PySpark – pandas Series represents the pandas Series, but it holds the PySpark column internally.
Pandas support Series data structure, and pandas is imported from the pyspark module.
Before that, you have to install the pyspark module.”
Command
Syntax to import
After that, we can create or use the series from the pandas module.
Syntax to create pandas Series
We can pass a list or list of lists with values.
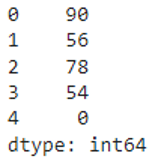
Let’s create a pandas Series through pyspark that has five numeric values.
from pyspark import pandas
#create series with 5 elements
pyspark_series=pandas.Series([90,56,78,54,0])
print(pyspark_series)
Output
Now, we will go into our tutorial.
Aggregate functions are used to perform aggregation operations like sum(), min(),mean() and max().These operations work only on numeric data like integer, double, etc
Let’s see them one by one.
pyspark.pandas.Series.sum()
sum() in the pyspark pandas series is used to return the total sum.
Syntax
Where pyspark_series is the pyspark pandas series.
Example
Return sum of the above pyspark pandas series.
from pyspark import pandas
#create series with 5 elements
pyspark_series=pandas.Series([90,56,78,54,0])
#return sum
print(pyspark_series.sum())
Output:
Working:
90+56+78+54+0=278.
pyspark.pandas.Series.mean()
mean() in the pyspark pandas series is used to return the total average.
Syntax
Where pyspark_series is the pyspark pandas series.
Example
Return average of the above pyspark pandas series.
from pyspark import pandas
#create series with 5 elements
pyspark_series=pandas.Series([90,56,78,54,0])
#return average
print(pyspark_series.mean())
Output
Working:
(90+56+78+54+0)/5=55.6.
pyspark.pandas.Series.min()
min() in the pyspark pandas series is used to return minimum value.
Syntax
Where pyspark_series is the pyspark pandas series.
Example
Return minimum value from the above pyspark pandas series.
from pyspark import pandas
#create series with 5 elements
pyspark_series=pandas.Series([90,56,78,54,0])
#return minimum
print(pyspark_series.min())
Output
Working:
minimum(90+56+78+54+0)=0
pyspark.pandas.Series.max()
max() in the pyspark pandas series is used to return maximum value.
Syntax
Where pyspark_series is the pyspark pandas series.
Example
Return maximum value from the above pyspark pandas series.
from pyspark import pandas
#create series with 5 elements
pyspark_series=pandas.Series([90,56,78,54,0])
#return maximum
print(pyspark_series.max())
Output
Working:
maximum(90+56+78+54+0)=90
Conclusion
In this pyspark pandas series tutorial, we saw four different aggregation functions performed on the series. sum() will return the total sum, avg() is used to return the total average, min() is used to return the minimum value, and max() will return the maximum value.