Topic of Contents:
Reading JSON into the PySpark DataFrame Using Pandas.read_json()
Reading JSON to PySpark DataFrame Using Spark.read.json()
Reading JSON to PySpark DataFrame Using the PySpark SQL
In this tutorial, we will look at how to read JSON into the PySpark DataFrame using the pandas.read_json(), spark.read.json(), and spark.sql. In all the scenarios, we will look at the different examples by considering the different JSON formats.
Install the PySpark library before implementing the following examples.
After the successful installation, you can see the output as follows:

Reading JSON into the PySpark DataFrame Using Pandas.read_json()
In PySpark, the createDataFrame() method is used to create the DataFrame directly. Here, we just need to pass the JSON file/path to the JSON file through the pandas.read_json() method. This read_json() method takes the filename/path which is available in the Pandas module. This is why it is necessary to import and utilize the Pandas module.
Syntax:
Example:
Let’s create a JSON file named “student_skill.json” that holds 2 records. Here, the keys/columns are “Student 1” and “Student 2”. The rows are name, age, skill1, and skill2.

import pandas
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# Using pandas.read_json()
candidate_skills = linuxhint_spark_app.createDataFrame(pandas.read_json('student_skill.json'))
candidate_skills.show()
Output:

We can see that the JSON data is converted to PySpark DataFrame with specified columns and rows.
2. Reading JSON to PySpark DataFrame Using Spark.read.json()
The read.json() is a method that is similar to read_json() in Pandas. Here, read.json() takes a path to JSON or directly to JSON file, and directly loads it into the PySpark DataFrame. There is no need to use the createDataFrame() method in this scenario. If you want to read multiple JSON files at a time, we need to pass a list of JSON file names through a list that is separated by comma. All the JSON records are stored in a single DataFrame.
Syntax:
Multiple Files - spark_app.read.json(['file1.json','file2.json',...])
Scenario 1: Read JSON Having Single Line
If your JSON file is in the record1, record2, record3… (single line) formats, we can call it as JSON with single lines. Spark processes these records and stores it in the PySpark DataFrame as rows. Each record is a row in the PySpark DataFrame.
Let’s create a JSON file named “candidate_skills.json” that holds 3 records. Read this JSON into the PySpark DataFrame.
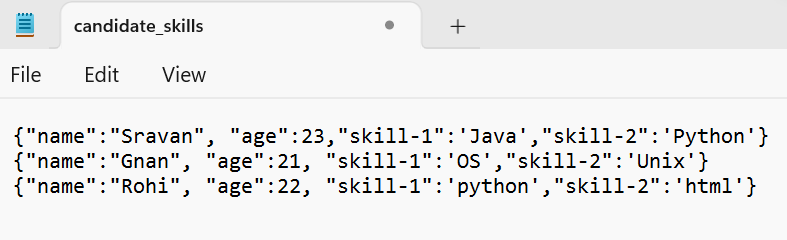
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
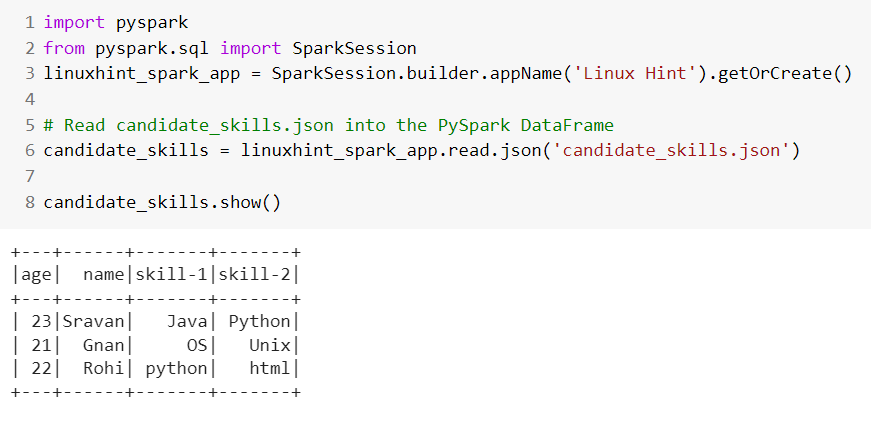
# Read candidate_skills.json into the PySpark DataFrame
candidate_skills = linuxhint_spark_app.read.json('candidate_skills.json')
candidate_skills.show()
Output:
We can see that the JSON data is converted to PySpark DataFrame with specified records and column names.
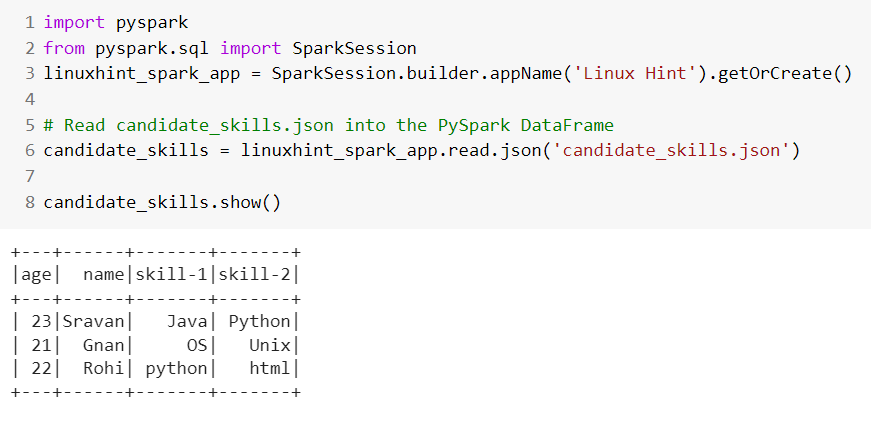
Scenario 2: Read JSON Having Multiple Lines
If your JSON file has multiple lines, you need to use the read.option().json() method to pass the multiline parameter which has to be set to true. This allows us to load JSON having multiple lines into the PySpark DataFrame.
Let’s create a JSON file named “multi.json” that holds 3 records. Read this JSON into the PySpark DataFrame.

from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# Read multi.json (having multiple lines) into the PySpark DataFrame
candidate_skills = linuxhint_spark_app.read.option("multiline","true").json("multi.json")
candidate_skills.show()
Output:
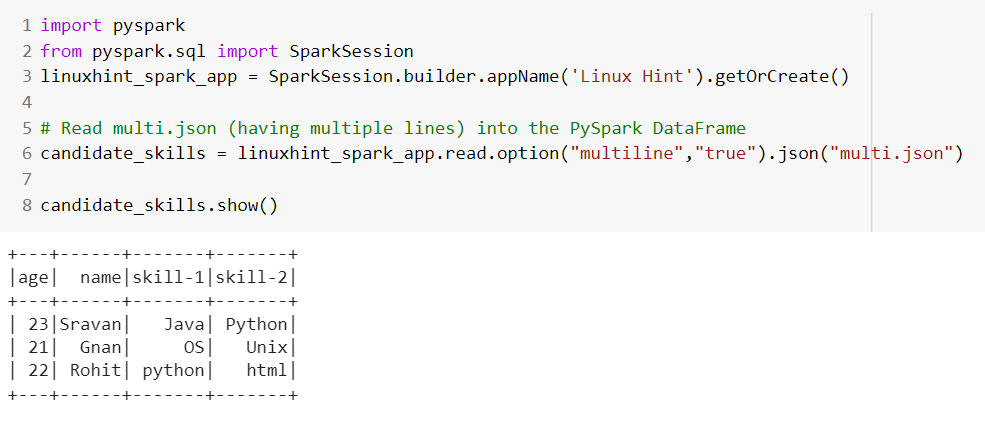
Scenario 3: Read Multiple JSON
We already discussed at the starting phase of this tutorial regarding multiple JSON files. If you want to read multiple JSON files at a time and store them in a single PySpark DataFrame, we need to pass a list of file names to the read.json() method.
Let’s create two JSON files named “candidate_skills.json” and “candidate_skills2.json” and load them into the PySpark DataFrame.
The “candidate_skills.json” file holds three records.

The “candidate_skill2.json” file holds only a single record.

from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# Read candidate_skills and candidate_skills2 files at a time into the PySpark DataFrame
candidate_skills = linuxhint_spark_app.read.json(['candidate_skills.json','candidate_skills2.json'])
candidate_skills.show()
Output:
Finally, the DataFrame holds four records. The first three records belong to the first JSON and the last records belong to the second JSON.
Reading JSON to PySpark DataFrame Using Spark.read.json()
The read.json() is a method that is similar to read_json() in Pandas. Here, read.json() takes a path to JSON or directly to JSON file and loads it directly into the PySpark DataFrame. There is no need to use the createDataFrame() method in this scenario. If you want to read multiple JSON files at a time, we need to pass a list of JSON file names through a list that is separated by comma. All the JSON records are stored in a single DataFrame.
Syntax:
Multiple Files - spark_app.read.json(['file1.json','file2.json',...])
Scenario 1: Read JSON Having Single Line
If your JSON file is in the record1, record2, record3… (single line) format, we can call it as JSON with single lines. Spark processes these records and stores it in the PySpark DataFrame as rows. Each record is a row in the PySpark DataFrame.
Let’s create a JSON file named “candidate_skills.json” that holds 3 records. Read this JSON into the PySpark DataFrame.

from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# Read candidate_skills.json into the PySpark DataFrame
candidate_skills = linuxhint_spark_app.read.json('candidate_skills.json')
candidate_skills.show()
Output:
We can see that the JSON data is converted to PySpark DataFrame with specified records and column names.
Reading JSON to PySpark DataFrame Using the PySpark SQL
It can be possible to create a temporary view of our JSON data using the PySpark SQL. Directly, we can provide the JSON at the time of creating the temporary view. Look at the following syntax. After that, we can use the SELECT command to display the PySpark DataFrame.
Syntax:
Here, the “VIEW_NAME” is the view of the JSON data and the “file_name” is the name of the JSON file.
Example 1:
Consider the JSON file that is used in the previous examples – “candidate_skills.json”. Select all the rows from the DataFrame using SELECT with the “*” operator. Here, * selects all the columns from the PySpark DataFrame.
import pandas
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# Using spark.sql to create VIEW from the JSON
candidate_skills = linuxhint_spark_app.sql("CREATE TEMPORARY VIEW Candidate_data USING json OPTIONS (path 'candidate_skills.json')")
# Use SELECT query to select all records from the Candidate_data.
linuxhint_spark_app.sql("SELECT * from Candidate_data").show()
Output:

The total number of records in the PySpark DataFrame (readed from JSON) is 3.
Example 2:
Now, filter the records in the PySpark DataFrame based on the age column. Use the “greater than” operator on the age to get the rows with an age that is greater than 22.
linuxhint_spark_app.sql("SELECT * from Candidate_data where age>22").show()
Output:

There is only one record in the PySpark DataFrame with an age that is greater than 22.
Conclusion
We learned the three different ways to read the JSON into the PySpark DataFrame. First, we learned how to use the read_json() method that is available in the Pandas module to read JSON to PySpark DataFrame. Next, we learned how to read the single/multi line JSON files using the spark.read.json() method with option(). To read multiple JSON files at a time, we need to pass a list of file names to this method. Using PySpark SQL, the JSON file is read into the temporary view and the DataFrame is displayed using the SELECT query.