Pyspark.sql.DataFrameReader.csv()
This method is used to read the data from the CSV file/s and store them in the PySpark DataFrame. It takes the options while reading CSV into the DataFrame. We will discuss the different options with examples in detail. While passing more than one CSV file, it is important to pass the file names with extension in a list that is separated by the comma operator. If you are reading only one CSV file, there is no need to provide the file name in a list.
Syntax:
Multiple files – spark_app.read.csv([‘file1.csv’,’file2.csv’,…],options…)
It can also be possible to separate the options and file names.
Single file – spark_app.read.options(options…).csv(‘file.csv’)
Multiple files – spark_app.read.options(options…).csv([‘file1.csv’,’file2.csv’,…])
Install the PySpark library before implementing the following examples.
After the successful installation, you can see the output as follows:

Scenario 1: Reading the CSV File Header
Let’s create a CSV file named “person_skill.csv” with 5 records which is shown in the following and load it into the PySpark DataFrame:
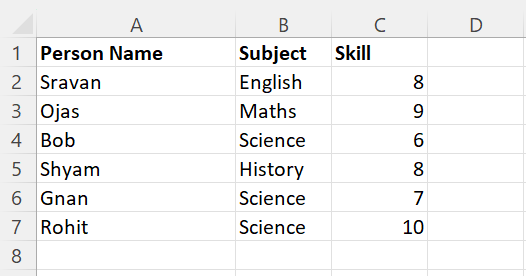
The header parameter is used to specify the column names in the PySpark DataFrame. It takes a Boolean value. If it is “True”, the actual column names that exist in the CSV file are specified in the DataFrame, Otherwise, the c0, c1, c2… are specified and the actual column names will be a row. It is best practiced to set the header parameter to true.
Example 1: Header = True
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# Load the csv named - person_skill.csv into skills with column labels with header
skills = linuxhint_spark_app.read.csv('person_skill.csv',header=True)
# Display the DataFrame
skills.show()
Output:
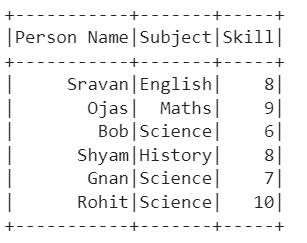
Explanation:
We can see that the PySpark DataFrame is created from the CSV file with specified columns and rows.
Use the following command to check the columns:
![]()
Example 2: Header = False
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# Load the csv named - person_skill.csv into skills with column labels without header
skills = linuxhint_spark_app.read.csv('person_skill.csv',header=False)
# Display the DataFrame
skills.show()
Output:
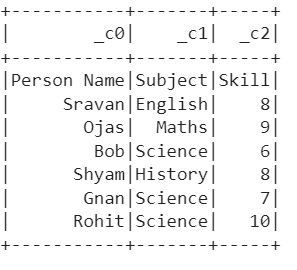
Explanation:
We can see that the PySpark DataFrame is created from the CSV file without existing columns.
Also, the existing columns are stored as rows in the PySpark DataFrame.
![]()
Using the Read.options.csv()
Now, we read the CSV file using the read.options.csv() method. Here, we need to pass the options like delimiter, header, etc in the options as arguments and file name in the csv(). Let’s pass the header parameter by setting it to “True”.
Scenario 1:
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# Using read.options.csv()
skills = linuxhint_spark_app.read.options(header=True).csv('person_skill.csv')
# Display the DataFrame
skills.show()
Output:

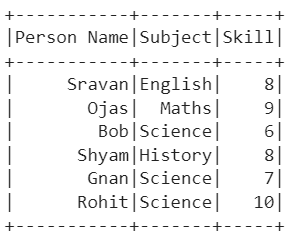
Scenario 2: Reading the CSV File Delimiter
The delimiter parameter takes the character which is used to separate each field. It takes a comma (,) by default. Let’s use the same CSV file that is used in the first scenario and pass the comma (‘,’) as the delimiter.
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# Using read.options.csv() with delimiter along with header
skills = linuxhint_spark_app.read.options(header=True,delimiter=',').csv('person_skill.csv')
# Display the DataFrame
skills.show()
Output:
Reading Multiple Files
Until now, we have been reading a single CSV file. Let’s see how to read more than one CSV file. In this scenario, the rows in multiple files are appended in a single PySpark DataFrame. We just need to pass the file names in a list within the method.
Example:
Let’s have the following CSV files named “person_skill.csv” and “person_skill2.csv” with the following data:

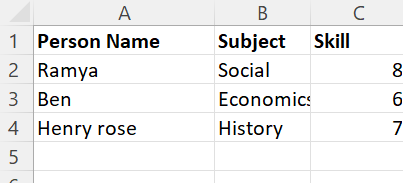
Read these two CSV files and store them in a single PySpark DataFrame.
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# Load 2 csv files named - person_skill.csv and person_skill2.csv into skills with column labels with header
skills = linuxhint_spark_app.read.csv(['person_skill.csv','person_skill2.csv'],sep=',',header=True)
skills.show()
Output:
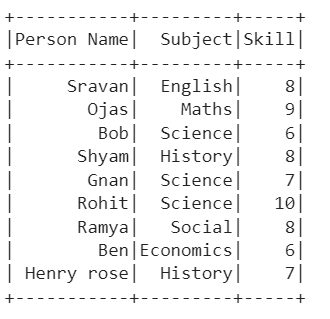
Explanation:
The first CSV holds 6 records and the second CSV holds 3 records. We can see that the first CSV is loaded into the DataFrame first. Then, the second CSV is loaded. Finally, the PySpark DataFrame holds 9 records.
Conclusion
Reading the CSV into the PySpark DataFrame is quite simple with the pyspark.sql.DataFrameReader.csv() method. It can be possible to pass the header and delimiter parameters to this method in order to specify the columns and the format. PySpark also supports reading multiple CSV files at a time with the provided methods along with their options. In this article, we have seen the examples by considering different options. Also, we have seen two ways of passing the options to the method.