Syntax of ANY_VALUE Function
Following is the syntax to use the ANY_VALUE function in Amazon Redshift:
Following is the description of the parameters and options passed to the Redshift ANY_VALUE function:
While executing the ANY_VALUE function, specify either DISTINCT or ALL to get a random output from the input expressions. When we specify the DISTINCT keyword, the ANY_VALUE function will remove duplicate values from the input expression and then return the random value from these unique expressions.
On the other hand, if the ALL keyword is used, the ANY_VALUE function will return the random expression from all the input expressions.
Expression
It is the target column or expression on which the ANY_VALUE function operates and gets a value randomly. It can contain the data of the following data types:
- DOUBLE PRECISION
- REAL
- TIMETZ
- GEOGRAPHY
- DECIMAL
- HLLSKETCH
- GEOMETRY
- INTEGER
- SMALLINT
- TIMESTAMP
- VARCHAR
- TIMESTAMPTZ
- BIGINT
- SUPER
- VARBYTE
- BOOLEAN
- TIME
- CHAR
- DATE
Examples of ANY_VALUE Function
This section of the article includes different examples of the Redshift ANY_VALUE function to elaborate it thoroughly.
Setting up the Environment
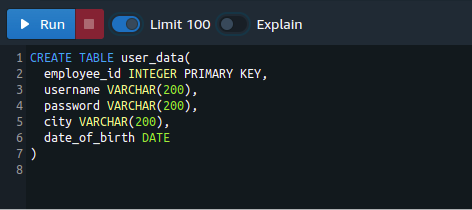
Before going along with different examples, we need to create a table with different columns. The following query can create a table in the Redshift cluster with the following attributes:
- username
- employee_id
- password
- city
- date_of_birth
employee_id INTEGER PRIMARY KEY,
username VARCHAR(200),
password VARCHAR(200),
city VARCHAR(200),
date_of_birth DATE
)
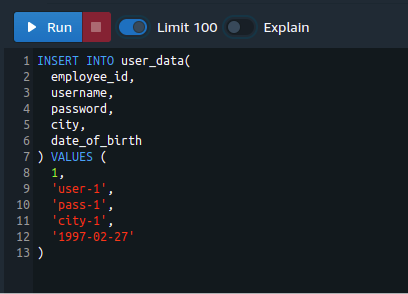
Now, we will insert some sample data into the user_data table of the Redshift cluster. Use the insert query to add the data by using the following query:
employee_id,
username,
password,
city,
date_of_birth
) VALUES (
1,
‘user-1’,
‘pass-1’,
‘city-1’,
‘1997-02-27’
)
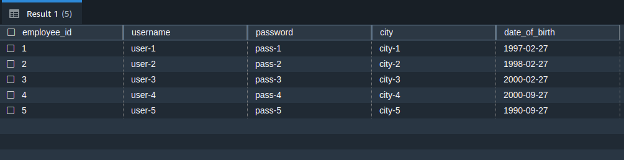
Run this query multiple times by changing the values to save the data of multiple users. Now, we will apply the ANY_VALUE function to this table.
After inserting the data of multiple users, use the following query to list all the data:
Applying ANY_VALUE on INTEGER Data Type
In this section, we will apply the ANY_VALUE on the INTEGER data type or the employee_id column of the user_data table we created in the previous section.
For this purpose, the following query can be used to get the employee ID of any employee:
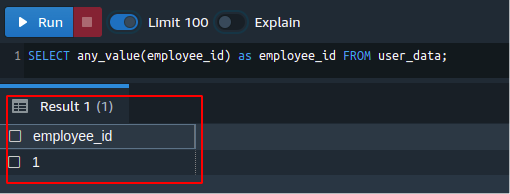
The previous query will select any value from the employee_id column and will return as an output of this query. The previous figure returned the employee_id of the random user from the user_data table.
Applying ANY_VALUE on STRING Data Type
Just like we applied the ANY_VALUE function on the INTEGER data type, it can also be applied to the STRING data type. When applied to the STRING data type field, the ANY_VALUE function randomly selects any of the data and returns it in response.
In order to get any random value from the username (STRING) field, execute the following query on the Redshift cluster:
It will return a random username entry from the user_data table.
Applying ANY_VALUE on DATE Data Type
We can also get a random value from the field which contains multiple entries of DATE data type. When the ANY_VALUE function is applied to the multiple values of the DATE data type, it randomly selects an entry and returns it in response.
To get a date_of_birth of a random user from the user_data table, execute the following query in the Redshift cluster:
This query will get a random date_of_birth from the table and return it in response.
ANY_VALUE Function by Using Group
We can use the ANY_VALUE function for simplifying and optimizing GROUP BY statements progress. A common issue that occurs with lots of queries is the consequence of queries with a clause of GROUP BY that can consist of just expressions utilized in the clause of GROUP BY or a consequence of aggregate function.
FROM customer
JOIN orders ON customer.id = orders.customer_id
GROUP BY customer.id , customer.name;
In the previous query attribute, the customer name requires to be in the GROUP BY clause for involvement within the consequence. This is unwanted and makes calculation complicated and sluggish.
In order to improve the query and make it faster to execute, you may implement the previous query by using the ANY_VALUE function.
FROM customer
JOIN orders ON customer.id = orders.customer_id
GROUP BY customer.id;
Conclusion
ANY_VALUE is a function that takes multiple values as input and returns a random value from these input values. It selects the output from the input expressions in a nondeterministic manner. If the input expression to the ANY_VALUE function does not result in any row, the function’s output will be a NULL value. This blog describes the different use cases to implement the ANY_VALUE function to get the random output.