We will discuss different scenarios to change the order of columns in PySpark DataFrame.
For all the scenarios, we are using select() method. Before moving to the scenarios, we will create PySpark DataFrame first.
Example:
Here we are going to create PySpark dataframe with 5 rows and 6 columns.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#display the dataframe
df.show()
Output:

Scenario 1: Rearrange the columns
In this scenario, we will use only select() method to order/rearrange the columns in the given PySpark DataFrame by providing one by one column in the method.
Syntax:
dataframe.select(“column1”,…………,”column”)
Where:
- dataframe is the input PySpark DataFrame
- columns is the column names to be rearranged.
Example:
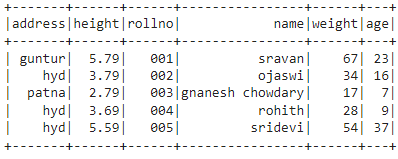
In this example, we are going to rearrange the columns in this order – “address”,”height”,”rollno”,”name”,”weight”, and “age”. Then, display the DataFrame using show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#rearrange the columns in the order - "address","height","rollno","name","weight","age"
df =df.select("address","height","rollno","name","weight","age")
#dispay the dataframe
df.show()
Output:
Scenario 2: Rearrange the columns in ascending order
In this scenario, we will use sorted() method along with select() method to rearrange the columns in the ascending order through sorted() method.
Syntax:
dataframe.select(sorted(dataframe.columns,reverse=False))
Where:
- dataframe is the input PySpark DataFrame
- sorted() is the method which will sort the DataFrame in ascending order. It will take two parameters. The first parameter refers to the columns method to select all columns from the DataFrame. The second parameter is used to rearrange the DataFrame in ascending order if it is set to False.
Example:
In this example, we are going to rearrange the columns in ascending order to display the DataFrame using show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#rearrange the columns in ascending order
df =df.select(sorted(df.columns,reverse=False))
#dispay the dataframe
df.show()
Output:

Scenario 3: Rearrange the columns in descending order
In this scenario, we will use sorted() method along with select() method to rearrange the columns in the descending order through sorted() method.
Syntax:
dataframe.select(sorted(dataframe.columns,reverse=True))
Where:
- dataframe is the input PySpark DataFrame
- sorted() is the method which will sort the DataFrame in ascending order. It will take two parameters. The first parameter refers to the columns method to select all columns from the DataFrame. The second parameter is used to rearrange the DataFrame in descending order if it is set to True.
Example:
In this example, we are going to rearrange the columns in descending order to display the DataFrame using show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#rearrange the columns in descending order
df =df.select(sorted(df.columns,reverse=True))
#dispay the dataframe
df.show()
Output:

Conclusion
In this tutorial, we discussed how to rearrange the columns in PySpark DataFrame with three scenarios by applying select() method. We have used sorted() method along with select() method to rearrange the columns.