When working with or developing applications involving databases, we always have a limited amount of memory and try to utilize the least amount of disk space. Although we know that there is no memory limitation on cloud services, we still have to pay for the amount of space we consume. So, have you ever thought of checking how much disk your database tables occupy? If not, then you don’t need to worry because you are at the right place.
In this article, we will learn how to get the table size in Amazon Redshift.
How Do We Do That?
When a new database is created in Redshift, it automatically creates some tables and views in the background where all the necessary information about the database is logged. These include STV views and logs, SVCS, SVL, and SVV views. Although there are a whole bunch of things and information in them that are out of scope for this article, here we will just explore a bit about SVV views.
SVV views contain the system views which have reference to STV tables. There is a table named SVV_TABLE_INFO where Redshift stores the table size. You can query data from these tables just like normal database tables. Just remember that SVV_TABLE_INFO will return informational data only for the non-empty tables.
Superuser Permissions
As you know, database system tables and views contain very critical information that needs to be kept private, so that is why the SVV_TABLE_INFO is not available for all database users. Only the superusers can access this info. Before getting the table size from this, you must get the permissions and rights of the superuser or admin. To create a superuser in your Redshift database, you simply need to use the keyword CREATE USER when you create a new user.
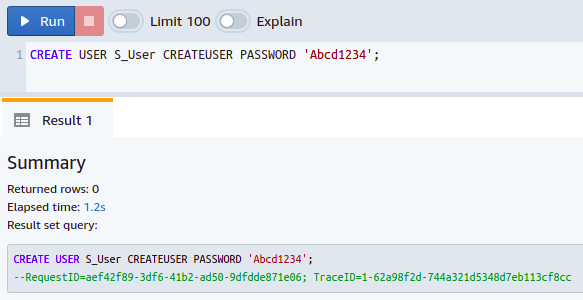
So, you have successfully created a superuser in your database
Redshift Table Size
Suppose your team leader assigned you a task to look at the sizes of all your database tables in Amazon Redshift. To carry out this job, you will use the following query.
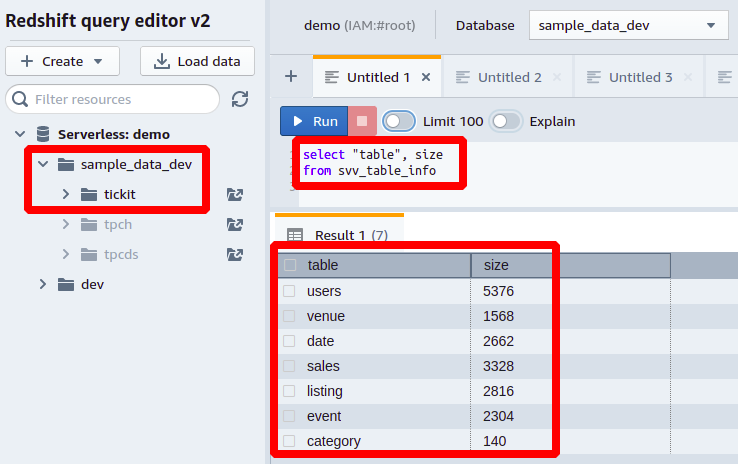
So, we need to query two columns from the table named SVV_TABLE_INFO. The column named table contains the names of all the tables present in that database schema, and the column named size stores the size of each database table in MBs.
Let’s try this Redshift query on the sample database provided with the Redshift. Here, we have a schema named tickit and several tables with a large amount of data. As shown in the following screenshot, we have seven tables here, and the size of each table in MBs is mentioned in front of each one:
Other information you can get regarding the table size from the svv_table_info can be the total number of rows in a table, which you can get from the tbl_rows column, and the percentage of total memory consumed by each table of the database from the pct_used column.
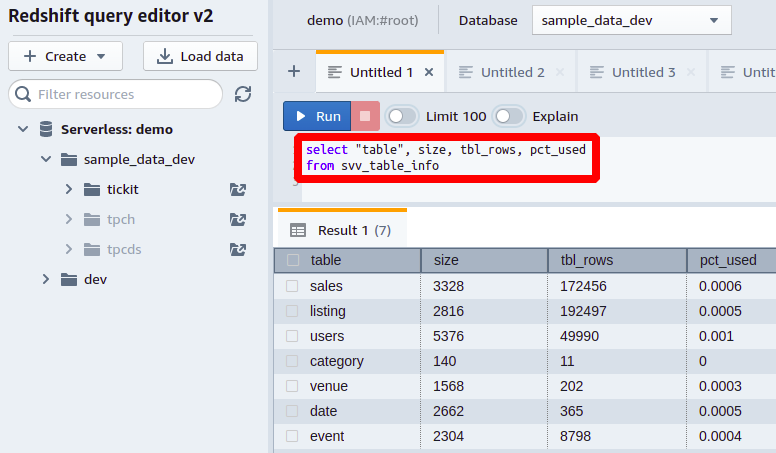
This way, you can view all the columns and their space occupied in your database.
Modify Column Names for Presentation
To represent the data in a more sophisticated way, we can also rename the columns of svv_table_info as we want. You will see how to do this in the following example:
size as size_in_MBs,
tbl_rows as No_of_Rows
from svv_table_info
Here, each column is represented with a different name than its original name.
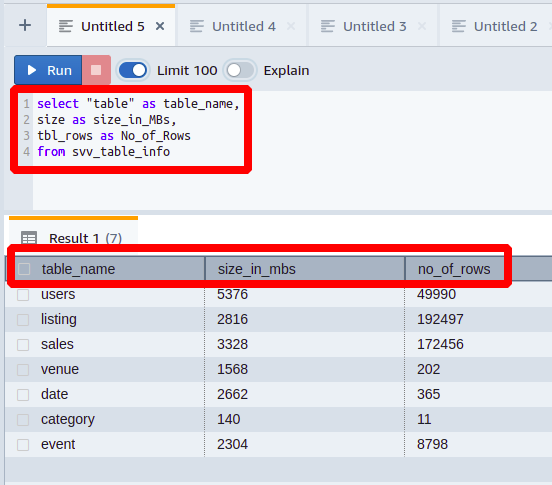
In this way, you can make things more understandable for someone with less knowledge and experience with databases.
Find Tables Larger Than the Specified Size
If you are working in a big IT firm and are given a job to find out how many tables in your database are larger than 3000 MBs. For this, you need to write the following query:
from svv_table_info
where size > 3000
You can see here that we have put a greater than condition on the size column.
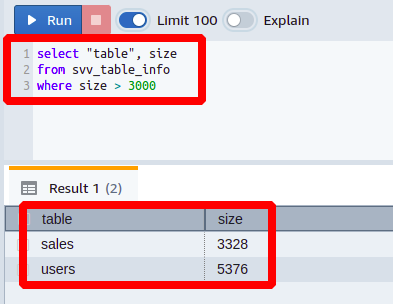
It can be seen that we just got those columns in the output that were larger than our set limit value. Similarly, you can generate many other queries by applying conditions on different columns of the table svv_table_info.
Conclusion
So here, you have seen how to find the table size and number of rows in a table in Amazon Redshift. It is useful when you want to determine the burden on your database and will provide an estimate if you are running out of memory, disk space, or computing power. Other than the table size, other information is available that can help you design a more efficient and productive database for your application.