Data Processing in Spark is done in clusters. To process the data in the cluster more quickly and efficiently, partitioning the data is important. If a cluster contains “n” computers, providing each partitioned data to different computers, the cluster computing becomes faster and improves the efficiency. In this guide, we will discuss how to repartition the existing data into different partitions using the repartition() function that is available in PySpark.
Topic of Contents:
Pyspark.sql.DataFrame.repartition()
Repartition() allows you to modify the partitions in your PySpark DataFrame. It can be possible to increase or decrease the existing partitions. It partitions the data by shuffling the existing data. This function gives wider transformation and better than any other transformation techniques. Basically, this function takes two parameters.
Syntax:
Let’s see the syntax of repartition():
Parameters:
-
- The numPartitions is an optional parameter which is used to specify the number of partitions that have to be done. If it is not specified, the default partition is done based on the data in the PySpark DataFrame.
- The columns is also an optional parameter that is used to partition the DataFrame based on these column names. We can pass the single/multiple columns at a time which are separated by comma.
Data:
In this entire guide, we will use only one PySpark DataFrame for demonstration. Make sure that you first create this DataFrame (with 6 columns and 10 rows) in your environment after the installation of PySpark.
from pyspark.sql import SparkSession,Row
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# create the dataframe that store Farming details
farming_df = linuxhint_spark_app.createDataFrame([Row(Area='Urban',Land='Poor',Soil='Black',
Field_count=100,Crop_Name='Paddy',Quantity=34000),
Row(Area='Urban',Land='Rich',Soil='Red',Field_count=20,Crop_Name='Wheat',
Quantity=200000),
Row(Area='Rural',Land='Poor',Soil='Red',Field_count=200,Crop_Name='Paddy',
Quantity=24000),
Row(Area='Rural',Land='Poor',Soil='Black',Field_count=400,Crop_Name='Paddy',
Quantity=24000),
Row(Area='Urban',Land='Poor',Soil='Red',Field_count=1000,Crop_Name='Maize',
Quantity=35000),
Row(Area='Urban',Land='Poor',Soil='Red',Field_count=200,Crop_Name='Corn',
Quantity=45000),
Row(Area='Rural',Land='Rich',Soil='Black',Field_count=150,Crop_Name='Potato',
Quantity=1200),
Row(Area='Urban',Land='Rich',Soil='Black',Field_count=70,Crop_Name='Chillies',
Quantity=13000),
Row(Area='Rural',Land='Rich',Soil='Sand',Field_count=50,Crop_Name='Paddy',
Quantity=0),
Row(Area='Rural',Land='Poor',Soil='Sand',Field_count=90,Crop_Name='Paddy',
Quantity=12000),
])
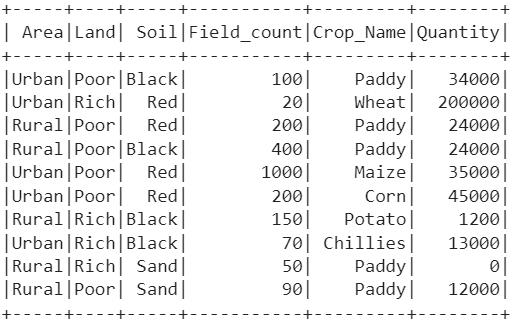
farming_df.show()
Output:
Repartition by NumPartitions
If you want to return the specified number of partitions, use the rdd.getNumPartitions() method. It returns an integer.
Let’s see the example for partitioning the previous data into 5 partitions. Write the partitioned data into CSV to check the partitions using the write.csv() method in the “overwrite” mode.
partitioned_farming = farming_df.repartition(5)
# Get the number of partitions
print(partitioned_farming.rdd.getNumPartitions())
# Save to CSV
partitioned_farming.write.mode("overwrite").csv("partitioned_farming1")
Output:
5

We can see that the DataFrame is partitioned into 5. Let’s open and see the data inside them:
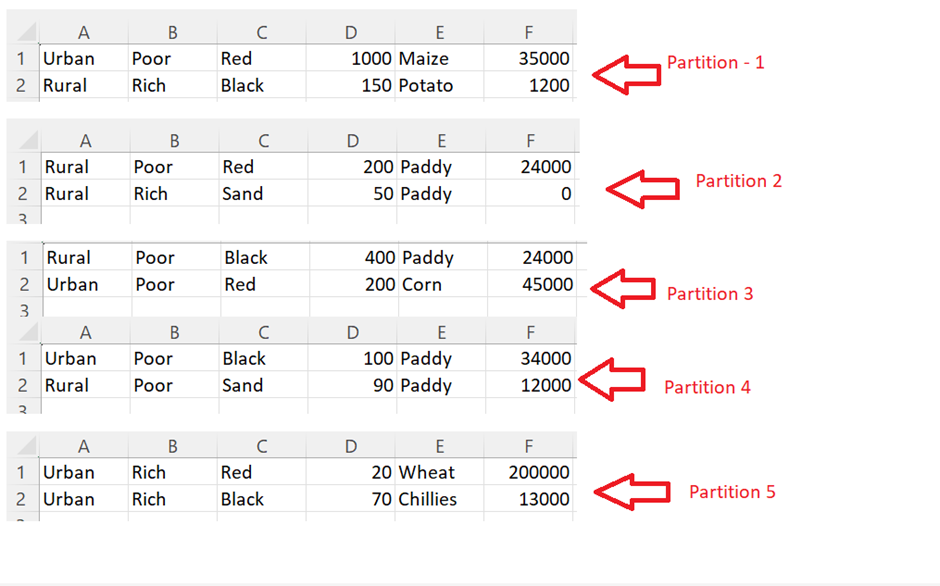
Partitions are done equally. Each partition file holds 2 records.
Repartition by Single Column
If you want to partition the data based on column values, you can specify the column name along with the partition number.
Example 1:
Let’s see the example for partitioning the previous data into 2 partitions based on the “Land” column.
partitioned_farming = farming_df.repartition(2,"Land")
# Get the number of partitions
print(partitioned_farming.rdd.getNumPartitions())
# Save to CSV
partitioned_farming.write.mode("overwrite").csv("partitioned_farming2")
Output:
2

We can see that the DataFrame is partitioned into 2. Let’s open and see the data inside them:
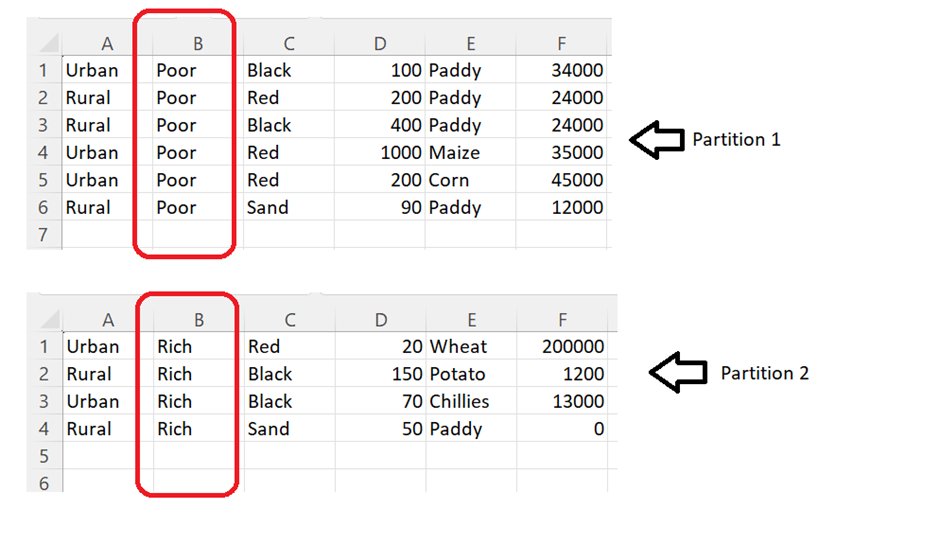
Partitions are done based on the values in the “Land” column. The first partition holds the “Land” with the “Poor” type. The second partition holds the “Land” with the “Rich” type.
Example 2:
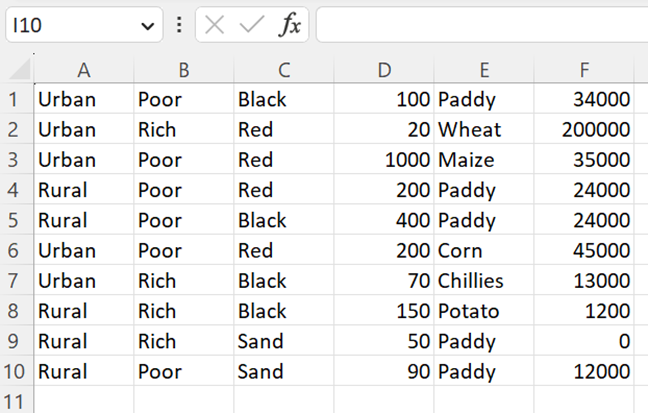
Let’s see the example for partitioning the previous data based on the “Area” column. Now, we don’t specify the number of partitions.
partitioned_farming = farming_df.repartition("Area")
# Get the number of partitions
print(partitioned_farming.rdd.getNumPartitions())
# Save to CSV
partitioned_farming.write.mode("overwrite").csv("partitioned_farming4")
Output:
1
It takes the default partition which is 1.
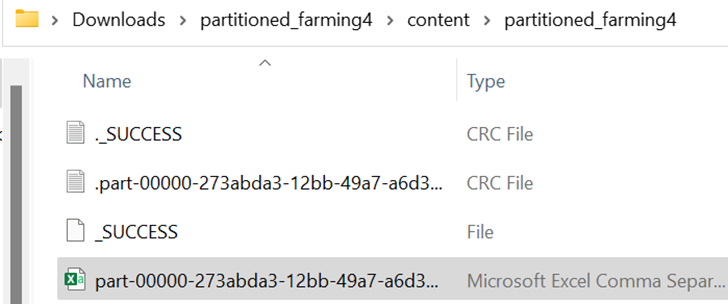
Partitioned Data:
Repartition by Multiple Columns
If you want to partition the data based on multiple column values, you can specify the column names along with the partition number.
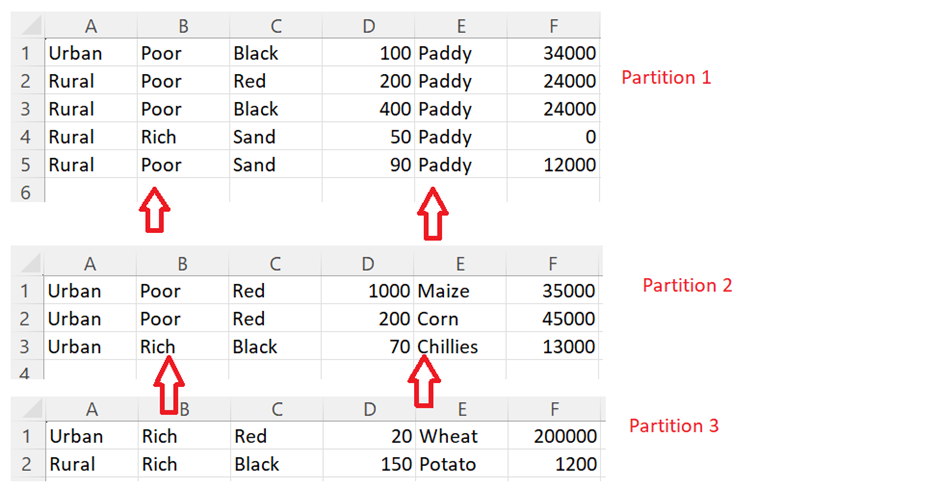
Let’s see the example for partitioning the previous data into 3 partitions based on the “Land” and “Crop_Name” columns.
partitioned_farming = farming_df.repartition(3,"Land","Crop_Name")
# Get the number of partitions
print(partitioned_farming.rdd.getNumPartitions())
# Save to CSV
partitioned_farming.write.mode("overwrite").csv("partitioned_farming3")
Output:
3

We can see that the DataFrame is partitioned into 3 based on the specified columns.
Conclusion
Now, we are able to understand how to repartition the existing data that is present in the PySpark DataFrame using the repartition() function. This function allows us to partition the data based on the columns also. It is more effective and efficient than the other partitioning techniques. In the real time scenarios, we use this function on RDD to share the partitioned files across clusters in parallel and equally.