, agent, and verbose parameters before running the agent:
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=False
)
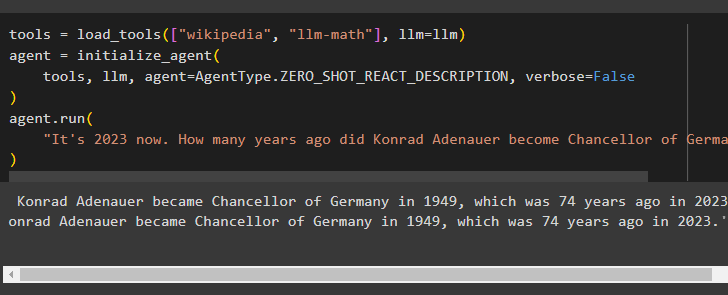
agent.run(
"It's 2023 now. How many years ago did Konrad Adenauer become Chancellor of Germany"
)
Running the agent has extracted the answer to the question asked by the user:
Step 6: Handling Custom Answer Prefix
Add the callbacks parameter to the OpenAI() method to configure the llm variable to get the answers in the form of tokens:
streaming=True,
callbacks=[
FinalStreamingStdOutCallbackHandler(answer_prefix_tokens=["The", "answer", ":"])
],
temperature=0,
)
Step 7: Streaming the Final Output in Tokens
Define the MyCallbackHandler() to explain the behavior of the model until the tokens of the final input are extracted. Configure the language model and tools to initialize the agent before running it again to get the streamed tokens of the final output:
#defining MyCallBackHandler() to generate the tokens for the final answer
class MyCallbackHandler(BaseCallbackHandler):
def on_llm_new_token(self, token, **kwargs) -> None:
print(f"#{token}#")
#building the language model and tools for the agent to execute it using agent variable
llm = OpenAI(streaming=True, callbacks=[MyCallbackHandler()])
tools = load_tools(["wikipedia", "llm-math"], llm=llm)
agent = initialize_agent(
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=False
)
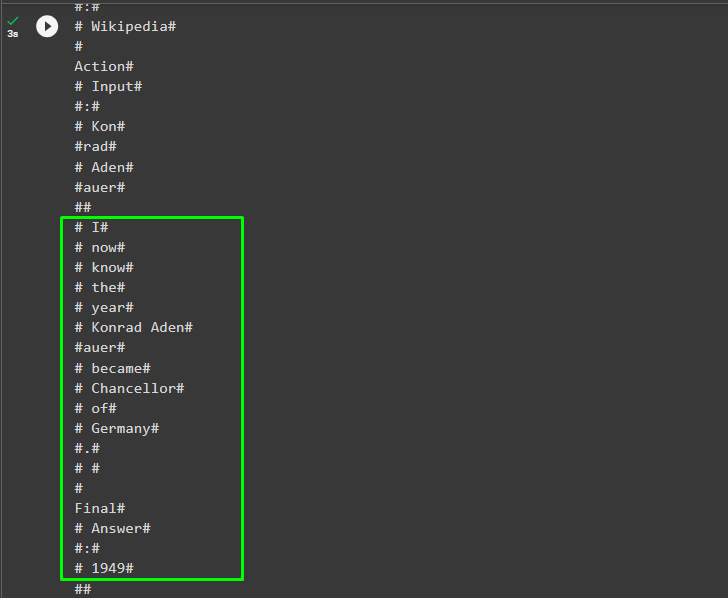
agent.run(
"It's 2023 now so tell me when did Konrad Adenauer become Chancellor of Germany and how many years ago it happened"
)
Output
The following screenshot displays the streams of tokens with the hash character from the first step to the final answer:
Step 8: Streaming the Final Answer
To get the final answer in a sentence with the streamed output, simply add the stream_prefix parameter:
tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, stream_prefix = True, verbose=False
)
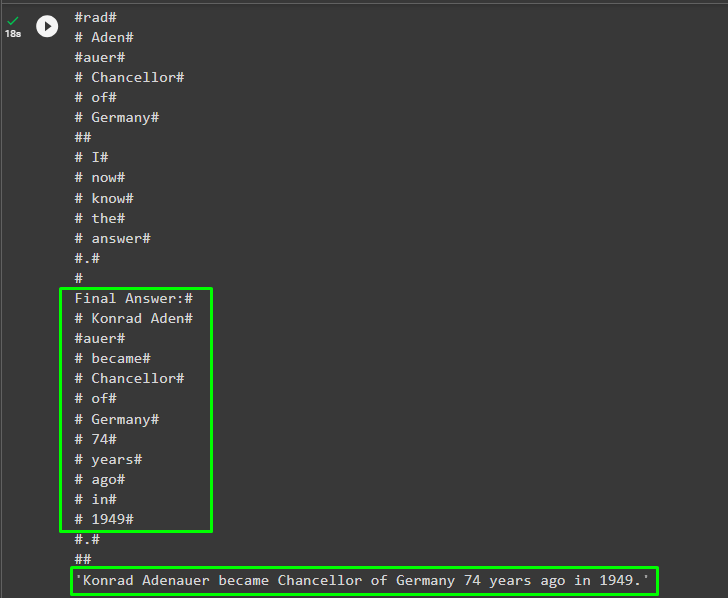
agent.run(
"It's 2023 now so tell me when did Konrad Adenauer become Chancellor of Germany and how many years ago it happened"
)
Output
The following screenshot displays the final output in both formats:
That’s all about the process of streaming the final output of an agent in LangChain.
Conclusion
To stream the final output of an agent in LangChain, install modules like Wikipedia to get the answer to the question from it. Import the libraries from the LangChain dependencies to build the language model and tools for the agent. Initialize the agent with the CallbackHandler() method configured to return the streaming tokens of the final output. This guide has elaborated on the process of streaming the final output of an agent in LangChain.