
In UNIX/Linux, sed is a dedicated command for editing streams. This is where the name of the command comes (stream editor). It takes a stream as input, filters and transforms its content, and outputs the result as instructed.
In this guide, we will have a look at using sed with the regular expressions (regex for short) to replace the contents in a text file. This guide will use the GNU/Linux version of sed.
Grabbing a Sample Text File
For demonstration purposes, we create a simple text file with some text to practice our sed commands. Create a text file using nano:
Inside the file, enter the following text:
echo "the quick brown fox"
echo "jumps over the lazy dog"
Replacing Texts Using Sed
The primary command structure of sed for replacing texts is as follows:
Here:
- -i: The default behavior of sed is to write the output to the STDOUT (standard output). However, this flag tells sed to edit the file(s) in place instead. If an extension is also provided (for example, -i.bak), a backup of the original file is created.
- s: Instructs sed to perform a substitute operation on the given stream.
- /: The delimiter character.
- <search_regex>: A regular expression for sed to match on the given stream.
- <replacement>: The replacement string.
- g: Flag instructing sed to perform a global replacement. By default, sed only matches and replaces the first instance.
Let’s try it out. In the following example, we replace the with THE in the sed-practice.txt:

Verify the changes.
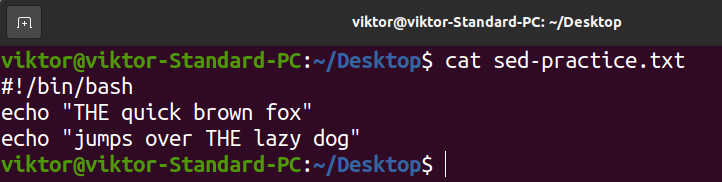
As you can see, we successfully changed the contents of the file.
Working with Delimiter Characters
As described in the previous section, sed instructions come with delimiter characters to separate the various parts. If we want to replace the texts that contain the delimiter character, we have to use the backslash (\) to escape it.
Let’s have a look at the following example:

Here, we replace the /bin/bash with /usr/bin/zsh. Verify if the attempt is successful.

Using this zigzag pattern of the forward and backslashes, it can easily become extremely confusing. That’s why it’s a common practice to use other delimiters such as colon (:) or vertical bar (|). Let’s rewrite the command using vertical bar as the delimiter:


Regex Character Sets
We can use the character sets to describe a set of characters to replace in sed. Here are some common character sets you’ll come across:
- [a-z]: All the lowercase alphabets.
- [A-Z]: All the uppercase alphabets.
- [0-9]: All the digits.
In the following example, we replace all the digits with the alphabet. Have a look at the following example:

Here, sed replaces all the digits (1 and 0, in this case) it finds with the letter k.
What if we want to replace 1 with a and 0 with b? Here’s one way to achieve this:

Here, the first sed command replaces 1 with a. The output is then piped to a second sed command that replaces 0 with b.
Conclusion
In this guide, we briefly demonstrated the various ways of using sed to find and replace the texts. With the help of regex, we were able to fine-tune the search and replace the exact contents. Learn more about sed regex.
With the help of some additional tools like find, we can use sed to even recursively modify the files of an entire directory.
We can also implement sed in the Bash scripts to perform more complex stream editing. Learn more about starting journey with Bash scripting.