Syntax:
Parameter:
It takes columns as parameters.
We can access the columns using the “.” operator (column1,column2,. represents the column names).
Data:
Here, we create a PySpark DataFrame that has 5 columns -[‘subject_id’,’name’,’age’,’technology1′,’technology2′] with 10 rows.
from pyspark.sql import SparkSession
spark_app = SparkSession.builder.appName('_').getOrCreate()
students =[(4,'sravan',23,'PHP','Testing'),
(4,'sravan',23,'PHP','Testing'),
(46,'mounika',22,'.NET','HTML'),
(4,'deepika',21,'Oracle','HTML'),
(46,'mounika',22,'Oracle','Testing'),
(12,'chandrika',22,'Hadoop','C#'),
(12,'chandrika',22,'Oracle','Testing'),
(4,'sravan',23,'Oracle','C#'),
(4,'deepika',21,'PHP','C#'),
(46,'mounika',22,'.NET','Testing')
]
dataframe_obj = spark_app.createDataFrame( students,['subject_id','name','age','technology1','technology2'])
print("----------DataFrame----------")
dataframe_obj.show()
Output:
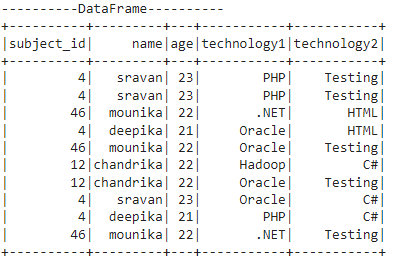
Now, we will see the examples to return the greatest values in two or multiple columns from the previous DataFrame.
Example 1:
We created the given DataFrame. Now, we return the greatest values from the subject_id and age columns.
from pyspark.sql.functions import greatest
#compare the columns - subject_id and age and return greatest values across each and every row.
dataframe_obj.select(dataframe_obj.subject_id,dataframe_obj.age,greatest(dataframe_obj.subject_id,dataframe_obj.age)).show()
Output:
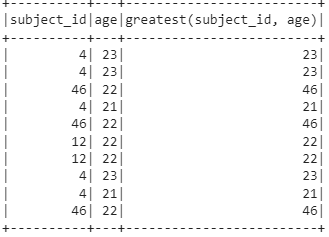
Explanation:
You can compare the two column values in each row.
greatest(4,23) - 23
greatest(46,22) -46
greatest(4,21) - 21
greatest(46,22) - 46
greatest(12,22) - 22
greatest(12,22) - 22
greatest(4,23) - 23
greatest(4,21) - 21
greatest(46,22) - 46.
Example 2:
We created the given DataFrame. Now, we return the greatest values from the name , technology1, and technology2 columns.
from pyspark.sql.functions import greatest
#compare the columns - name,technology1,technology2 and age and return greatest values across each and every row.
dataframe_obj.select(dataframe_obj.name,dataframe_obj.technology1,dataframe_obj.technology2,
greatest(dataframe_obj.name,dataframe_obj.technology1,dataframe_obj.technology2)).show()
Output:
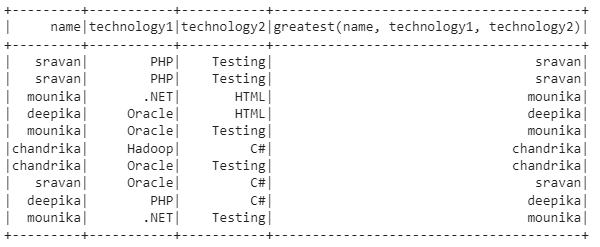
Here, the strings are compared based on the ASCII values.
greatest(sravan,PHP,Testing) - sravan
greatest(mounika, .NET,HTML) - mounika
greatest(deepika, Oracle,HTML) - deepika
greatest(mounika, Oracle,Testing) - mounika
greatest(chandrika, Hadoop, C#) - chandrika
greatest(chandrika,Oracle,Testing) - chandrika
greatest(sravan,Oracle,C#) - sravan
greatest(deepika, PHP, C#) - deepika
greatest(mounika,.NET,Testing) -mounika.
Entire Code:
from pyspark.sql import SparkSession
spark_app = SparkSession.builder.appName('_').getOrCreate()
students =[(4,'sravan',23,'PHP','Testing'),
(4,'sravan',23,'PHP','Testing'),
(46,'mounika',22,'.NET','HTML'),
(4,'deepika',21,'Oracle','HTML'),
(46,'mounika',22,'Oracle','Testing'),
(12,'chandrika',22,'Hadoop','C#'),
(12,'chandrika',22,'Oracle','Testing'),
(4,'sravan',23,'Oracle','C#'),
(4,'deepika',21,'PHP','C#'),
(46,'mounika',22,'.NET','Testing')
]
dataframe_obj = spark_app.createDataFrame( students,['subject_id','name','age','technology1','technology2'])
print("----------DataFrame----------")
dataframe_obj.show()
# Import the greatest function from the module - pyspark.sql.functions
from pyspark.sql.functions import greatest
#compare the columns - subject_id and age and return greatest values across each and every row.
dataframe_obj.select(dataframe_obj.subject_id,dataframe_obj.age,greatest(dataframe_obj.subject_id,dataframe_obj.age)).show()
#compare the columns - name,technology1,technology2 and age and return greatest values across each and every row.
dataframe_obj.select(dataframe_obj.name,dataframe_obj.technology1,dataframe_obj.technology2,
greatest(dataframe_obj.name,dataframe_obj.technology1,dataframe_obj.technology2)).show()
Conclusion
The greatest() function is used to find the highest values in multiple columns across all the rows in a PySpark RDD or in a PySpark DataFrame. It compares the columns with similar data types only. Otherwise, it raises the Analysis Exception – The expressions should all have the same type.