dropna() in PySpark is used to remove the Null values from the DataFrame.
Before discussing this method, we have to create PySpark DataFrame for demonstration. We can create Null values using None value.
Example:
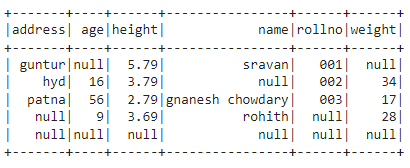
We are going to create a dataframe with 5 rows and 6 columns with null values and display it using the show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':None,'age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':56,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':None,'name':'rohith','age':9,
'height':3.69,'weight':28,'address':None},
{'rollno':None,'name':None,'age':None,
'height':None,'weight':None,'address':None}]
# create the dataframe
df = spark_app.createDataFrame( students)
#display the dataframe
df.show()
Output:
Syntax:
Where,
dataframe is the input PySpark dataframe
how is the first optional parameter which will take two possible values:
—any – This value drops the rows, if any of the value is null in rows/columns.
—all – This value drops the rows, if all the values are null in rows/columns.
thresh is a second optional parameter is used to drop the rows / columns based on integer value assigned to it. If the Non-Null values present in row/column of the PySpark DataFrame are less than the mentioned thresh value, then the null values can be dropped from those rows.
subset is a third optional parameter used to drop the values from the mentioned column/s. It will take single/multiple columns as input through a tuple of column names.
Example 1:
In this example, we are dropping the rows from the above-created dataframe with No parameters and displaying the dataframe using the show() method. So, the result will be the last row because it contains no null values in that row.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':None,'age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':56,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':None,'name':'rohith','age':9,
'height':3.69,'weight':28,'address':None},
{'rollno':None,'name':None,'age':None,
'height':None,'weight':None,'address':None}]
# create the dataframe
df = spark_app.createDataFrame( students)
#drop the dataframe with no parameters
df.dropna().show()
Output:

Example 2:
In this example, we are dropping the rows from the above-created dataframe by specifying how parameter and set to ‘all’ and displaying the dataframe using the show() method. So, the result will be all rows except the last row because it contains all the null values.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':None,'age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':56,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':None,'name':'rohith','age':9,
'height':3.69,'weight':28,'address':None},
{'rollno':None,'name':None,'age':None,
'height':None,'weight':None,'address':None}]
# create the dataframe
df = spark_app.createDataFrame( students)
#drop the dataframe with how parameter
df.dropna(how='all').show()
Output:

Example 3:
In this example, we are dropping the rows from the above-created dataframe by specifying how parameter and set to ‘any’ and displaying the dataframe using the show() method. So, the result will be a single row that contains no null values.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':None,'age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':56,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':None,'name':'rohith','age':9,
'height':3.69,'weight':28,'address':None},
{'rollno':None,'name':None,'age':None,
'height':None,'weight':None,'address':None}]
# create the dataframe
df = spark_app.createDataFrame( students)
#drop the dataframe with how parameter
df.dropna(how='any').show()
Output:

Example 4:
In this example, we are dropping the rows from the above-created dataframe by specifying thresh parameter and set to 5 and displaying the dataframe using the show() method. So, the result will be two rows, because these rows have greater than 5 non-Null values.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':None,'age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':56,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':None,'name':'rohith','age':9,
'height':3.69,'weight':28,'address':None},
{'rollno':None,'name':None,'age':None,
'height':None,'weight':None,'address':None}]
# create the dataframe
df = spark_app.createDataFrame( students)
#drop the dataframe with thresh parameter
df.dropna(thresh=5).show()
Output:

Example 5:
In this example, we are dropping the rows from the above-created dataframe by specifying subset parameter and assign “weight” column and displaying the dataframe using the show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':None,'age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':56,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':None,'name':'rohith','age':9,
'height':3.69,'weight':28,'address':None},
{'rollno':None,'name':None,'age':None,
'height':None,'weight':None,'address':None}]
# create the dataframe
df = spark_app.createDataFrame( students)
#drop the dataframe with subset parameter
df.dropna(subset="weight").show()
Output:

Example 6:
In this example, we are dropping the rows from the above-created dataframe by specifying subset parameter and assign “weight” and “name” columns and displaying the dataframe using the show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the col function
from pyspark.sql.functions import col
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':None,'age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':56,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':None,'name':'rohith','age':9,
'height':3.69,'weight':28,'address':None},
{'rollno':None,'name':None,'age':None,
'height':None,'weight':None,'address':None}]
# create the dataframe
df = spark_app.createDataFrame( students)
#drop the dataframe with subset parameter
df.dropna(subset=("weight","name")).show()
Output:

Conclusion
In this article, we elaborated on how to use the dropna() method with PySpark DataFrame by considering all the parameters. We can also drop all the null values from the DataFrame without specifying these parameters.