In Python, PySpark is a Spark module used to provide a similar kind of processing like spark using DataFrame. Lit() is used create a new column by adding values to that column in PySpark DataFrame. Before moving to the syntax, we will create PySpark DataFrame.
Example:
Here, we are going to create PySpark dataframe with 5 rows and 6 columns.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,
'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#display the dataframe
df.show()
Output:

lit() – Syntax
Where,
- column_name is the new column.
- value is the constant value added to the new column.
We have to import this method from pyspark.sql.functions module.
Note: We can add multiple columns at a time
Using select() method, we can use lit() method.
Select() is used to display the columns from the dataframe. Along with that we can add column/s using lit() method.
Syntax:
Where,
- column is the existing column name to display.
- new_column is the new column name to be added.
- value is the constant value added to the new column.
Example 1:
In this example, we are going to add a new column named – PinCode and add a constant value – 522112 to this column and select rollno column along with PinCode from the PySpark DataFrame.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col,lit function
from pyspark.sql.functions import col,lit
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,
'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
# add a new column PinCode with Constant value - 522112
final = df.select(col("rollno"),lit("522112").alias("PinCode"))
#display the final dataframe
final.show()
Output:

Example 2:
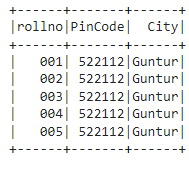
In this example, we are going to add new columns named – PinCode and City and add a constant value – 522112 and Guntur to these columns and select rollno column along with PinCode and City from the PySpark DataFrame.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col,lit function
from pyspark.sql.functions import col,lit
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,
'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
# add a new columns: PinCode with Constant value - 522112
# city with constant value - Guntur
final = df.select(col("rollno"),lit("522112").alias("PinCode"),lit("Guntur").alias("City"))
#display the final dataframe
final.show()
Output:
We can also add values to the new column from the existing column vales. We just need to provide the column name inside lit(value) parameter.
Syntax:
Where,
- dataframe is the input PySpark DataFrame.
- column is the existing column name to display.
- new_column is the new column name to be added.
- value is the constant value added to the new column.
Example:
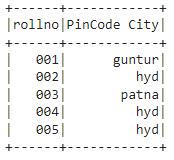
In this example, we are going to add a column – “PinCode City” and assign values from address column.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col,lit function
from pyspark.sql.functions import col,lit
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,
'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
# add a new column: "PinCode City from address column
final = df.select(col("rollno"),lit(df.address).alias("PinCode City"))
#display the final dataframe
final.show()
Output:
We can also add existing column values through column index – column indexing starts with – 0.
Example:
In this example, we are going to add a column – “PinCode City” and assign values from address column through address column index i.e., – 4.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col,lit function
from pyspark.sql.functions import col,lit
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,'height':2.79,'weight':17,
'address':'patna'},
{'rollno':'004','name':'rohith','age':9,'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
# add a new column: "PinCode City from address column
final = df.select(col("rollno"),lit(df[4]).alias("PinCode City"))
#display the final dataframe
final.show()
Output:
Conclusion
In this tutorial, we discussed the lit() method for creating a new column with constant values. It can be possible to assign the values from the existing column by specifying the column in place of value parameter through column name as well as a column index.