
Syntax:
The syntax of the cURL command is as follows:
curl [OPTIONS] [URL]
The options parameter is used to tell the system for what purpose we will be using the command and the URL parameter takes the URL on which we will perform our command.
This command has two options: “-O” and “-o”. “-O” will save the file in the directory in which we will be standing at the time of operation. It will also keep the filename the same.
“-o” allows us to save the file with the name and directory of our choosing.
Example No. 1:
In the following example, we will use the curl command to download the file from the browser. For that, let us first install the curl package in our system. By running the command below in the terminal, we will start the installation of the curl package:
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following NEW packages will be installed:
curl
0 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
Need to get 161 kB of archives.
After this operation, 413 kB of additional disk space will be used.
Get:1 http://pk.archive.ubuntu.com/ubuntu focal-updates/main amd64 curl amd64 7.68.0-1ubuntu2.14 [161 kB]
Fetched 161 kB in 2s (93.2 kB/s)
Selecting previously unselected package curl.
(Reading database ... 188733 files and directories currently installed.)
Preparing to unpack .../curl_7.68.0-1ubuntu2.14_amd64.deb ...
Unpacking curl (7.68.0-1ubuntu2.14) ...
Setting up curl (7.68.0-1ubuntu2.14) ...
Processing triggers for man-dB (2.9.1-1) ...
When we run the command above, it will ask us to enter the password. When we enter the correct password, it will start installing the new version of the curl package as shown above.
For downloading the file from the browser, it is necessary to have a link to that file from where it is going to be downloaded. Let us suppose we have a link to some pdf file and now we want it to be downloaded in our system. For downloading the file, we will run the command below:
In the command above, we passed the flag “-o” which instructs the compiler to rename the file. The second keyword “linux.pdf” is the name of the file which we want to be saved as the new filename in the directory. The last one is the link to the file that we are downloading.
When we run the command above, the output will be displayed on the terminal like the example below, which it will display the downloading details of the file.
Dload Upload Total Spent Left Speed
100 1562k 100 1562k 0 0 553k 0 0:00:02 0:00:02 --:--:-- 553k
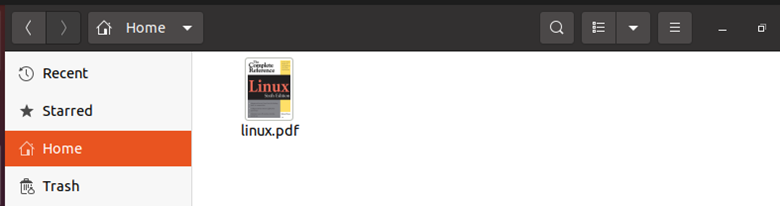
Now, we want to make sure that the file is downloaded or not. For that, we will go to our home directory as can be seen in the snippet below. The file with the file name “linux.pdf” has been downloaded successfully.
Example No. 2:
In this example, we will use the link of the same file that we have downloaded in example no 1. But this time, we will download the file with its original name. For that, we will run the command below:
One thing to notice in the command is that this time we have not included any flag or the name of the file to it which indicates that we are trying to save the file with its original name. After running the command above, the output shown below will be displayed on the terminal.
Dload Upload Total Spent Left Speed
100 9127k 100 9127k 0 0 1067k 0 0:00:08 0:00:08 --:--:-- 1132k
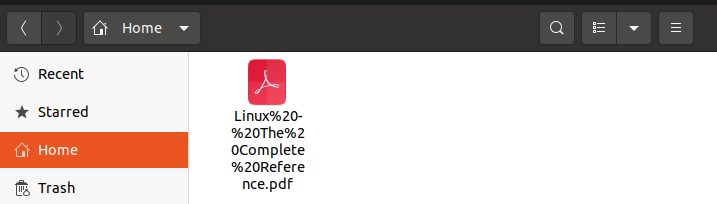
For checking whether the file is saved with the original file name or not we will check the home directory where the file will be stored. As can be seen below snippet,v the file is saved this time with its original name.
Example No. 3:
In this example, we will try to download multiple files using a single command and we will rename them according to our desire. So, we will try to download three files at a time with different names.
-o linux1.pdf
-o linux2.pdf
-o linux3.pdf
In the command above, we passed the same link three times to check whether it will download them multiple times for us or not. After passing the link using the flag “-o”, we renamed the files as “linux1.pdf”, “linux2.pdf” and “linux3.pdf”. The flag “-o” will be used each time while naming the files. When the command above is executed, it will display the following output in the terminal which shows the downloading details of all three files as shown below.
Dload Upload Total Spent Left Speed
100 9127k 100 9127k 0 0 950k 0 0:00:09 0:00:09 --:--:-- 1184k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 9127k 100 9127k 0 0 1133k 0 0:00:08 0:00:08 --:--:-- 1209k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 9127k 100 9127k 0 0 975k 0 0:00:09 0:00:09 --:--:-- 1088k
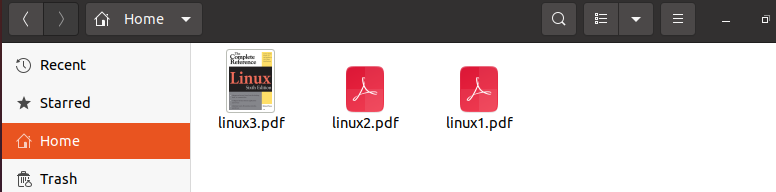
Now, let us check for all three files. For that, we will move to our home directory where all the files are downloaded as we can see below, the snippet all the files are successfully downloaded.
Conclusion
We have briefly studied the concept of the curl command and how it is used to download files from the browser just using a specified link of the file. Then, we discussed the basic syntax for the curl command and implemented different examples to make it easy to learn. You can also try more examples for a better idea of how it can be used to download files.