The DENSE_RANK() function allows us to assign a unique rank to each row within a result set based on the values in one more specified column. It is very similar to the rank() function but with slight differences in how the function handles the duplicate records.
In this tutorial, we will explore how this function works, the provided syntax, and how we can use it in a database.
How It Works
Let us start by explaining how this function works. It is good to keep in mind that the function is high-level, and we cannot explain the underlying implementation.
The function works by assigning a rank to each row in the result set starting from rank 1 and increasing by 1 for each unique value in the columns.
The rows with similar values (duplicates) in the specified columns are assigned with the same rank and the next row with a different value is assigned with the next available rank, without any gaps.
As we mentioned, the function does not leave any gaps where there are duplicate values which makes it different from the rank() function.
A common use of the dense_rank() function is performing the ranking operations. For example, we can use it to find the top N records, etc.
Function Syntax:
The following describes the syntax of the dense_rank() function:
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)
In the given syntax:
- We start with the dense_rank() function itself.
- The OVER clause signals the start of the window function specifications. This defines how the ranking is applied within the result set.
- The PARTITION BY partition_expression is an optional clause that allows us to partition the resulting set into groups or partitions based on one or more columns. The ranking is applied separately on each partition with the rank resetting at a new partition.
- The ORDER BY sort_expression specifies the order in which we wish to use to sort the data in the resulting partitions.
Sample Data
To demonstrate how to use the dense_rank() function, let us start with a table with a sample data. In our case, we use a sample “orders” table as follows:

Example 1: Dense_Rank() Function Usage
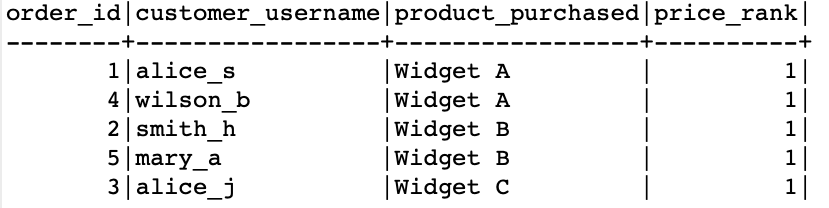
We can use the dense_rank() function to rank the resulting orders based on the price. Consider the following example query:
order_id,
customer_username,
product_purchased,
DENSE_RANK() OVER (
ORDER BY
price DESC
) price_rank
FROM
orders o;
In the given example, we use the dense_rank() function to rank the data based on the price of orders. We omit the PARTITION BY clause as we do not to group the data.
The resulting output is as follows:

Example 2: PARTITION BY
We can also add the PARTITION BY clause to group the data into various segments such as based on the product purchased.
An example query is as follows:
order_id,
customer_username,
product_purchased,
DENSE_RANK() OVER (
partition by product_purchased
ORDER BY
price DESC
) price_rank
FROM
orders o;
This should group the data into various groups based on the resulting groups and apply the rank for the items in each group.
Conclusion
In this post, we learned the fundamentals of using and working with the dense_rank() window function in SQL to assign a rank to the values based on specific columns.