As its name defines, this function is used to aggregate the list. Or in more simple words, it is used to concatenate entries of different rows in a table to form a string. Surely this is difficult to digest theoretically so we will guide you more about it using certain examples. But first let’s jump into its syntax and explore more about it.
Syntax to use the LISTAGG function
The LISTAGG function in Redshift can be used by following the given syntax.
The above syntax shows the required attributes for using the LISTAGG function.
- Column Name: The column in the Redshift table on which you are going to use this function.
- Delimiter: This is simply the list separator you want to use. In most cases comma (,) or semicolon (;) is used as a delimiter. This is optional to mention and by default its value is NULL.
- Order List: This is used to define how you want to sort the values.
- Table Name: This is just the database table on which you are working all this.
Using the LISTAGG function
In this section, we are going to show you some practical use cases and examples to explain briefly how the LISTAGG function in Redshift can be used to get the desired result.
Use-Case 1
First, we are going to take the simplest example to show you how the LISTAGG function in Redshift works. Suppose you have a database table named it_team having a single column for the names of people working in that department.

Now, you simply want to present all the names in a single string form separated by commas. For this purpose, you will be using the LISTAGG function in the following manner.
In the output, you will get all the values from the column name in a single row in the form of a string.

So, you can see how easy it is to use the LISTAGG function and concatenate the rows of a table in Redshift.
Use-Case 2
Take a case where you want to find out all the team leaders working on different projects in your organization. What you have is a table named dev_team which shows all the projects and team leaders in different columns.
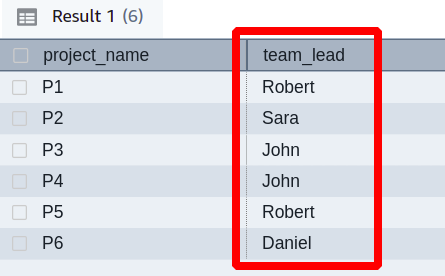
Now, there are few cases where a single person is working as the team leader for more than one project but you just want to take each name only once. For this purpose, we need to use the DISTINCT option available with the LISTAGG function to ignore the repeated values.
from organization.dev_team
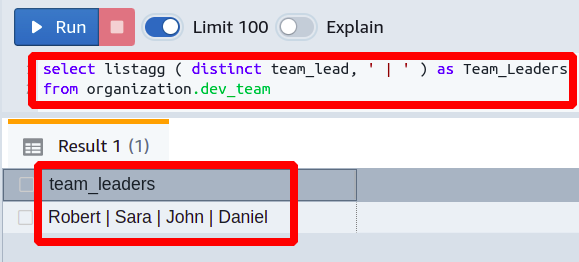
You can see that in the output we have got all our team leaders and also there is no duplication of names as we have used the DISTINCT option. Furthermore, you can see that the name of the output column is changed to team_leaders. Instead of the default column name to improve the understanding of the data. The delimiter used here is a pipe symbol to separate the names of the leads.
Use-Case 3
Suppose your senior has assigned you a task to find out the projects under each team leader and present them in a single string. Let’s again consider the dev_team table.
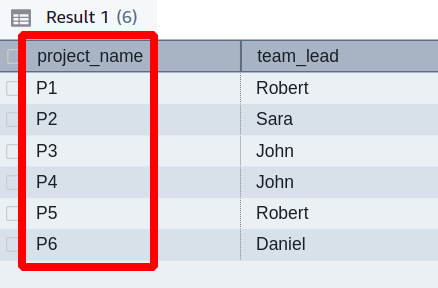
For a one-to-one relationship between projects and team leaders, this task would be simple. In this case, it can be seen that there is even more than one project under some team leaders. For this, you need to create a new Redshift query as shown below.
listagg(project_name, ', ') as Projects
from organization.dev_team
group by team_lead
In this query, the aggregate function is applied to the project_name column. It also has one more parameter used to group the output of the function to the team_lead column.
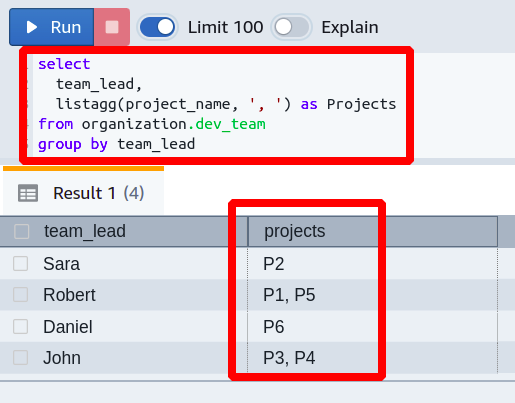
You can see that our required target is achieved and how efficiently it has arranged everything excellently. From this, you can easily see which team leader is handling which projects in your organization.
Use-Case 4
In all the previous examples, we are just concatenating the rows from a single column of the table. But now in this example, you will see that we can even form a single string from values of multiple rows and different columns.
Suppose while working in the sales department of a large firm, you are assigned a task to analyze the details of your clients and all the projects given by each client with the completion time of the projects. All this data is present in a single database table named project_details having three columns.
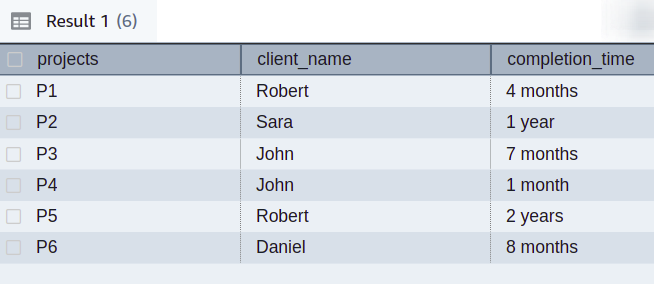
Let’s create a query to achieve the desired output utilizing the Redshift LISTAGG function. You will be using the following query for this to get the desired output:
client_name,
listagg(projects || 'will complete in' || completion_time, ' , ')
within group (order by client_name)
from organization.project_details
group by client_name
The LISTAGG function is applied on two columns projects and completion_time using the double pipe symbol. In one place, we have used the expression will complete in as a delimiter and comma for the other position. The output is ordered in ascending alphabetical order with respect to the client_name column. The output from the above Redshift query will be as follows:
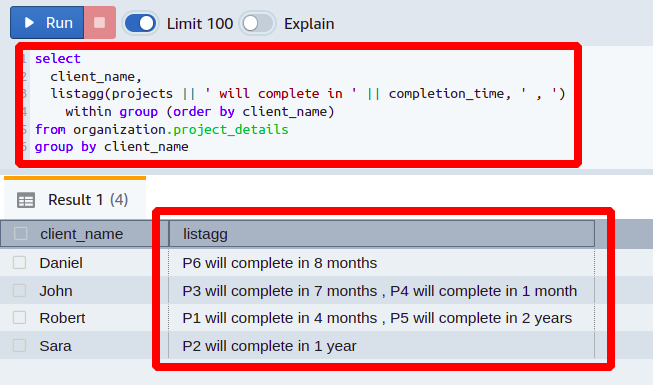
Now, you can see that we have got our results. It shows each project with its time duration and the client to whom it belongs.
Conclusion
The Redshift LISTAGG function is very helpful if you want to represent the data from multiple rows of a column in a single row. The function
About the author
Zain Abideen
A DevOps Engineer with expertise in provisioning and managing servers on AWS and Software delivery lifecycle (SDLC) automation. I'm from Gujranwala, Pakistan and currently working as a DevOps engineer.