They can be used with either the filter clause or where clause. We will see them one by one with different examples.
like() Function
The like() function in PySpark is used to check if a string or a pattern exists in a column of PySpark DataFrame. If it exists, the matched rows will be returned. Otherwise, an empty DataFrame is returned. It is case-sensitive.
Syntax
dataframe_object.where(dataframe_obj.column.like(pattern/string))
Where,
dataframe_object is the PySpark DataFrame.
Parameter:
The like() function has one parameter.
It can be a pattern or a string such that the like() function will check if the specified value is present in the DataFrame column or not.
Return:
Based on this column value, the entire row is returned.
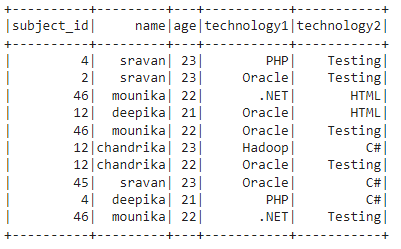
First, we will create the PySpark DataFrame with 10 rows and 5 columns.
from pyspark.sql import *
spark_app = SparkSession.builder.appName('_').getOrCreate()
students =[(4,'sravan',23,'PHP','Testing'),
(2,'sravan',23,'Oracle','Testing'),
(46,'mounika',22,'.NET','HTML'),
(12,'deepika',21,'Oracle','HTML'),
(46,'mounika',22,'Oracle','Testing'),
(12,'chandrika',23,'Hadoop','C#'),
(12,'chandrika',22,'Oracle','Testing'),
(45,'sravan',23,'Oracle','C#'),
(4,'deepika',21,'PHP','C#'),
(46,'mounika',22,'.NET','Testing')
]
dataframe_obj = spark_app.createDataFrame( students,['subject_id','name','age','technology1','technology2'])
dataframe_obj.show()
Output:
Now, let’s apply the like() function on the PySpark DataFrame to return the results.
Example 1
We will provide the string, ‘sravan’, in the name column inside the like() method and return all rows matching this string.
print("--------Using where() clause--------")
dataframe_obj.where(dataframe_obj.name.like('sravan')).show()
#check for string- sravan in the name column and return rows with the name - sravan.
print("--------Using filter() clause--------")
dataframe_obj.filter(dataframe_obj.name.like('sravan')).show()
Output:
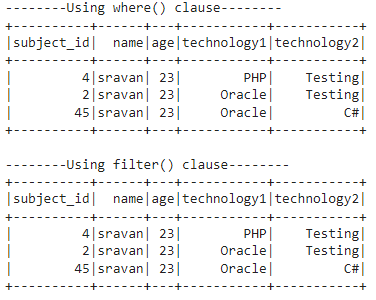
You can see that sravan is found three times, and rows were returned.
Example 2
We will provide the string, ‘pHP’, in the technology1 column inside the like() method and return all rows matching this string.
print("--------Using where() clause--------")
dataframe_obj.where(dataframe_obj.technology1.like('pHP')).show()
#check for string- pHP in the technology1 column and return rows with technology1 - pHP.
print("--------Using filter() clause--------")
dataframe_obj.filter(dataframe_obj.technology1.like('pHP')).show()
Output:

You can see that pHP is not found in the technology1 column. Hence, 0 rows were returned.
ilike() Function
The ilike() function in PySpark is used to check if a string or a pattern exists in a column of PySpark DataFrame. If it exists, the matched rows will be returned. Otherwise, the empty DataFrame is returned. It is case-insensitive.
Syntax
dataframe_object.where(dataframe_obj.column.ilike(pattern/string))
Where,
dataframe_object is the PySpark DataFrame.
Parameter:
The ilike() function has one parameter.
It can be a pattern or a string such that the ilike() function will check if the specified value is present in the DataFrame column or not.
Return:
Based on this column value, the entire row is returned.
Example 1
We will provide the string, ‘sravan’, in the name column inside the ilike() method and return all rows matching this string.
print("--------Using where() clause--------")
dataframe_obj.where(dataframe_obj.name.ilike('sravan')).show()
#check for string- sravan in the name column and return rows with the name - sravan.
print("--------Using filter() clause--------")
dataframe_obj.filter(dataframe_obj.name.ilike('sravan')).show()
Output:
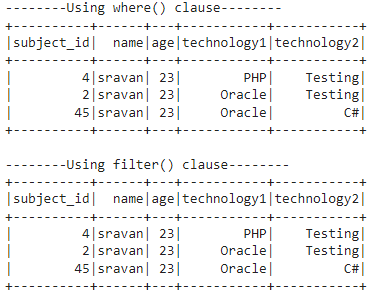
Explanation
You can see that sravan is found three times and rows were returned.
Example 2
We will provide the string, ‘pHP’, in the technology1 column inside the like() method and return all rows matching this string.
print("--------Using where() clause--------")
dataframe_obj.where(dataframe_obj.technology1.ilike('pHP')).show()
#check for string- pHP in technology1 column and return rows with technology1 - pHP.
print("--------Using filter() clause--------")
dataframe_obj.filter(dataframe_obj.technology1.ilike('pHP')).show()
Output:
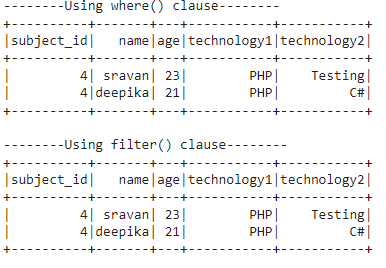
Explanation
You can see that pHP is not found in the technology1 column. But ilike() is case-insensitive. So, it takes PHP and pHP as the same. So, the rows were returned.
Conclusion
In this PySpark tutorial, we saw two functions that return values based on the string match in the PySpark DataFrame column. The like() and ilike() functions are used to check if a string or a pattern exists in a column of PySpark DataFrame. The difference is like() is case-sensitive and ilike() is case-insensitive.