The process of building Large Language Models (LLMs) or chatbots can be done using the LangChain framework as it contains all its libraries. These models need to be trained on the data set written in natural language for the model to understand the prompts and fetch data related to it. Using the select by n-gram method in LangChain gets the similarity index that ranges between 0.0 to 1.0 to get the data.
This post demonstrates the process of using the select by n-gram overlap in LangChain.
How to Use Select by n-gram Overlap in LangChain?
The n-gram method is set on the threshold score at -1.0 by default which means that it selects each example and reorders them according to the prompt. The score changes to 0.0 which means that no example is related to the query/prompt provided by the user so no need to order the data. The score of 1.0 for n-gram means each example in the dataset is somehow related to the query and needs to fetch the most similar one.
To learn the process of using the select by n-gram methods in LangChain, simply go through this easy guide:
Step 1: Install Modules
Firstly, install the LangChain framework with its dependencies required to use the n-gram overlap example selector:
After that, install the OpenAI modules to use its dependencies or libraries to complete the process:
Now, install the FAISS module which can be used to fetch data efficiently from the example set:
The tiktoken tokenizer is used to create small chunks of the data so the fetching can become easier:
Step 2: Importing Libraries and Building Example Set
The next step here is to build the example set for the n-gram overlap after importing the required libraries like NGramOverlapExampleSelector, FewShotPromptTemplate, and many more:
from langchain.prompts.example_selector.ngram_overlap import NGramOverlapExampleSelector
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
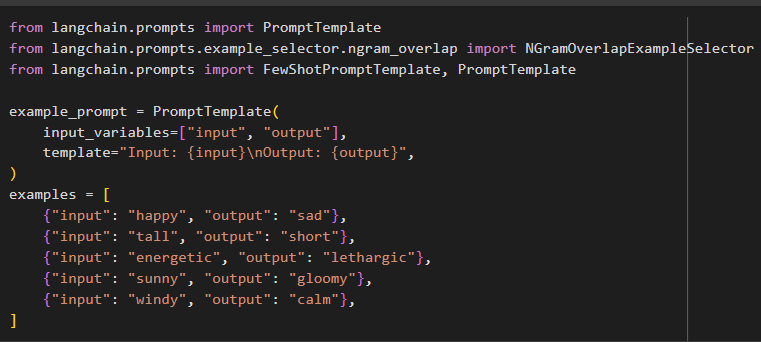
Set the example that contains the language translation inputs that will translate English to the Spanish language:
{"input": "See Spot run", "output": "Ver correr a Spot"},
{"input": "My dog barks", "output": "Mi perro ladra"},
{"input": "Spot can run", "output": "Spot puede correr"},
]
Step 3: Building Example Selector
After configuring the examples, simply build the example selector using the select by n-gram overlap using the NGramOverlapExampleSelector() and FewShotPromptTemplate() methods:
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
example_selector = NGramOverlapExampleSelector(
examples=examples,
example_prompt=example_prompt,
threshold=-1.0,
)
dynamic_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Translate each prompt into Spanish language",
suffix="Input: {sentence}\nOutput:",
input_variables=["sentence"],
)
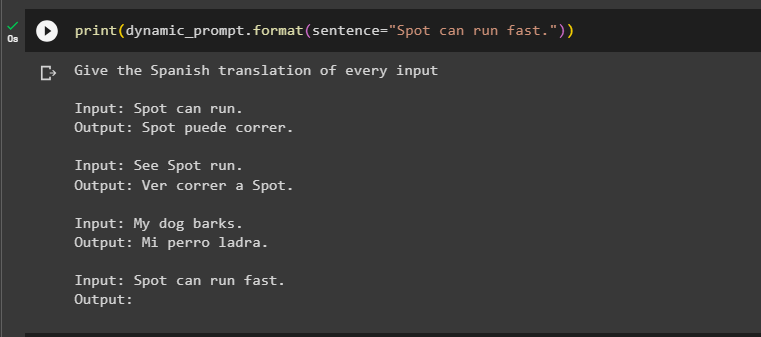
Simply run the dynamic_prompt() method with the input sentence in English to the example set:
This example has the most n-gram overlap or similarity with the “Spot can run” example and least with the “My dog barks” so it sorted them in a similar order:
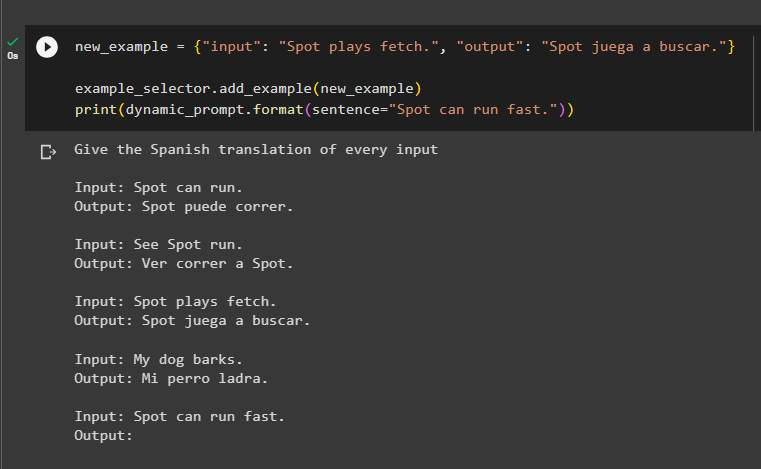
Step 4: Adding Example to the NGramOverlapExampleSelector
Simply add the example using the input and output parameters in the “new_example” variable and then run the query to find the n-gram overlap among the examples:
example_selector.add_example(new_example)
print(dynamic_prompt.format(sentence="Spot can run fast"))
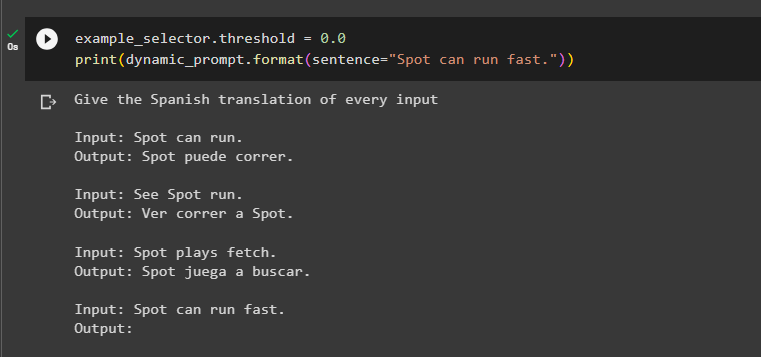
Step 5: Setting Threshold
Set the threshold to 0.0 so the example with no overlap will get excluded from the set as the “My dog barks” is not displayed on the screenshot:
print(dynamic_prompt.format(sentence="Spot can run fast"))
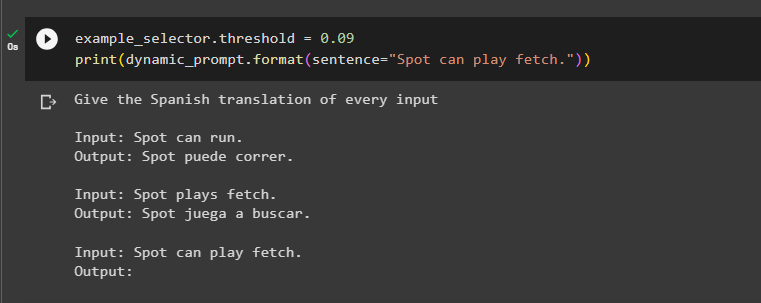
Set the threshold to a small nonzero value to get only related examples:
print(dynamic_prompt.format(sentence="Spot can play fetch"))
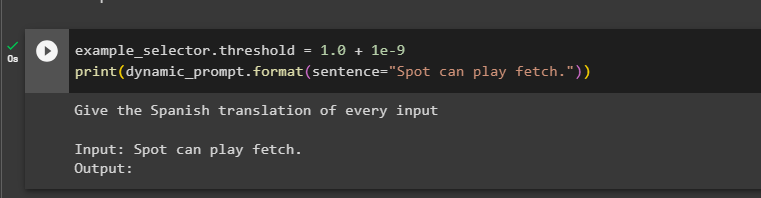
Set the threshold greater than 1.0 and it will fetch only one example that tops the list of similarity or n-gram overlap:
print(dynamic_prompt.format(sentence="Spot can play fetch."))
That is all about using the select by n-gram overlap in LangChain.
Conclusion
To use the select by n-gram overlap in LangChain, simply install the modules and frameworks with dependencies required to complete the process. These modules include LangChain, OpenAI, FAISS, and many more that are used to get the libraries for using the n-gram overlap. The n-gram overlap uses the threshold value to search for the most similar examples from the set and reorders them according to the prompt. This guide has illustrated the process of using the select by n-gram overlap in LangChain.