AWS allows us to create batch operations for our S3 buckets to process data on a large scale. It also manages and tracks the batch operation tasks and keeps the reports having details about the job completion. Things are much easier to manage as this is a serverless service by AWS. Let’s look at how to create a batch operation job for our S3 bucket.
Creating S3 Batch Operation Using Console
Now, we will see how to create an S3 batch operation job. So, log in to your AWS account and create an S3 bucket.
To create a batch operation job, we require a manifest file of the data we need to manage using that job. To generate the manifest, go to the Management section in your S3 bucket using the top menu bar.
In the Management section, drag down to the Inventory configurations and click Create inventory configurations.
In the Create section, you need to give a name for your Inventory configuration.
Then, you need to select the destination path where you want to store your inventory reports. You also have to attach the policy to grant permission to put data in the S3 bucket.
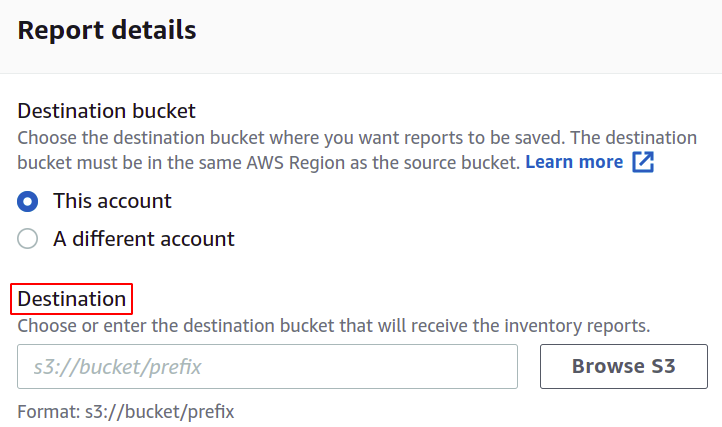
You can also change the format of the manifest file if you want. Here, we are going with CSV as we wish to utilize this in a batch operation.
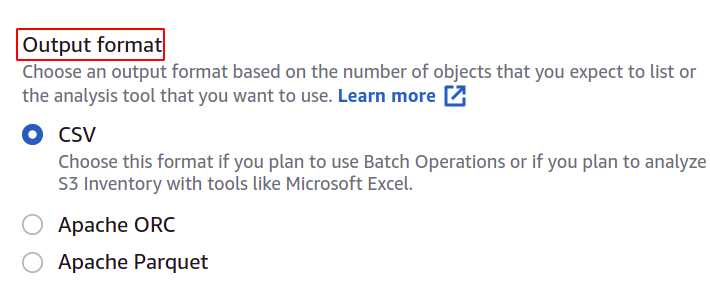
The user can specify what kind of information he wants in his manifest report and regarding which objects. AWS provides multiple options, such as object type, storage class, data integrity, and object lock.
Now, simply click on the Create button in the button right corner, and you will get your inventory configuration for your S3 bucket. The manifest report will be generated in 48 hours and stored in the destination bucket.
Next, we are going to create an S3 batch job. Simply click on batch operations in the right menu panel on the S3 section to open the batch operation console.
Here, we have to create a specific job for a particular task that we want to perform on our objects in the S3 bucket. So, click on Create job to start building your first S3 batch operation job.
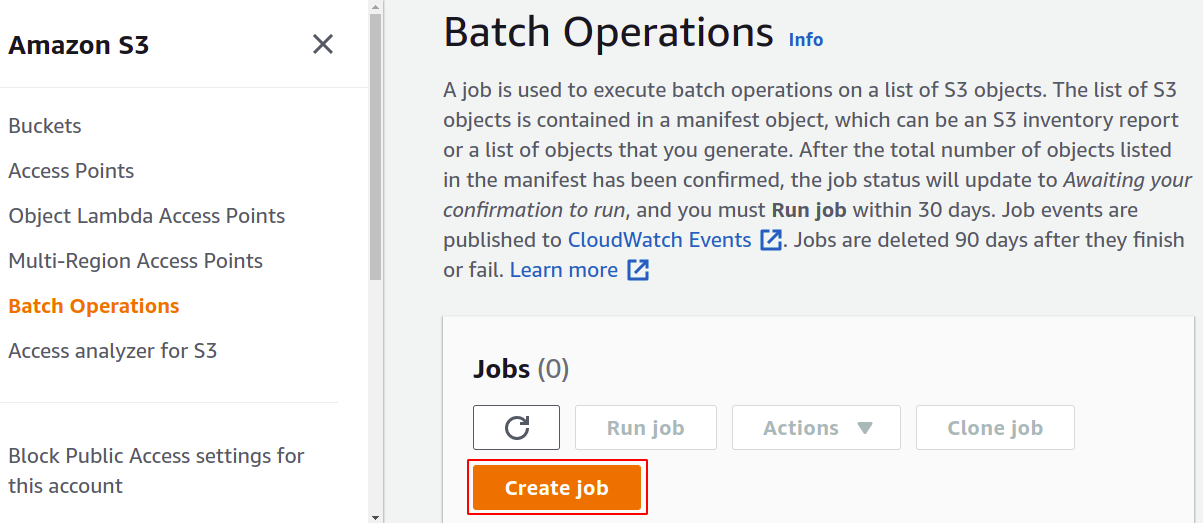
For job creation, we first need a manifest that provides the details about the objects stored in the bucket. You can create a manifest in JSON or CSV from the Management section in your S3 bucket, but that will take some time to generate the report. So we click Create manifest using S3 replication configuration.
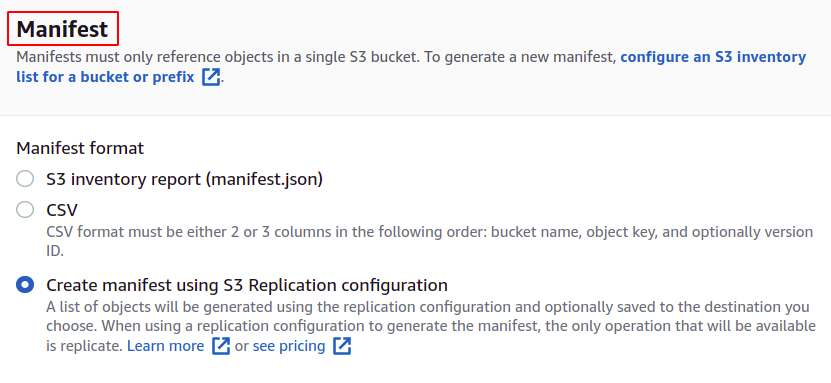
Choose the source bucket for which you are going to create this job. The bucket can also belong to some other AWS account.
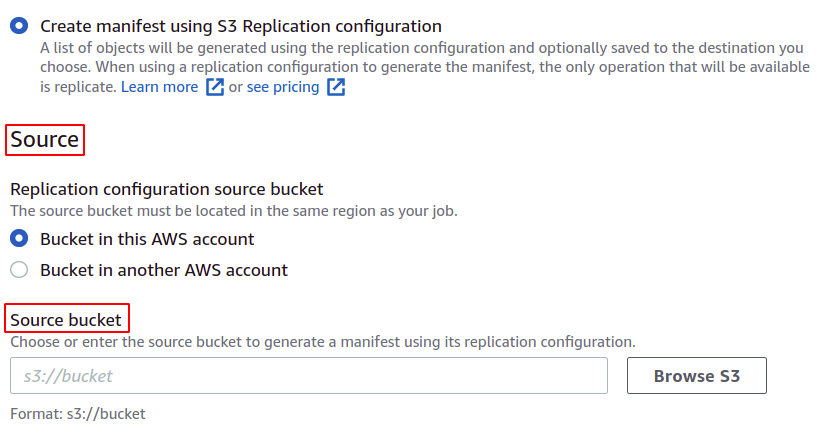
You can also save the manifest, which will be finally created for this batch operation. You have to provide the destination where it will be saved.
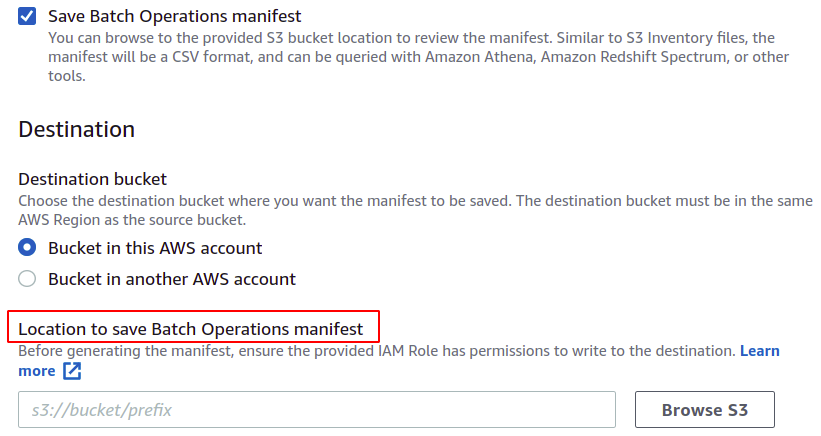
Now, we can choose the operation which we want our batch operation to perform. AWS provides multiple operations like copy objects, invoke lambda functions, delete tags, and many others. However, a manifest created using the S3 replication configuration only allows replication operation.
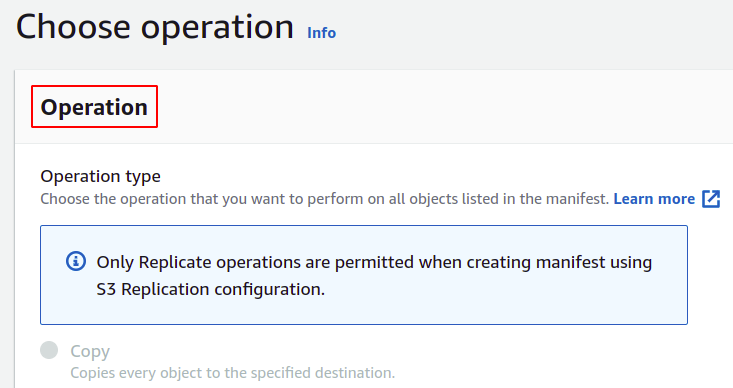
Next, you can provide the batch operation description and define the priority level based on numbers; high value means higher priority.
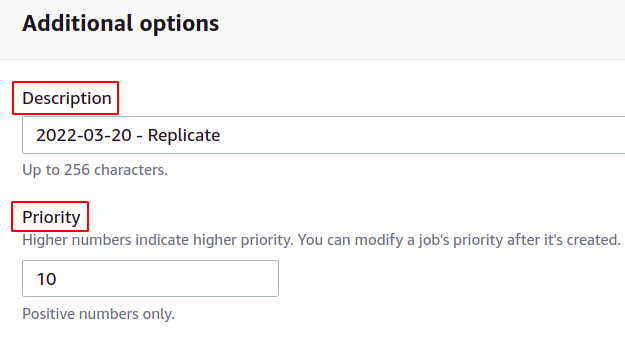
If you want to get a job completion report, check the Generate completion report option and provide the location where it will be stored.
For permissions, you need to have an IAM role with an S3 batch operations policy which you can easily create for batch operations in the IAM section.
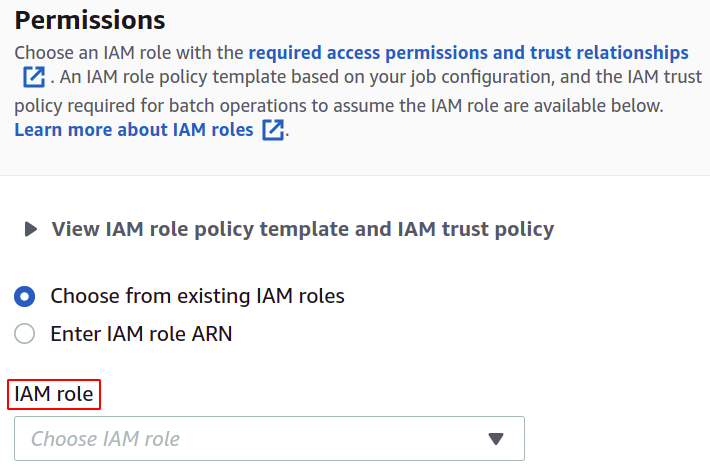
Finally, review all the settings and click on Create job to complete the process.
Once created, it will appear in the Jobs section. It may take some time to be ready based on the operations you have selected for the job. After that, you can run it as you want.
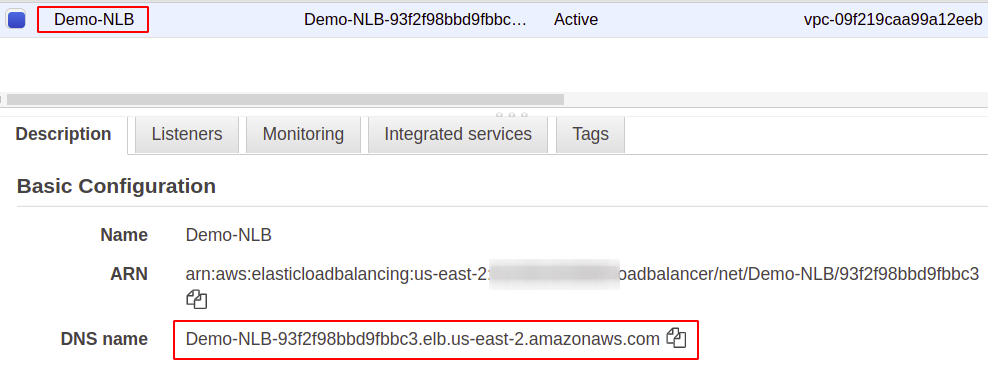
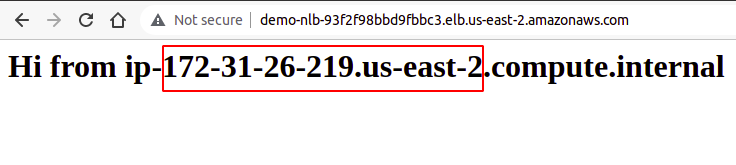
So, we have successfully created an S3 batch operation job using the AWS console.
Creating S3 Batch Operation Using CLI
Now, let us see how to configure an S3 batch operation job using the AWS command-line interface. For that, configure the AWS CLI credentials on your machine. Visit the following blog to configure the AWS CLI credentials.
https://linuxhint.com/configure-aws-cli-credentials/
After configuring the AWS CLI credentials, create an S3 bucket using the following command in the terminal:
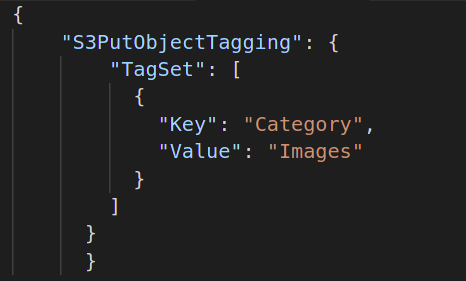
Then, you need to create the batch operation you want to perform on your objects. So, create a JSON document, define the operation you want, and provide the required attributes of the said operation. Following is an example of S3 object tagging operation:
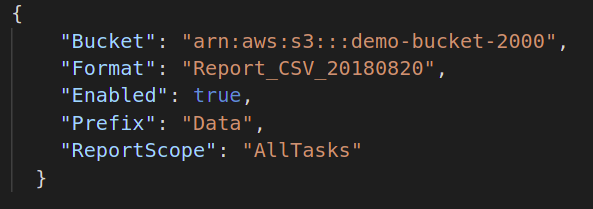
Next, if you want to generate the completion report of your batch job, you must provide the destination to store that report file. The default JSON format for this is as follows:
"Bucket": "",
"Format": "Report_CSV_20180820",
"Enabled": true | false,
"Prefix": "",
"ReportScope": "AllTasks | FailedTasksOnly"
}
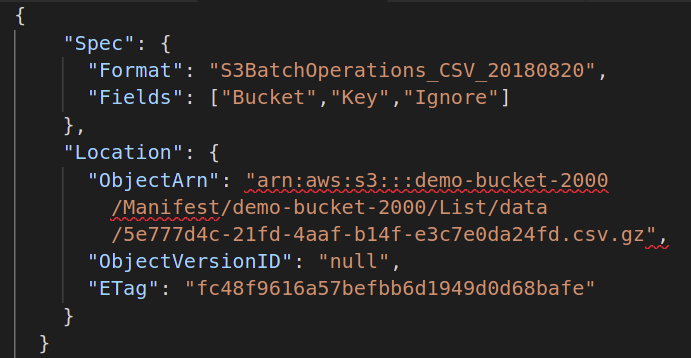
Then, you need to provide the manifest file containing the metadata of all the objects stored in your S3 bucket on which you want to perform the batch operation. You have to create another JSON file with the following attributes:
"Spec": {
"Format":"S3BatchOperations_CSV_20180820"
"Fields": ["Bucket","Key"]
},
"Location": {
"ObjectArn": " ",
"ObjectVersionId": "",
"ETag": ""
}
}
Finally, we can create our batch operation using the following command:
--account-id <User AWS account ID>
--confirmation-required
--operation file:<Batch Operation configuration file.json>
--report file://<completion report destination path.json>
--manifest file://<manifest file location configurations.json --priority <priority value>
--role-arn <S3 batch operation role ARN>

So, we have successfully created a batch operation job using AWS CLI.
Conclusion:
The S3 batch operation is a very helpful tool to use when you want to manage a large number of objects. Batch jobs might often be difficult and complex to set up for the first time. But they can easily reduce your effort, cost, and time. They are used to run complex algorithms, repetitive tasks, table joins in SQL databases, invoke a lambda function, and call a rest API. You just need to provide the list of objects in your S3 bucket on which you want to perform the task, and the process will be performed each time the batch operation is triggered. Common examples of batch operations include S3 object tagging, retrieving specific data from the S3 glacier, transferring data from one S3 bucket to another, generating bank statements, processing analytical reports and forecasts, order fulfillment notifications, and email synchronization system. We hope you found this article helpful. Check the other Linux Hint articles for more tips and tutorials.