In this article we will discuss the arithmetic operators available in Pandas and how they can be used in PySpark data frames. Before that, you have to install the pyspark module.
Command
Syntax to import:
After that, we can create or use the dataframe from the pandas module.
Syntax to create pandas DataFrame
We can pass a dictionary or list of lists with values.
Let’s create a pandas DataFrame through pyspark that has three columns and five rows.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({'mark1':[90,78,90,54,67],'mark2':[100,67,96,89,77],'mark3':[91,92,98,97,87]})
#display
print(pyspark_pandas)
Output
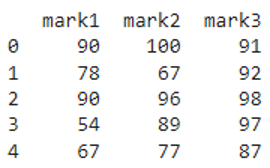
Now, we will go into our tutorial.
Arithmetic operations are used to perform operations like addition, subtraction, multiplication, division, and modulus. Pyspark pandas dataframe supports built-in functions that are used to perform these operations.
Let’s see one by one.
pyspark.pandas.DataFrame.add()
add() in pyspark pandas dataframe is used to add elements in the entire dataframe with a value.
It is also possible to add a value in a single column. It takes the value as a parameter.
Syntax
For entire pyspark pandas dataframe
For particular column
Where,
- pyspark_pandas is the pyspark pandas dataframe
- value that takes numeric value to be added to the pyspark_pandas.
Example 1
In this example, we will add 5 to the mark1 column.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({'mark1':[90,78,90,54,67],'mark2':[100,67,96,89,77],'mark3':[91,92,98,97,87]})
#add values in mark1 column with 5
print(pyspark_pandas.mark1.add(5))
Output
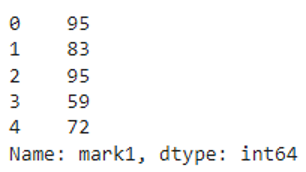
We can see that 5 is added to each value in the mark1 column.
Example 2
In this example, we will add 5 to the entire pyspark pandas dataframe.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({'mark1':[90,78,90,54,67],'mark2':[100,67,96,89,77],'mark3':[91,92,98,97,87]})
#add 5 to the entire dataframe
print(pyspark_pandas.add(5))
Output
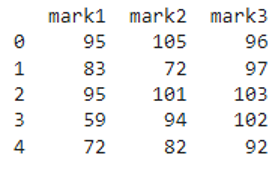
We can see that 5 is added to the entire pyspark pandas dataframe.
pyspark.pandas.DataFrame.sub()
sub() in pyspark pandas dataframe is used to subtract elements from the entire dataframe with a value.
It is also possible to subtract from a single column. It takes the value as a parameter.
Syntax
For entire pyspark pandas dataframe
For particular column
Where,
- pyspark_pandas is the pyspark pandas dataframe
- value that takes numeric value to be subtracted from the pyspark_pandas.
Example 1
In this example, we will subtract 5 from the mark1 column.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({'mark1':[90,78,90,54,67],'mark2':[100,67,96,89,77],'mark3':[91,92,98,97,87]})
#subtract values in mark1 column with 5
print(pyspark_pandas.mark1.sub(5))
Output

We can see that 5 is subtracted from each value in the mark1 column.
Example 2
In this example, we will subtract 5 from the entire pyspark pandas dataframe.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({'mark1':[90,78,90,54,67],'mark2':[100,67,96,89,77],'mark3':[91,92,98,97,87]})
#subtract 5 from the entire dataframe
print(pyspark_pandas.sub(5))
Output
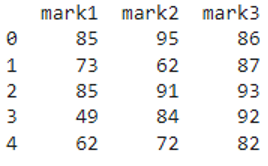
We can see that 5 is subtracted from the entire pyspark pandas dataframe.
pyspark.pandas.DataFrame.mul()
mul() in the pyspark pandas dataframe is used to multiply elements in the entire dataframe with a value.
It is also possible to multiply a value in a single column. It takes the value as a parameter.
Syntax
For entire pyspark pandas dataframe
For particular column
Where,
- pyspark_pandas is the pyspark pandas dataframe
- value that takes numeric value to be multiplied with the pyspark_pandas.
Example 1
In this example, we will multiply all values in the mark1 column with 5.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({'mark1':[90,78,90,54,67],'mark2':[100,67,96,89,77],'mark3':[91,92,98,97,87]})
#subtract 5 from the entire dataframe
print(pyspark_pandas.sub(5))
Output
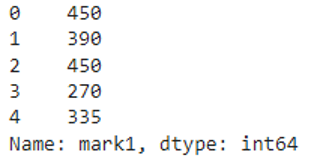
We can see that 5 is multiplied with each value in the mark1 column.
Example 2
In this example, we will multiply the entire pyspark pandas dataframe by 5.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({'mark1':[90,78,90,54,67],'mark2':[100,67,96,89,77],'mark3':[91,92,98,97,87]})
#multiply entire dataframe with 5
print(pyspark_pandas.mul(5))
Output
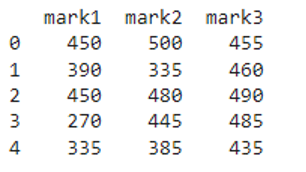
We can see that the entire pyspark pandas dataframe is multiplied by 5.
pyspark.pandas.DataFrame.div()
div() in pyspark pandas dataframe is used to divide elements in the entire dataframe with a value.
It is also possible to divide by value in a single column. It takes the value as a parameter. It returns a quotient.
Syntax
For entire pyspark pandas dataframe
For particular column
Where,
- pyspark_pandas is the pyspark pandas dataframe
- value that takes numeric value to be divided with the pyspark_pandas.
Example 1
In this example, we will divide all values in the mark1 column by 5.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({'mark1':[90,78,90,54,67],'mark2':[100,67,96,89,77],'mark3':[91,92,98,97,87]})
#divide mark1 column with 5
print(pyspark_pandas.mark1.div(5))
Output
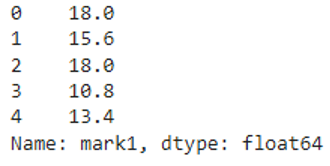
We can see that each value in the mark1 column is divided by 5.
Example 2
In this example, we will divide the entire pyspark pandas dataframe by 5.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({'mark1':[90,78,90,54,67],'mark2':[100,67,96,89,77],'mark3':[91,92,98,97,87]})
#divide entire dataframe by 5
print(pyspark_pandas.div(5))
Output
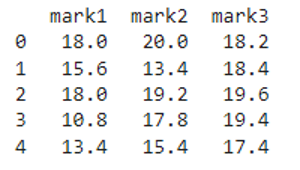
We can see that the entire pyspark pandas dataframe is divided by 5.
pyspark.pandas.DataFrame.mod()
mod() in pyspark pandas dataframe is used to divide elements in the entire dataframe with a value. It will return the remainder.
It is also possible to divide by value in a single column. It takes the value as a parameter.
Syntax
For entire pyspark pandas dataframe
For particular column
Where,
- pyspark_pandas is the pyspark pandas dataframe
- value that takes numeric value to be divided with the pyspark_pandas.
Example 1
In this example, we will divide all values in the mark1 column by 5.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({'mark1':[90,78,90,54,67],'mark2':[100,67,96,89,77],'mark3':[91,92,98,97,87]})
#divide mark1 column with 5
print(pyspark_pandas.mark1.mod(5))
Output
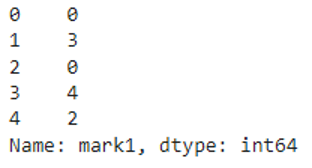
We can see that each value in the mark1 column is divided by 5 and returned the remainder.
Example 2
In this example, we will divide the entire pyspark pandas dataframe by 5.
from pyspark import pandas
#create dataframe from pandas pyspark
pyspark_pandas=pandas.DataFrame({'mark1':[90,78,90,54,67],'mark2':[100,67,96,89,77],'mark3':[91,92,98,97,87]})
#divide entire dataframe by 5
print(pyspark_pandas.mod(5))
Output
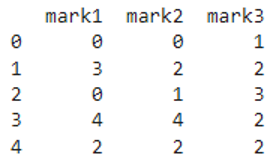
We can see that the entire pyspark pandas dataframe is divided by 5 and returned the remainder.
Conclusion
In this pyspark pandas tutorial, we discussed arithmetic operations performed on the pyspark pandas dataframe. add() is used to add all the values in the entire dataframe with 5, and sub() is used to subtract values from the entire pyspark pandas dataframe. mul() is used to multiply all the values in the entire dataframe with a value, and div() is used to divide all the values by a value in the pyspark pandas dataframe and return the quotient. mod() is used to divide all the values by a value in the pyspark pandas dataframe and return the remainder. The difference between mod() and div() is mod() returns remainder but div() returns quotient.