Pyspark.sql.DataFrame.selectExpr()
The selectexpr() function takes the columns/set of expressions and returns the DataFrame based on the specified expressions/columns. Multiple expressions can be specified in this function which is separated by comma. To display the DataFrame, we can use the show()/collect() functions.
Syntax:
Here, the pyspark_DataFrame_object is the input PySpark DataFrame.
Scenario 1: Select the Columns
In this scenario, we will see how to select the particular columns from the PySpark DataFrame using the selectExpr() function.
The expression that is used is “existing_column as new_name”. Here, the existing_column is the column name that is present in the DataFrame and it is displayed as new_name (Aliasing).
Example:
Create a PySpark DataFrame named “agri_df” with 5 rows and columns. Get the “Soil_status” and “Soil_Type” columns as “STATUS” and “TYPE”.
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# farming data with 5 rows and 5 columns
agri =[{'Soil_Type':'Black','Irrigation_availability':'No','Acres':2500,'Soil_status':'Dry',
'Country':'USA'},
{'Soil_Type':'Black','Irrigation_availability':'Yes','Acres':3500,'Soil_status':'Wet',
'Country':'India'},
{'Soil_Type':None,'Irrigation_availability':'Yes','Acres':210,'Soil_status':'Dry',
'Country':'UK'},
{'Soil_Type':'Other','Irrigation_availability':'No','Acres':1000,'Soil_status':'Wet',
'Country':'USA'},
{'Soil_Type':'Sand','Irrigation_availability':'No','Acres':500,'Soil_status':'Dry',
'Country':'India'}]
# create the dataframe from the above data
agri_df = linuxhint_spark_app.createDataFrame(agri)
# Get the Soil_status and Soil_Type as "STATUS" and "TYPE".
agri_df.selectExpr("Soil_status as STATUS","Soil_Type as TYPE").show()
Output:

Scenario 2: Specifying the Conditional Expressions
In this scenario, we will see how to evaluate the conditions within the selectExpr() function.
The expression that is used is “existing_column operator value”. Here, the existing_column is the column name that is present in the DataFrame and we compare each value in this column with the string/value.
Example 1:
Check whether the country is “USA” or not. The equalto (=) operator is used here.
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# farming data with 5 rows and 5 columns
agri =[{'Soil_Type':'Black','Irrigation_availability':'No','Acres':2500,'Soil_status':'Dry',
'Country':'USA'},
{'Soil_Type':'Black','Irrigation_availability':'Yes','Acres':3500,'Soil_status':'Wet',
'Country':'India'},
{'Soil_Type':None,'Irrigation_availability':'Yes','Acres':210,'Soil_status':'Dry',
'Country':'UK'},
{'Soil_Type':'Other','Irrigation_availability':'No','Acres':1000,'Soil_status':'Wet',
'Country':'USA'},
{'Soil_Type':'Sand','Irrigation_availability':'No','Acres':500,'Soil_status':'Dry',
'Country':'India'}]
# create the dataframe from the above data
agri_df = linuxhint_spark_app.createDataFrame(agri)
# Check whether the country is 'USA' or not.
agri_df.selectExpr("Country = 'USA'").show()
Output:

Example 2:
Check whether the Soil_Type is NULL or not. The NULL keyword checks whether the value is NULL or not. If it is null, true is returned. Otherwise, false is returned. The final expression is “Soil_Type IS NULL”
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# farming data with 5 rows and 5 columns
agri =[{'Soil_Type':'Black','Irrigation_availability':'No','Acres':2500,'Soil_status':'Dry',
'Country':'USA'},
{'Soil_Type':'Black','Irrigation_availability':'Yes','Acres':3500,'Soil_status':'Wet',
'Country':'India'},
{'Soil_Type':None,'Irrigation_availability':'Yes','Acres':210,'Soil_status':'Dry',
'Country':'UK'},
{'Soil_Type':'Other','Irrigation_availability':'No','Acres':1000,'Soil_status':'Wet',
'Country':'USA'},
{'Soil_Type':'Sand','Irrigation_availability':'No','Acres':500,'Soil_status':'Dry',
'Country':'India'}]
# create the dataframe from the above data
agri_df = linuxhint_spark_app.createDataFrame(agri)
# Check whether the Soil_Type is NULL or not.
agri_df.selectExpr("Soil_Type IS NULL").show()
Output:

Scenario 3: Evaluating the Expressions
In this scenario, we will see how to specify the mathematical expressions. The expression that is used is “existing_column mathematical_expression”.
Example:
- Display the actual “Acres” column.
- Add 100 to the “Acres” column.
- Subtract 100 from the “Acres” column.
- Multiply 100 with the “Acres” column.
- Divide the “Acres” column by 100.
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# farming data with 5 rows and 5 columns
agri =[{'Soil_Type':'Black','Irrigation_availability':'No','Acres':2500,'Soil_status':'Dry',
'Country':'USA'},
{'Soil_Type':'Black','Irrigation_availability':'Yes','Acres':3500,'Soil_status':'Wet',
'Country':'India'},
{'Soil_Type':None,'Irrigation_availability':'Yes','Acres':210,'Soil_status':'Dry',
'Country':'UK'},
{'Soil_Type':'Other','Irrigation_availability':'No','Acres':1000,'Soil_status':'Wet',
'Country':'USA'},
{'Soil_Type':'Sand','Irrigation_availability':'No','Acres':500,'Soil_status':'Dry',
'Country':'India'}]
# create the dataframe from the above data
agri_df = linuxhint_spark_app.createDataFrame(agri)
# Write 4 Expressions to subtract, add, divide and multiply Acres column.
agri_df.selectExpr("Acres","Acres - 100","Acres * 100","Acres + 100","Acres / 100").show()
Output:

Scenario 4: Applying the Aggregate Functions
SUM(column_name) – It evaluates the total value in the specified column.
MEAN(column_name) – It evaluates the average value in the specified column.
MIN(column_name) – It returns the minimum element among all elements in the specified column.
MAX(column_name) – It returns the maximum element among all elements in the specified column.
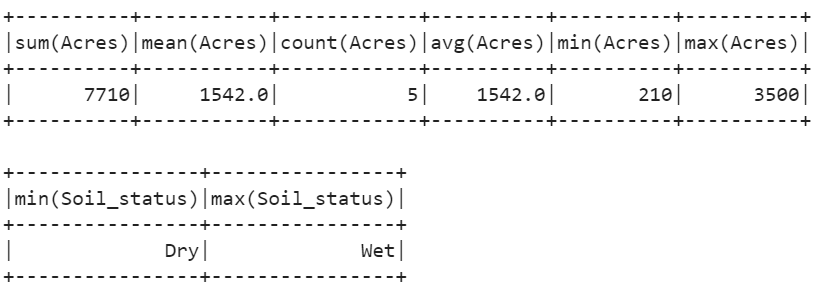
Example:
- Find the total, average, count, minimum, and maximum elements of “Acres”.
- Find the minimum and maximum elements in the “Soil_status” column.
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# farming data with 5 rows and 5 columns
agri =[{'Soil_Type':'Black','Irrigation_availability':'No','Acres':2500,'Soil_status':'Dry',
'Country':'USA'},
{'Soil_Type':'Black','Irrigation_availability':'Yes','Acres':3500,'Soil_status':'Wet',
'Country':'India'},
{'Soil_Type':None,'Irrigation_availability':'Yes','Acres':210,'Soil_status':'Dry',
'Country':'UK'},
{'Soil_Type':'Other','Irrigation_availability':'No','Acres':1000,'Soil_status':'Wet',
'Country':'USA'},
{'Soil_Type':'Sand','Irrigation_availability':'No','Acres':500,'Soil_status':'Dry',
'Country':'India'}]
# create the dataframe from the above data
agri_df = linuxhint_spark_app.createDataFrame(agri)
# Aggregate operations
agri_df.selectExpr("SUM(Acres)","MEAN(Acres)","COUNT(Acres)", "AVG(Acres)","MIN(Acres)",
"MAX(Acres)").show()
agri_df.selectExpr("MIN(Soil_status)", "MAX(Soil_status)").show()
Output:
Conclusion
We discussed about the selectExpr() function which takes the columns/sets of expressions and returns the DataFrame based on the specified expressions/columns. As part of this, we learned the four major scenarios in which the selectExpr() is applicable. Multiple expressions can be specified in this function which are separated by comma. There is no need to create a TEMPORARY VIEW to use the selectExpr() function.