To process the columns in Apache Spark quickly and efficiently, we need to compress the data. Data compression saves our memory and all the columns are converted into flat level. That means that the flat column level storage exists. The file which stores these is known as the PARQUET file. In PySpark, the write.parquet() function converts the DataFrame to the parquet file. In this guide, we will mainly focus on writing/saving the PySpark DataFrame to parquet using the write.parquet() function which is available in pyspark.sql.DataFrameWriter class. Using this parquet, we can make the encoding schemes easier.
Topic of Contents:
Pyspark.sql.DataFrameWriter.parquet()
We can directly utilize this function from our DataFrame object using the write() method. It takes four parameters.
Syntax:
Let’s see the syntax of write.parquet():
Parameters:
-
- The first parameter takes the parquet file name or location in which the parquet file is stored.
- If you want to convert the parquet files based on the values in particular column/s, you can pass the column or list of columns to the partitionBy parameter. For each category, the parquet files are created.
- Appending the data to the existing parquet file is possible by specifying the “append” to the mode parameter. Also, we can overwrite the existing parquet file using the “overwrite” mode.
- Compression is used for compression purposes. This can be optional.
Write.parquet()
In our first scenario, we just convert/write our PySpark DataFrame to a parquet file.
Let’s create a PySpark DataFrame with 5 records and write this to the “industry_parquet” parquet file.
from pyspark.sql import SparkSession,Row
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# create the dataframe that store Industry details
industry_df = linuxhint_spark_app.createDataFrame([
Row(Type='Agriculture',Area='USA',Rating='Hot',Total_employees=100),
Row(Type='Agriculture',Area='India',Rating='Hot',Total_employees=200),
Row(Type='Development',Area='USA',Rating='Warm',Total_employees=100),
Row(Type='Education',Area='USA',Rating='Cool',Total_employees=400),
Row(Type='Education',Area='USA',Rating='Warm',Total_employees=20)
])
# Actual DataFrame
industry_df.show()
# Write the industry_df to the parquet file
industry_df.coalesce(1).write.parquet("industry_parquet")
Output:
This is the DataFrame which holds 5 records.

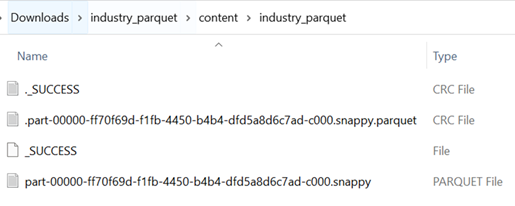
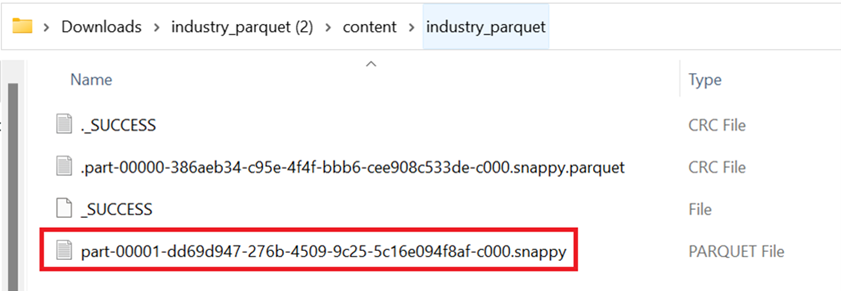
A parquet file is created for the previous DataFrame.
Write.Parquet() with PartitionBy Parameter
If you want to convert a parquet file for different categories based on single/multiple columns, you can utilize the partitionBy parameter. For a single column, we need to pass the column as a string. For multiple columns, we need to pass the column names inside the list that is separated by comma.
Example 1: PartitionBy – Single Column
Utilize the previous PySpark DataFrame and write this to the parquet files based on the values in the “Area” column.
from pyspark.sql import SparkSession,Row
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# create the dataframe that store Industry details
industry_df = linuxhint_spark_app.createDataFrame([
Row(Type='Agriculture',Area='USA',Rating='Hot',Total_employees=100),
Row(Type='Agriculture',Area='India',Rating='Hot',Total_employees=200),
Row(Type='Development',Area='USA',Rating='Warm',Total_employees=100),
Row(Type='Education',Area='USA',Rating='Cool',Total_employees=400),
Row(Type='Education',Area='USA',Rating='Warm',Total_employees=20)
])
# Write the industry_df to the parquet file with partitionBy parameter
industry_df.write.parquet("industry_parquet2",partitionBy='Area')
Output:
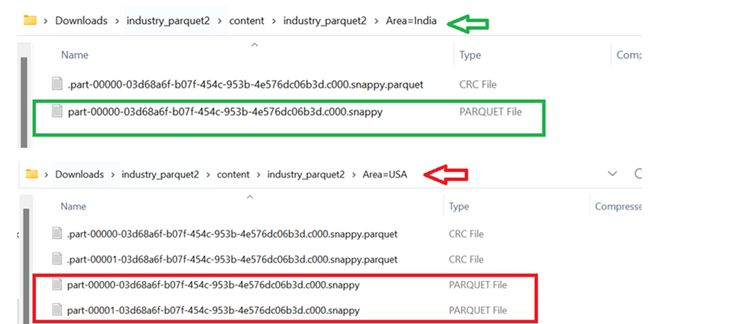
There are 2 categories in the “Area” column: “India” and “USA”. So, 2 folders are created.

Let’s open and look into it. We can see that the “India” record is stored in a single parquet file and the “USA” records are stored in two parquet files.
Example 2: PartitionBy – Multiple Column
Write the parquet files by partitioning based on “Type” and “Rating”.
from pyspark.sql import SparkSession,Row
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# create the dataframe that store Industry details
industry_df = linuxhint_spark_app.createDataFrame([
Row(Type='Agriculture',Area='USA',Rating='Hot',Total_employees=100),
Row(Type='Agriculture',Area='India',Rating='Hot',Total_employees=200),
Row(Type='Development',Area='USA',Rating='Warm',Total_employees=100),
Row(Type='Education',Area='USA',Rating='Cool',Total_employees=400),
Row(Type='Education',Area='USA',Rating='Warm',Total_employees=20)
])
# Write the industry_df to the parquet file with partitionBy parameter
industry_df.write.parquet("industry_parquet_part",partitionBy=['Type','Rating'])
Output:
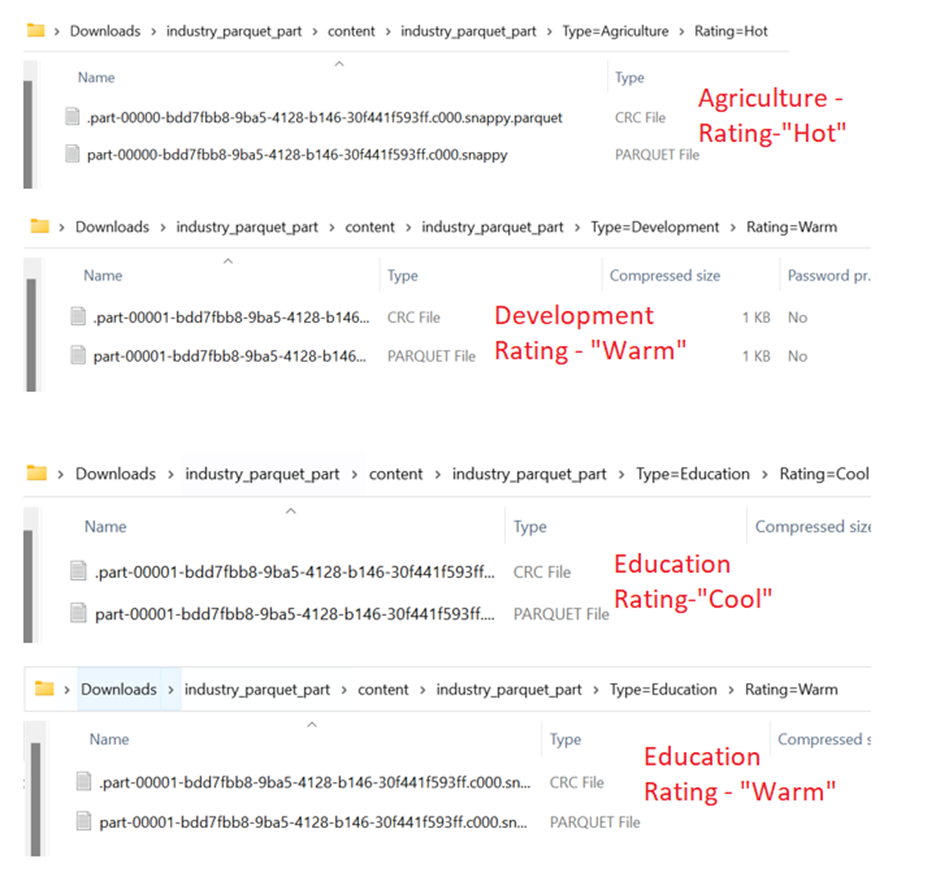
The “Type” column holds three categories: “Agriculture”, “Development”, and “Education”. The first 3 folders are created with these categories.
-
- In “Agriculture”, a folder is created with the “Hot” rating.
- In “Development”, a folder is created with the “Warm” rating.
- In “Education”, a folder is created with the “Warm” and “Cool” ratings.

Let’s open each one and look at the parquet files.
Write.parquet() with the Mode Parameter
As we discussed at the start of this guide, adding and modifying the existing data in the parquet is done through the mode parameter. If you want to append the data to the existing parquet file, use the “append” mode. If you want to overwrite the existing data to the existing parquet file, use the “overwrite” mode.
Example 1: Append Mode
Create another DataFrame which is “industry_df2” with 4 columns and 2 records and append this to the first DataFrame.
from pyspark.sql import SparkSession,Row
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# create new dataframe that store Industry details with 2 records
industry_df2 = linuxhint_spark_app.createDataFrame([
Row(Type='Government',Area='USA',Rating='Hot',Total_employees=100),
Row(Type='Business',Area='Japan',Rating='Cold',Total_employees=2030)
])
industry_df2.show()
# Append the industry_df2 to the first parquet file
industry_df2.write.mode('append').parquet("industry_parquet")
Output:
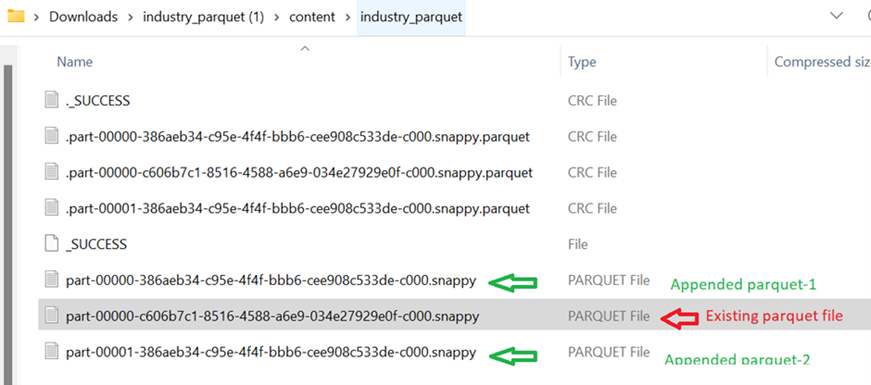
This is our new DataFrame which holds two records. Now, we append these two records to the first parquet file (industry_parquet).

Two parquet files are created. We can see that each record is stored in one parquet file.
Example 2: Overwrite Mode
Create another DataFrame which is “industry_df2” with 4 columns and 2 records and append this to the first DataFrame.
from pyspark.sql import SparkSession,Row
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# create new dataframe that store Industry details with 2 records
industry_df2 = linuxhint_spark_app.createDataFrame([
Row(Type='Government',Area='USA',Rating='Hot',Total_employees=100),
Row(Type='Business',Area='Japan',Rating='Cold',Total_employees=2030)
])
# Overwrite the first DataFrame with the above DataFrame.
industry_df2.write.mode('overwrite').parquet("industry_parquet")
Output:
Previously, the parquet file holds the first PySpark DataFrame data. Now, it holds the data that is present in the second PySpark DataFrame
Conclusion
We came to know that a parquet file is used to store the data in a flat column storage format. PySpark supports the write.parquet() function which writes the PySpark DataFrame to the parquet file. In this guide, all the possible parameters are discussed with examples and the parquet files as outputs. If you are running the code snippets in Google Colab, you need to download the entire zip folder and extract the parquet files. We utilize the files.download() method for this.