In this guide, I will explore how to remove duplicate lines from a file with and without sorting using various approaches in the Vim editor.
- Use Vim to Remove Duplicate Lines
- Remove Duplicate Lines in Vim using the sort Command
- Remove Duplicate Lines in Vim using the uniq Command
- Remove Duplicate Lines in Vim using the awk Command
- Remove Duplicate Lines in Vim using the perl Command
- Conclusion
Use Vim to Remove Duplicate Lines
In Vim there can be different approaches to do the same task, for example, a task like finding and deleting duplicate lines from a file also has various ways. Let’s learn about these methods.
For this tutorial, I have created a CSV file which has the content shown below:
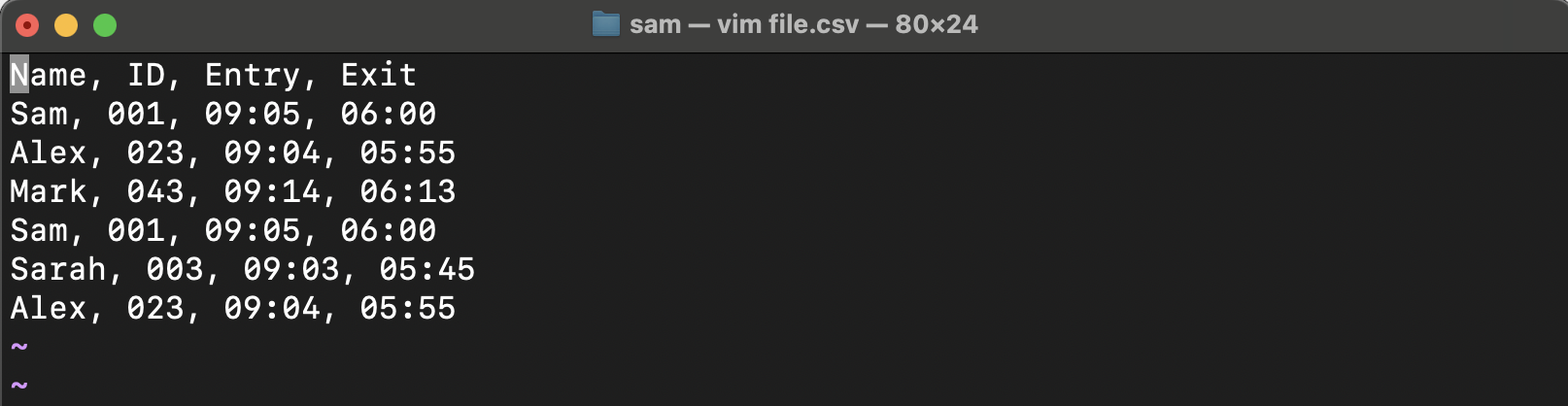
Remove Duplicate Lines in Vim using the sort Command
To remove the duplicate lines from a file in Vim the quickest approach is to use the sort command with u option together.
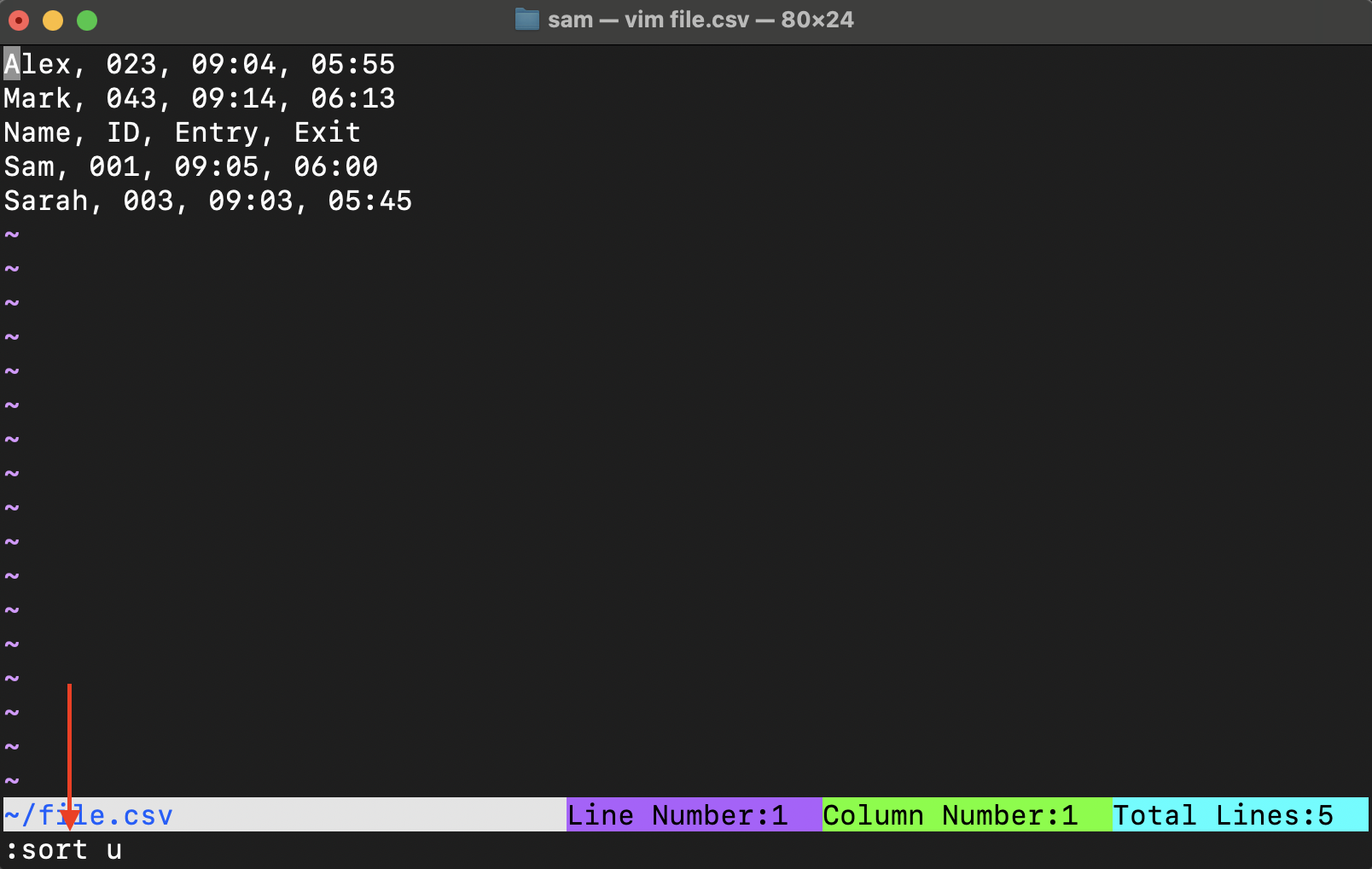
The sort command sorts the file while the u option stands for unique which only keeps the first line if there are multiple duplicates.
As can be seen, 2 duplicate lines have been removed, but the entries of the file have also been altered due to the default sort operation. Clearly, this is not the result that you want unless sorting is acceptable.
Limitation
This method however has a limitation. Though it is removing the duplicate lines from the file it is also sorting the entries which can be unnecessary or unwanted. To avoid sorting and only removing the duplicate lines there are alternative methods.
Need more help regarding the sort command in Vim, use the help command:
Remove Duplicate Lines in Vim using the uniq Command
Duplicate lines can also be removed using the uniq command which filters the repeated lines. Removing adjacent repeated lines can be a tricky task and I would advise you to avoid the method unless you require to remove the adjacent repeated lines.
The uniq command will not remove anything from the following file:

Because the repeated entries are not adjacent, see lines 2 & 5 or 3 & 7. The uniq command will remove the second and subsequent lines of the adjacent similar entries.
Let’s modify the file:

Now, get into VISUAL LINE mode by pressing the shift+v and selecting all the lines.

Now, use the !uniq command and hit return:

As it can be seen that the repeated lines have been deleted from the file, press :w command to save the file.
Remove Duplicate Lines in Vim using the awk Command
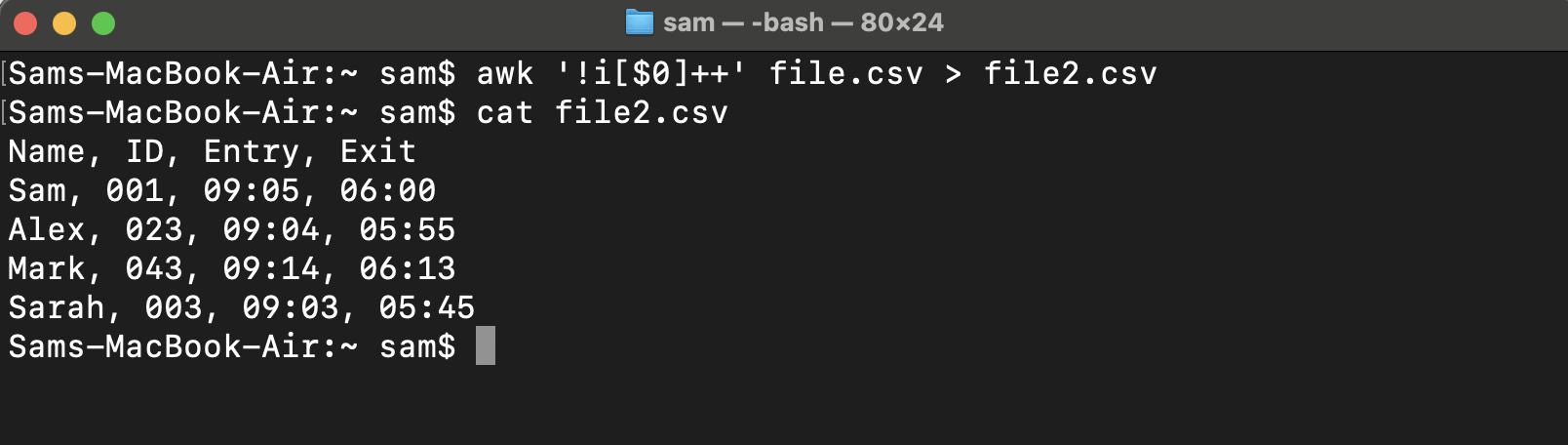
If you want to remove the duplicate lines without sorting the file entries then use the awk command the following way:
In the above command:
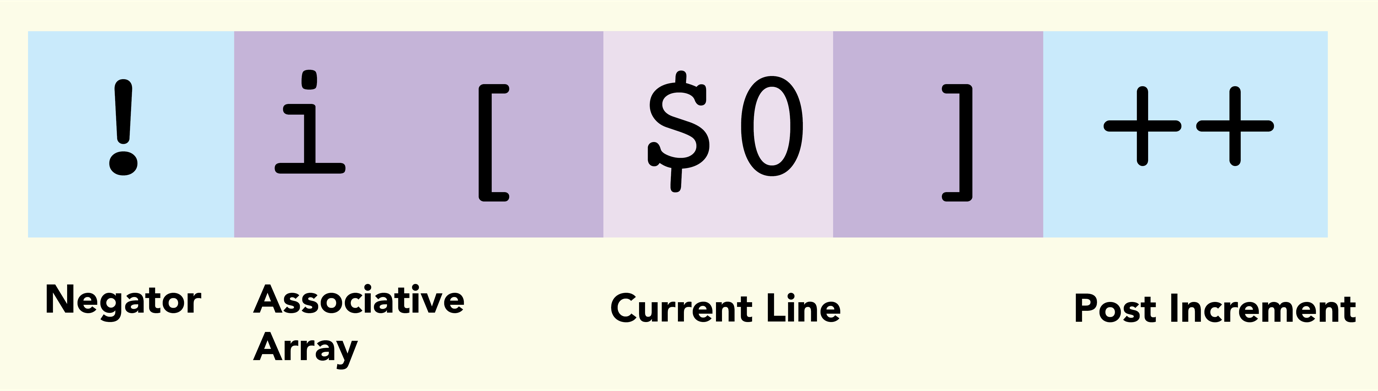
| ! | Negator |
| $0 | Indicates the current line. Similarly, $1 means the first argument separated by space, and $2 means the second |
| i | The variable name of an associative array, it can be any name, a, b, x, or y |
| ++ | Increment operator |

The duplicate lines have been deleted the file is in the same form. Now, let’s find out how this one-liner is functioning to give us such an output.
The awk in the above command is processing the file the following way:
if the line is not processed before
then print it
store the line that is processed before
The true pattern in the awk command will perform the default print operation. Our objective is to print the unique lines and eliminate the duplicates.
To grasp the concept of this awk one-liner, you must understand the associative array. An associative array is an array that holds a set of key-value pairs, where values are accessed by using the unique string keys instead of integers.

Please note that the key value will always be unique, it cannot be duplicated.
Let’s understand how the above awk command is working.
Firstly, keep the increment (++) part aside and learn the following expression:
Here, i[$0] is taking the current line as an associative array element or key.
The i[$0] returns the false if the value is unique and the increment operator (++) adds the current value to 1.
The ! operator negates the return value of the above expression (false) and returns the true. If the operation is true the awk command will perform the default operation and print the current key.
The bottom line is that the awk command will implicitly loop through all the lines of the file and create an associative array. It will return false if the line is not in the array already and true otherwise. The negator will negate the false to true and awk will perform its default operation and print the line.
This command will only print the value to the terminal and in order to save the output the redirection operator will be used:
Remove Duplicate Lines in Vim using the perl Command
The similar operation that I mentioned above can also be performed using the perl command which is developed for text manipulation.
This command also creates an associative array and loops through all the file values implicitly.
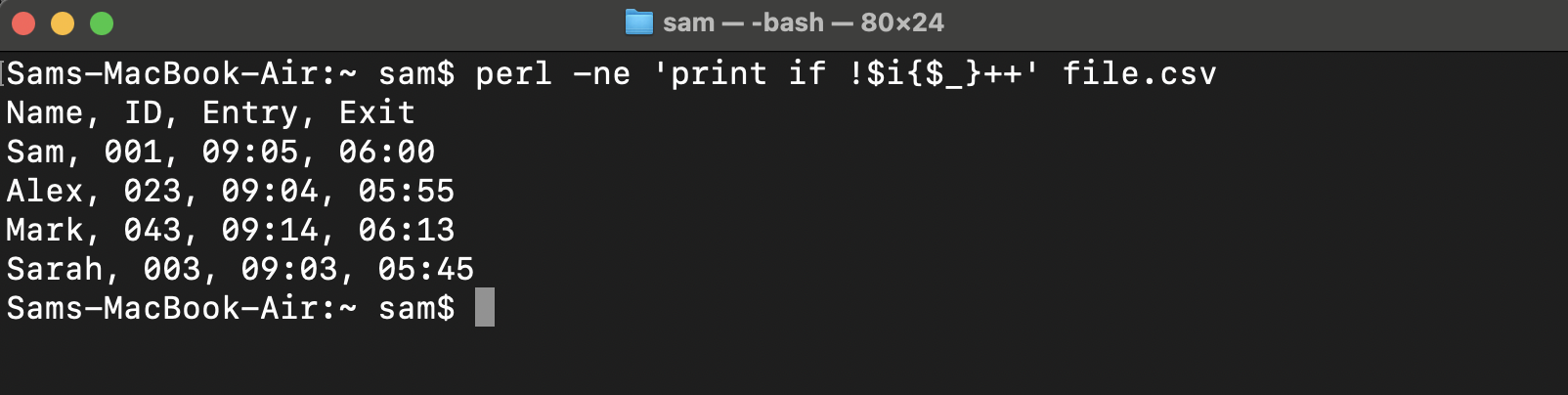
The $_ is a special Perl variable that contains the default input and is also known as it or topic. The n flag is used to ask Perl to loop using the given instruction and the e flag indicates a short Perl program executing in the command line.
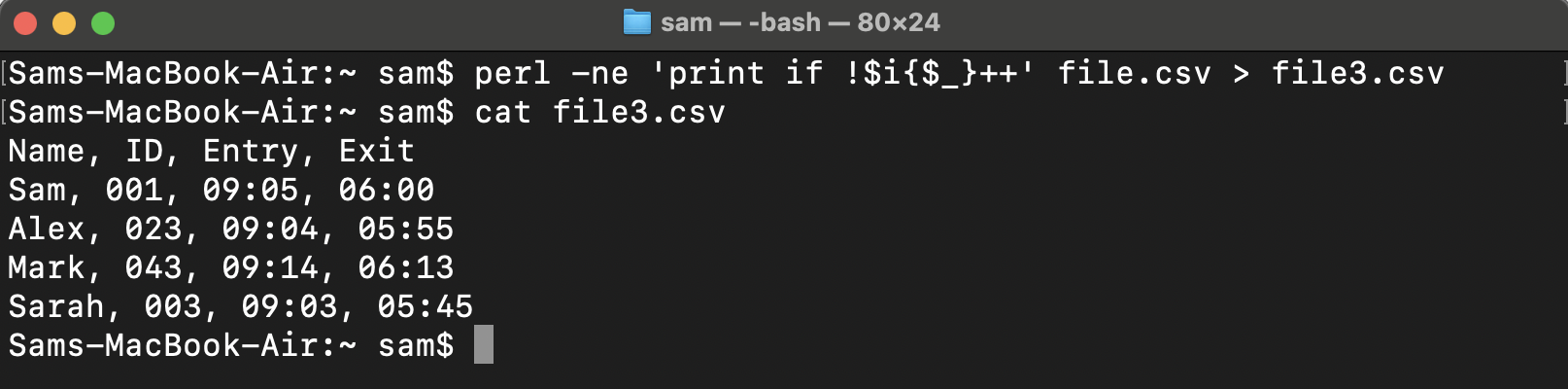
To save the modifications in the same file use -i flag.
Or use the redirection operator to save the modified version to a separate file.
Conclusion
Vim because of its vast functionalities can be an incredibly useful editor to edit and manage files with a lot of data. It provides all the operations to create and edit any type of file right in the terminal window.
Effective data management is a crucial process for precisely organizing and managing data. Removing the duplicate lines is a common task that you would prefer to perform when managing the data. The duplicate lines can be removed using the sort u command where the u option is for unique. However, before removing the duplicates it sorts the list. Other methods like using awk, perl, or regex can achieve removing duplicate lines from a file without sorting it. In my opinion, awk is the best method to remove duplicate lines from any sort of file.