By using these methods, we can define the column names and the data types of the columns.
StructType()
This method is used to define the structure of the PySpark data frame. It will accept a list of data types along with column names for the given dataframe. This is known as the schema of the dataframe. It stores a collection of fields
StructField()
This method is used inside the StructType() method of the PySpark dataframe. It will accept column names with the data type.
ArrayType()
This method is used to define the array structure of the PySpark dataframe. It will accept a list of data types. It stores a collection of fields. We can place datatypes inside ArrayType(). In this article, we have to create a dataframe with an array.
Let’s create a dataframe with 2 columns. First column is Student_category which refers to the integer field to store student ids. The second column – Student_full_name is used to store string values in an array created using ArrayType().
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and other data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType,ArrayType
from pyspark.sql.functions import array_contains
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# consider an array with 5 elements
my_array_data = [(1, ['A']), (2, ['B','L','B']), (3, ['K','A','K']),(4, ['K']),
(3, ['B','P'])]
#define the StructType and StructFields
#for the above data
schema = StructType([StructField("Student_category", IntegerType()),StructField("Student_full_name", ArrayType(StringType()))])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(my_array_data, schema=schema)
df.show()
Output:

explode()
Now, we will see what explode() does. explode() will return each and every individual value from an array. If the array is empty or null, it will ignore and go to the next array in an array type column in PySpark DataFrame. This is possible using the select() method. Inside this method, we can use the array_min() function and return the result.
Syntax:
Parameters:
— array_column: contains array type values
Return:
— It will return all the values in an array in all rows in an array type column in a PySpark DataFrame.
Example 1:
In this example, we will return all the values in an array from the Student_full_name column.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and other data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType,ArrayType
from pyspark.sql.functions import *
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# consider an array with 5 elements
my_array_data = [(1, ['A']), (2, ['B','L','B']), (3, ['K','A','K']),
(4, ['K']), (3, ['B','P'])]
#define the StructType and StructFields
#for the above data
schema = StructType([StructField("Student_category", IntegerType()),StructField("Student_full_name", ArrayType(StringType()))])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(my_array_data, schema=schema)
# apply explode on the Student_full_name column
df.select("Student_full_name",explode('Student_full_name')).show()
Output:

We can see that in the 2nd column, each value in the array from each row is returned.
Now, let’s see what if array values are empty.
Example 2:
This dataframe has no values in the array.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and other data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType,ArrayType
from pyspark.sql.functions import *
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# consider an array with 5 elements
my_array_data = [(1, []), (2, []), (3, []),(4, []), (3, [])]
#define the StructType and StructFields
#for the above data
schema = StructType([StructField("Student_category", IntegerType()),StructField("Student_full_name", ArrayType(StringType()))])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(my_array_data, schema=schema)
# explode the Student_full_name column
df.select("Student_full_name",explode('Student_full_name')).show()
Output:
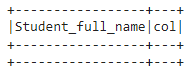
It returns nothing since all the values are missing in the array column – Student_full_name.
explode_outer()
Now, we will see what explode_outer() does. explode_outer() will return each and every individual value from an array. If the array is empty or null, it returns null and go to the next array in an array type column in PySpark DataFrame. This is possible using the select() method. Inside this method, we can use the array_min() function and return the result.
Syntax:
Parameters:
— array_column: contains array type values
Return:
— It will return all the values in an array in all rows in an array type column in a PySpark DataFrame.
The difference between explode() and explode_outer() is that, explode() won’t return anything when there are no values in the array. But explode_outer() return null when there are no values in the array.
Example 1:
In this example, we will return all the values in an array from the Student_full_name column.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and other data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType,ArrayType
from pyspark.sql.functions import *
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# consider an array with 5 elements
my_array_data = [(1, ['A']), (2, ['B','L','B']), (3, ['K','A','K']),
(4, ['K']), (3, ['B','P'])]
#define the StructType and StructFields
#for the above data
schema = StructType([StructField("Student_category", IntegerType()),StructField("Student_full_name", ArrayType(StringType()))])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(my_array_data, schema=schema)
# apply explode_outer on the Student_full_name column
df.select("Student_full_name",explode_outer('Student_full_name')).show()
Output:

Now, let’s see what if array values are empty.
Example 2:
This dataframe has no values in the array.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and other data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType,ArrayType
from pyspark.sql.functions import *
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# consider an array with 5 elements
my_array_data = [(1, []), (2, []), (3, []),(4, []), (3, [])]
#define the StructType and StructFields
#for the above data
schema = StructType([StructField("Student_category", IntegerType()),StructField("Student_full_name", ArrayType(StringType()))])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(my_array_data, schema=schema)
# apply explode_outer the Student_full_name column
df.select("Student_full_name",explode_outer('Student_full_name')).show()
Output:
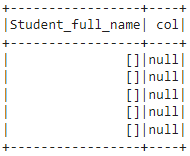
It returns null in all rows since all the values are missing in the array column- Student_full_name.
Conclusion
In this article, we discussed explode() and explode_outer() applied on array type column in the DataFrame with two different examples. explode() and explode_outer() will perform some action when all the values in the array are not null. If any value in an array is null, explode() will ignore that null value. But explode_outer() will consider and return null value wherever null value is present in the array.