Extracting only the useful data from the existing data is important. In PySpark, we can extract the strings based on patterns using the regexp_extract() function. In most of the applications like the employee databases, if company wants the employee contact, town, country, and pincode separately, regexp_extract() comes into picture. It extracts them into separate DataFrame columns and save them into the cluster nodes directly for storing/processing.
In this guide, we will see how to extract the particular types of strings into the DataFrame columns by specifying different search patterns with examples in detail.
Pyspark.sql.functions.regexp_extract()
This function extracts a specific group from the string in the PySpark DataFrame based on the specified pattern. It returns the string that is matched. Otherwise, the empty string is returned. It takes three parameters.
Syntax:
-
- The first parameter is the column which is of string type where the search is performed on this column.
- The second parameter is the pattern where the string is extracted based on the specified pattern.
- The index specifies the part of the match where we need to extract from the group of matches.
Example 1: Extract the Digits
In this scenario, we extract the digits that are present in the string. First, we create a DataFrame with an “Address” column. The “r'(\d+)’” is the pattern that extracts the digits from the string. Also, we specify the index as 1 in the regexp_extract() function.
import pyspark
from pyspark.sql import SparkSession,Row
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# create the dataframe with one row and column.
emp_df = linuxhint_spark_app.createDataFrame([Row(Address='Sravan Kumar, IT - Florida USA 000123456567')
])
emp_df.show(truncate=False)
# Extract digits
emp_df.select(regexp_extract(emp_df.Address, r'(\d+)', 1).alias('EMP PHONE')).show()
Output:
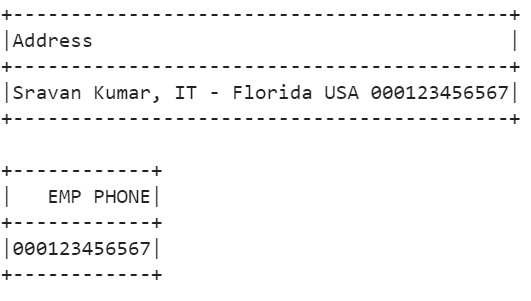
Here, we use the select() method to extract the digits from the “Address” column and store it as “EMP PHONE”. The “000123456567” digits are extracted from the “Address” column.
Example 2: Extract the Alphabets
In this scenario, we extract the first string from the matched group which is an alphabet. Let’s use the previous DataFrame and extract the first capital alphabet string by specifying the pattern – “([A-Z]+)”. We extract the first lower alphabet string by specifying the “([a-z]+)” pattern.
import pyspark
from pyspark.sql import SparkSession,Row
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# create the dataframe with one row and column.
emp_df = linuxhint_spark_app.createDataFrame([Row(Address='Sravan Kumar, IT - Florida USA 000123456567')
])
# Extract Uppercase alphabet
emp_df.select(regexp_extract(emp_df.Address, '([A-Z]+)',1)).show()
# Extract lowercase alphabet
emp_df.select(regexp_extract(emp_df.Address, '([a-z]+)',1)).show()
Output:
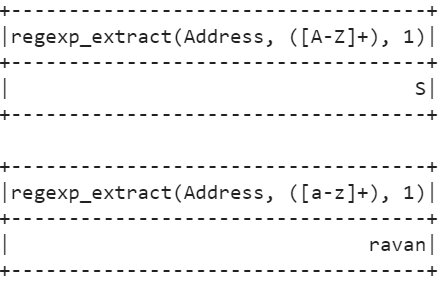
In the “Address” column, S is the first capital alphabet so it is extracted from this column. And “ravan” is the first string which is in lower case.
Example Application:
Let’s create a PySpark DataFrame that stores 5 employee details in one column. The format is “firstname lastname, sector – home_town state contact”. Let’s extract these into 6 different columns.
1. Extract the Employee’s First Name
To extract the first name of the employee, the pattern that we specify is “(\w*)”. This extracts the characters until the space occurs. The “w” is used to specify the characters in this pattern.
import pyspark
from pyspark.sql import SparkSession,Row
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# create the dataframe with one string column (Employee_details) that hold 5 employee details
employee_df = linuxhint_spark_app.createDataFrame([Row(Employee_details='Sravan Kumar, IT - Florida USA 000123456567'),
Row(Employee_details='Chandrika Sai, Banking - Delhi India 180012345658'),
Row(Employee_details='Deepak Rana, Industry - Goa India 300123456517'),
Row(Employee_details='Yogi Singh, IT - Dallas USA 400123456527'),
Row(Employee_details='Chattur Veda, Business - Italy UK 800123456537')
])
employee_df.select(employee_df.Employee_details,regexp_extract(employee_df
.Employee_details, "(\w*)", 1).alias("EMPLOYEE FIRST NAME")).show(truncate=False)
Output:

From all 5 records, the first name is returned and we display the extracted strings by storing them in the “EMPLOYEE FIRST NAME” column.
2. Extract the Employee’s Last Name
To extract the last name of the employee, the pattern that we specify is “() (\w*)”.
.Employee_details, "() (\w*)", 2).alias("EMPLOYEE LAST NAME")).show(truncate=False)
Output:

From all 5 records, the last name of the employee is returned and we display the extracted strings by storing them in the “EMPLOYEE LAST NAME” column.
3. Extract the Sector
To extract the employee’s sector, the pattern that we specify is “(,) (\w*)”. Here, we first specify the comma (,) as the sector is followed by this operator. Then, we return all characters of the sector. We also specify the index as 2.
.Employee_details, "(,) (\w*)", 2).alias("SECTOR")).show(truncate=False)
Output:

From all 5 records, the employee’s sector is returned and we display the extracted strings by storing them in the “SECTOR” column. The sectors are “IT”, “Baking”, “Industry”, “IT”, and “Business”.
4. Extract the Town
To extract the employee’s town, the pattern that we specify is “(-) (\w*)”. Here, we first specify the comma (-) as the town is followed by this operator. Then, we return all characters of the town. We also specify the index as 2.
.Employee_details,"(-) (\w*)", 2).alias("HOME-TOWN")).show(truncate=False)
Output:

From all 5 records, the employee’s hometown is returned and we display the extracted strings by storing them in the “HOME-TOWN” column.
5. Extract the Country
To extract the employee’s country, the pattern that we specify is “(\w*) (\w*$)”.
.Employee_details, "(\w*) (\w*$)", 1).alias("EMPLOYEE COUNTRY")).show(truncate=False)
Output:

6. Extract the Contact
To extract the employee’s contact, the pattern that we specify is “(\d*$)”. To extract the digits, the character “d” is used and “*” matches zero or more occurrences in the pattern. The “$” is used to match the end of the string.
.Employee_details,"(\d*$)", 1).alias("EMERGENCY CONTACT")).show(truncate=False)
Output:
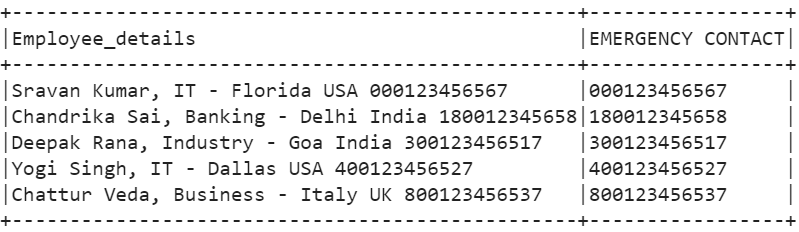
From all 5 records, the employee contact is returned and we display the extracted contacts by storing them in the “EMERGENCY CONTACT” column.
Conclusion
Regexp_extract() extracts a specific group from the string in the PySpark DataFrame based on the specified pattern. It returns the string that is matched. Otherwise, the empty string is returned. We have seen different examples by considering different patterns. For better understanding, we extracted all the strings with different patterns from the address type string format.