Pyspark.sql.DataFrameWriter.saveAsTable()
First, we will see how to write the existing PySpark DataFrame into the table using the write.saveAsTable() function. It takes the table name and other optional parameters like modes, partionBy, etc., to write the DataFrame to the table. It is stored as a parquet file.
Syntax:
- The Table_name is the name of the table that is created from the dataframe_obj.
- We can append/overwrite the data of the table using the mode parameter.
- The partitionBy takes the single/multiple columns to create partitions based on values in these provided columns.
Example 1:
Create a PySpark DataFrame with 5 rows and 4 columns. Write this Dataframe to a table named “Agri_Table1”.
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# farming data with 5 rows and 5 columns
agri =[{'Soil_Type':'Black','Irrigation_availability':'No','Acres':2500,'Soil_status':'Dry',
'Country':'USA'},
{'Soil_Type':'Black','Irrigation_availability':'Yes','Acres':3500,'Soil_status':'Wet',
'Country':'India'},
{'Soil_Type':'Red','Irrigation_availability':'Yes','Acres':210,'Soil_status':'Dry',
'Country':'UK'},
{'Soil_Type':'Other','Irrigation_availability':'No','Acres':1000,'Soil_status':'Wet',
'Country':'USA'},
{'Soil_Type':'Sand','Irrigation_availability':'No','Acres':500,'Soil_status':'Dry',
'Country':'India'}]
# create the dataframe from the above data
agri_df = linuxhint_spark_app.createDataFrame(agri)
agri_df.show()
# Write the above DataFrame to the table.
agri_df.coalesce(1).write.saveAsTable("Agri_Table1")
Output:


We can see that one parquet file is created with the previous PySpark Data.
Example 2:
Consider the previous DataFrame and write the “Agri_Table2” to the table by partitioning the records based on the values in the “Country” column.
agri_df.write.saveAsTable("Agri_Table2",partitionBy=['Country'])
Output:
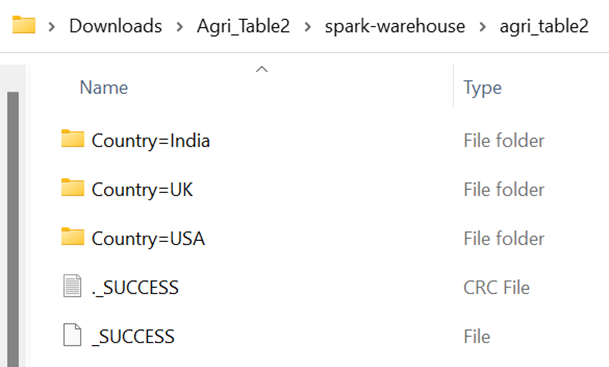
There are three unique values in the “Country” column – “India”, “UK”, and “USA”. So, three partitions are created. Each partition holds the parquet files.
Pyspark.sql.DataFrameReader.table()
Let’s load the table into the PySpark DataFrame using the spark.read.table() function. It takes only one parameter which is the path/table name. It directly loads the table into the PySpark DataFrame and all the SQL functions that are applied to the PySpark DataFrame can also be applied on this loaded DataFrame.
Syntax:
In this scenario, we use the previous table which was created from the PySpark DataFrame. Make sure that you need to implement the previous scenario code snippets in your environment.
Example:
Load the “Agri_Table1” table into the DataFrame named “loaded_data”.
loaded_data.show()
Output:

We can see that the table is loaded into the PySpark DataFrame.
Executing the SQL Queries
Now, we execute some SQL queries on the loaded DataFrame using the spark.sql() function.
linuxhint_spark_app.sql("SELECT * from Agri_Table1").show()
# WHERE Clause
linuxhint_spark_app.sql("SELECT * from Agri_Table1 WHERE Soil_status='Dry' ").show()
linuxhint_spark_app.sql("SELECT * from Agri_Table1 WHERE Acres > 2000 ").show()
Output:

- The first query displays all the columns and records from the DataFrame.
- The second query displays the records based on the “Soil_status” column. There are only three records with the “Dry” element.
- The last query returns two records with “Acres” that are greater than 2000.
Pyspark.sql.DataFrameWriter.insertInto()
Using the insertInto() function, we can append the DataFrame into the existing table. We can use this function along with the selectExpr() to define the column names and then insert it into the table. This function also takes the tableName as a parameter.
Syntax:
In this scenario, we use the previous table which was created from the PySpark DataFrame. Make sure that you need to implement the previous scenario code snippets in your environment.
Example:
Create a new DataFrame with two records and insert them into the “Agri_Table1” table.
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# farming data with 2 rows
agri =[{'Soil_Type':'Sand','Irrigation_availability':'No','Acres':2500,'Soil_status':'Dry',
'Country':'USA'},
{'Soil_Type':'Sand','Irrigation_availability':'No','Acres':1200,'Soil_status':'Wet',
'Country':'Japan'}]
# create the dataframe from the above data
agri_df2 = linuxhint_spark_app.createDataFrame(agri)
agri_df2.show()
# write.insertInto()
agri_df2.selectExpr("Acres", "Country", "Irrigation_availability", "Soil_Type",
"Soil_status").write.insertInto("Agri_Table1")
# Display the final Agri_Table1
linuxhint_spark_app.sql("SELECT * from Agri_Table1").show()
Output:
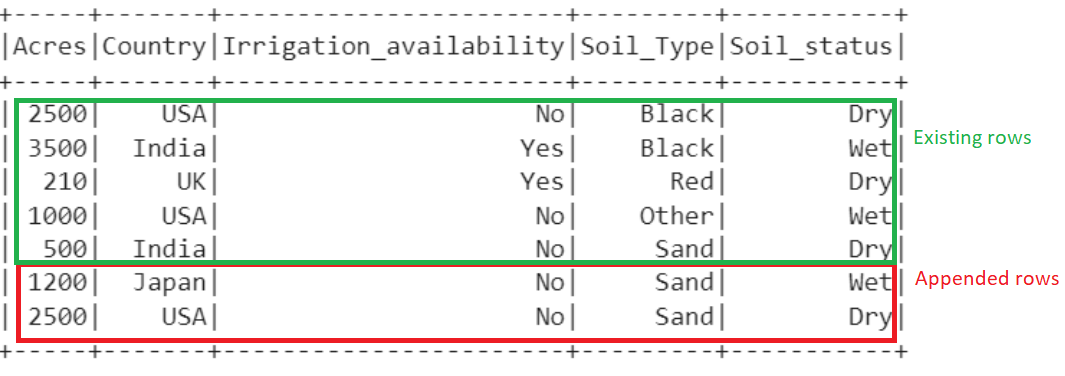
Now, the total number of rows that are present in the DataFrame is 7.
Conclusion
You now understand how to write the PySpark DataFrame to the table using the write.saveAsTable() function. It takes the table name and other optional parameters. Then, we loaded this table into the PySpark DataFrame using the spark.read.table() function. It takes only one parameter which is the path/table name. If you want to append the new DataFrame into the existing table, use the insertInto() function.