Redshift APPROXIMATE PERCENTILE_DISC function performs its calculation based on the quantile summary algorithm. It will approximate the percentile of the given input expressions in order by parameter. A quantile summary algorithm is widely used to deal with big datasets. It returns the value of the rows that have a small cumulative distributive value that is equal or greater than the provided percentile value.
Redshift APPROXIMATE PERCENTILE_DISC function is one of the compute-only node functions in Redshift. Therefore, the query for approximate percentile returns the error if the query does not refer to the user-defined table or AWS Redshift system-defined tables.
The DISTINCT parameter is not supported in the APPROXIMATE PERCENTILE_DISC function and the function always applies to all the values passed to the function even if there are repeating values. Also, the NULL values are ignored during the calculation.
Syntax to use the APPROXIMATE PERCENTILE_DISC function
The syntax to use the Redshift APPROXIMATE PERCENTILE_DISC function is as follows:
WITHIN GROUP (<ORDER BY expression>)
FROM TABLE_NAME
Percentile
The percentile parameter in the above query is the percentile value that you desire to find. It should be numeric constant and it ranges from 0 to 1. Therefore, if you want to find the 50th percentile, you will put 0.5.
Order by expression
The Order by expression is used to provide the order in which you want to order the values and then calculate the percentile.
Examples to use the APPROXIMATE PERCENTILE_DISC function
Now in this section, let’s take a few examples to fully understand how the APPROXIMATE PERCENTILE_DISC function in Redshift works.
In the first example, we will apply the APPROXIMATE PERCENTILE_DISC function on a table named approximation as shown below. The following Redshift table contains the user id and marks obtained by the user.
| ID | Marks |
| 0 | 10 |
| 1 | 10 |
| 2 | 90 |
| 3 | 40 |
| 4 | 40 |
| 5 | 10 |
| 6 | 20 |
| 7 | 30 |
| 8 | 20 |
| 9 | 25 |
Apply the 25th percentile on the column marks of the approximation table which will be ordered by ID.
within group (order by ID)
from approximation
group by marks
The 25th percentile of the marks column of the approximation table will be as follows:
| Marks | Percentile_disc |
| 10 | 0 |
| 90 | 2 |
| 40 | 3 |
| 20 | 6 |
| 25 | 9 |
| 30 | 10 |
Now, let’s apply the 50th percentile to the above table. For that, use the following query:
within group (order by ID)
from approximation
group by marks
The 50th percentile of the marks column of the approximation table will be as follows:
| Marks | Percentile_disc |
| 10 | 1 |
| 90 | 2 |
| 40 | 3 |
| 20 | 6 |
| 25 | 9 |
| 30 | 10 |
Now, let’s try to apply for the 90th percentile on the same dataset. For that, use the following query:
within group (order by ID)
from approximation
group by marks
The 90th percentile of the marks column of the approximation table will be as follows:
| Marks | Percentile_disc |
| 10 | 7 |
| 90 | 2 |
| 40 | 4 |
| 20 | 8 |
| 25 | 9 |
| 30 | 10 |
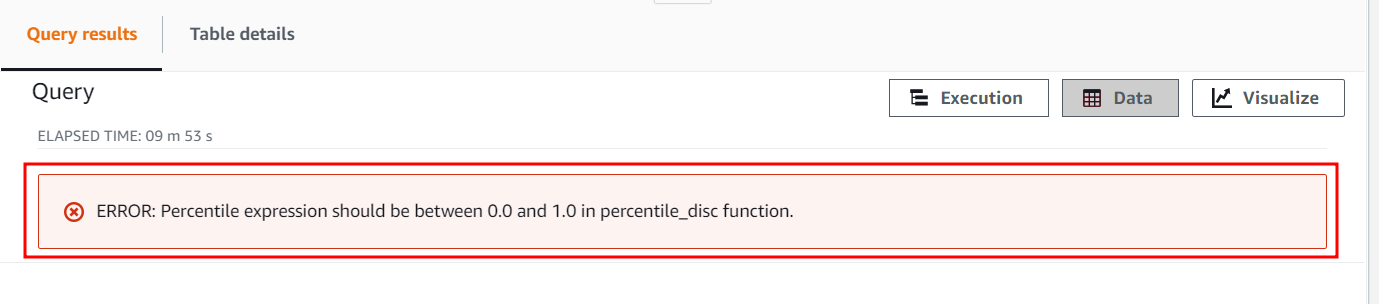
The numeric constant of percentile parameter cannot exceed 1. Now, let’s try to exceed its value and set it to 2 to see how the APPROXIMATE PERCENTILE_DISC function treats this constant. Use the following query:
within group (order by ID)
from approximation
group by marks
This query will throw the following error showing that the percentile numeric constant ranges from 0 to 1 only.
Applying APPROXIMATE PERCENTILE_DISC function on NULL values
In this example, we will apply approximate percentile_disc function on a table named approximation which includes the NULL values as shown below:
| Alpha | beta |
| 0 | 0 |
| 0 | 10 |
| 1 | 20 |
| 1 | 90 |
| 1 | 40 |
| 2 | 10 |
| 2 | 20 |
| 2 | 75 |
| 2 | 20 |
| 3 | 25 |
| NULL | 40 |
Now, let’s apply for the 25th percentile on this table. For that, use the following query:
within group (order by beta)
from approximation
group by alpha
order by alpha;
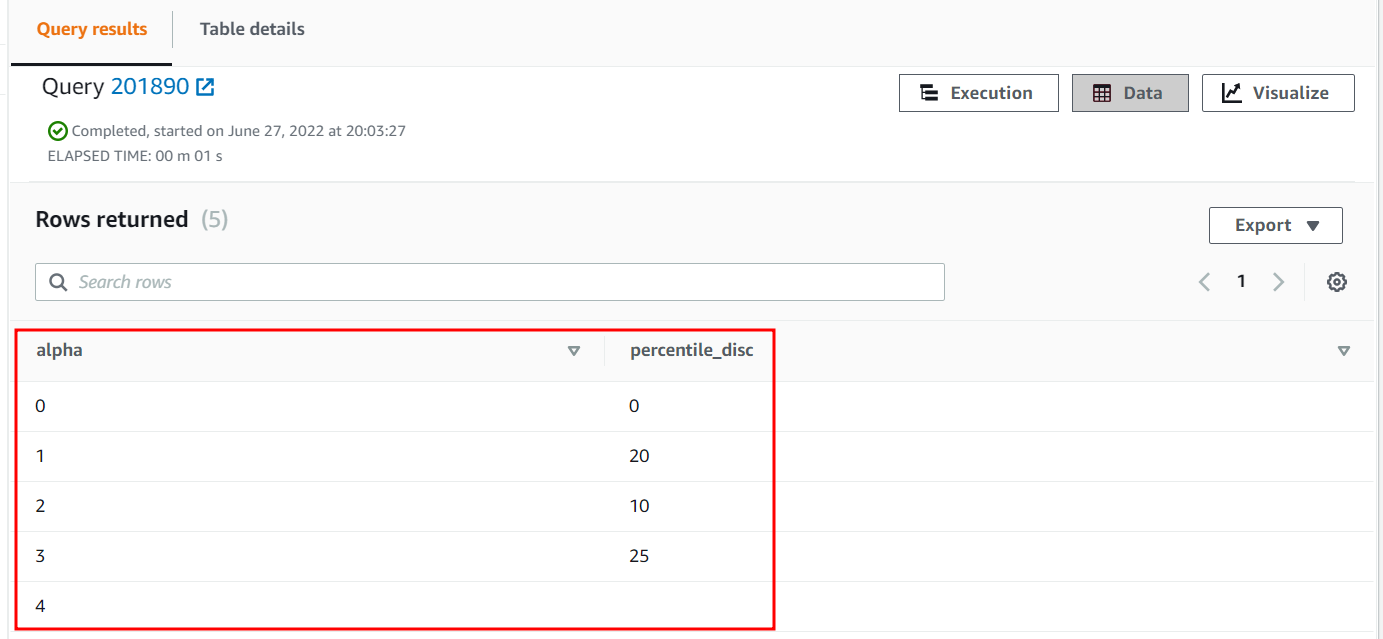
The 25th percentile of the alpha column of the approximation table will be as follows:
| Alpha | percentile_disc |
| 0 | 0 |
| 1 | 20 |
| 2 | 10 |
| 3 | 25 |
| 4 |
Conclusion
In this article, we have studied how to use the APPROXIMATE PERCENTILE_DISC function in Redshift to calculate any percentile of a column. We have learned the use of APPROXIMATE PERCENTILE_DISC function on different datasets with different percentile numeric constants. We have learned how to use different parameters while using the APPROXIMATE PERCENTILE_DISC function and how this function treats when a percentile constant of more than 1 is passed.