
[adthrive-in-post-video-player video-id=”vimuNhHR” upload-date=”2020-03-17T14:20:12.000Z” name=”Python BeautifulSoup Tutorial For begginers” description=”Python BeautifulSoup Tutorial For begginers” player-type=”collapse” override-embed=”true”]
To check if the installation was successful, activate the Python interactive shell and import BeautifulSoup. If no error shows up, it means everything went fine. If you do not know how to go about that, type the following commands in your terminal.
Python 3.5.2 (default, Sep 14 2017, 22:51:06)
[GCC 5.4.0 20160609] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import bs4
To work with the BeautifulSoup library, you have to pass in html. When working with real websites, you can get the html of a webpage using the requests library. The installation and use of the requests library is beyond the scope of this article, however you could find your way around the documentation it‘s pretty easy to use. For this article, we are simply going to be using html in a python string which we would be calling html.
<head>
<title>Employee Profile</title>
<meta charset="utf-8"/>
</head>
<body>
<div class="name"><b>Name:</b>Dr Peter Parker</div>
<div class="job"><b>Job:</b>Machine Learning Engineer</div>
<div class="telephone"><b>Telephone:</b>+12345678910</div>
<div class="email"><b>Email:</b><a href="mailto:[email protected]">
[email protected]</a></div>
<div class="website"><b>Website:</b><a href="http://pparkerworks.com">
pparkerworks.com</a></div>
</body>
</html>
"""
To use beautifulsoup, we import it into the code using the code below:
This would introduce BeautifulSoup into our namespace and we can get to use it in parsing our string.
Now, soup is a BeautifulSoup object of type bs4.BeautifulSoup and we can get to perform all the BeautifulSoup operations on the soupvariable.
Let‘s take a look at some things we can do with BeautifulSoup now.
MAKING THE UGLY, BEAUTIFUL
When BeautifulSoup parses html, it‘s not usually in the best of formats. The spacing is pretty horrible. The tags are difficult to find. Here is an image to show what they would look like when you get to print the soup:
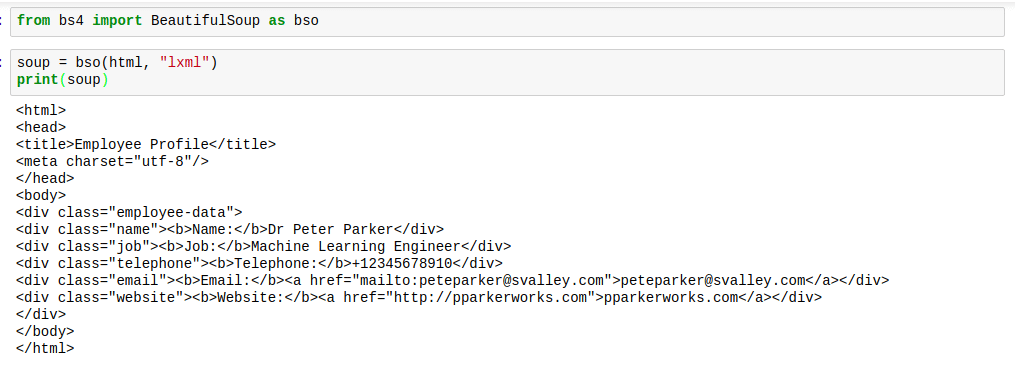
However, there is a solution to this. The solution gives the html the perfect spacing, making things look good. This solution is deservedly called “prettify“.
Admittedly, you may not get to use this feature most of the time; however there are times when you may not have access to the inspect element tool of a web browser. In those times of limited resources, you would find the prettify method very useful.
Here is how you use it:
The markup would look properly spaced, just like in the image below:
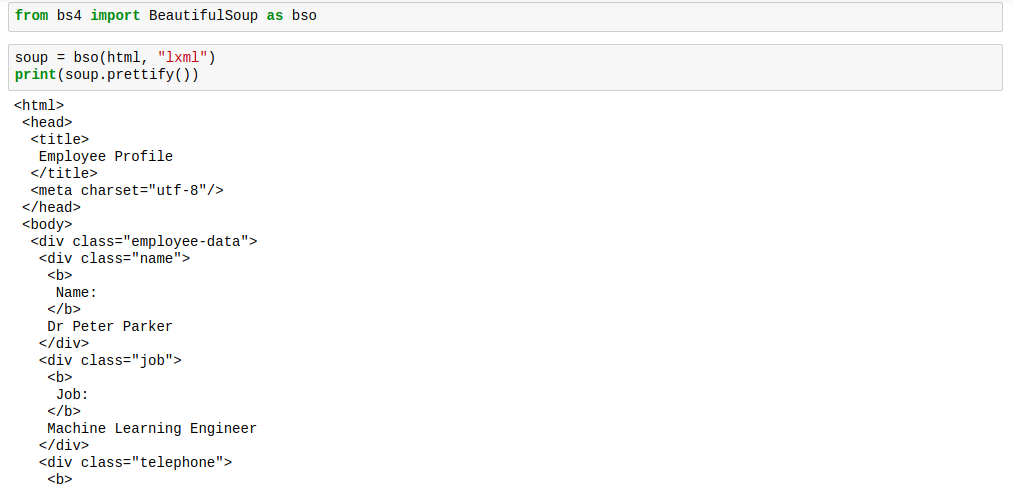
When you apply the prettify method on the soup, the result is no longer a type bs4.BeautifulSoup. The result is now type ‘unicode‘. This means you cannot apply other BeautifulSoup methods on it, however the soup itself is not affected so we are safe.
FINDING OUR FAVORITE TAGS
HTML is made up of tags. It stores all of it’s data in them, and in the midst of all that clutter lies the data we need. Basically, this means when we find the right tags, we can get what we need.
So how do we find the right tags? We make use of BeautifulSoup‘s find and find_all methods.
Here‘s how they work:
The find method searches for the first tag with the needed name and returns an object of type bs4.element.Tag.
The find_all method on the other hand, searches for all tags with the needed tag name and returns them as a list of type bs4.element.ResultSet. All the items in the list are of type bs4.element.Tag, so we can carry out indexing on the list and continue our beautifulsoup exploration.
Let‘s see some code. Let‘s find all the div tags:
We would get the following result:
Checking the html variable, you would notice that this is the first div tag.
We would get the following result:
<div class="name"><b>Name:</b>Dr Peter Parker</div>,
<div class="job"><b>Job:</b>Machine Learning Engineer</div>,
<div class="telephone"><b>Telephone:</b>+12345678910</div>,
<div class="email"><b>Email:</b><a href="mailto:[email protected]">
[email protected]</a></div>,
<div class="website"><b>Website:</b><a href="http://pparkerworks.com">
pparkerworks.com</a></div>]
It returns a list. If for example you want the third div tag, you run the following code:
It would return the following:
FINDING THE ATTRIBUTES OF OUR FAVORITE TAGS
Now that we have seen how to get our favorite tags, how about getting their attributes?
You may be thinking at this point: “What do we need attributes for?“. Well, a lot of times, most of the data we need are going to be email addresses and websites. This sort of data is usually hyperlinked in webpages, with the links in the “href“ attribute.
When we have extracted the needed tag, using the find or find_all methods, we can get attributes by applying attrs. This would return a dictionary of the attribute and it‘s value.
To get the email attribute for example, we get the <a> tags which surrounds the needed info and do the following.
Which would return the following result:
Same thing for the website attribute.
Which would return the following result:
The returned values are dictionaries and normal dictionary syntax can be applied to get the keys and values.
LET‘S SEE THE PARENT AND CHILDREN
There are tags everywhere. Sometimes, we want to know what the children tags are and what the parent tag is.
If you don‘t already know what a parent and child tag is, this brief explanation should suffice: a parent tag is the immediate outer tag and a child is the immediate inner tag of the tag in question.
Taking a look at our html, the body tag is the parent tag of all the div tags. Also, the bold tag and the anchor tag are the children of the div tags, where applicable as not all div tags possess anchor tags.
So we can access the parent tag by calling the findParent method.
This would return the whole of the body tag:
<div class="name"><b>Name:</b>Dr Peter Parker</div>
<div class="job"><b>Job:</b>Machine Learning Engineer</div>
<div class="telephone"><b>Telephone:</b>+12345678910</div>
<div class="email"><b>Email:</b><a href="mailto:[email protected]">
[email protected]</a></div>
<div class="website"><b>Website:</b><a href="http://pparkerworks.com">
pparkerworks.com</a></div>
</body>
To get the children tag of the fourth div tag, we call the findChildren method:
It returns the following:
WHAT‘S IN IT FOR US?
When browsing web pages, we do not see tags everywhere on the screen. All we see is the content of the different tags. What if we want the content of a tag, without all of the angular brackets making life uncomfortable? That‘s not difficult, all we‘d do is to call get_text method on the tag of choice and we get the text in the tag and if the tag has other tags in it, it also gets their text values.
Here‘s an example:
This returns all of the text values in the body tag:
Job:Machine Learning Engineer
Telephone:+12345678910
Email:[email protected]
Website:pparkerworks.com
CONCLUSION
That‘s what we‘ve got for this article. However, there are still other interesting things that can be done with beautifulsoup. You can either check out the documentation or use dir(BeautfulSoup) on the interactive shell to see the list of operations that can be carried out on a BeautifulSoup object. That‘s all from me today, till I write again.