Topic of Contents:
- PySpark DataFrame to JSON Using To_json() with ToPandas()
- PySpark DataFrame to JSON Using ToJSON()
- PySpark DataFrame to JSON Using Write.json()
Let’s consider a simple PySpark DataFrame in all the examples and convert it into JSON using the mentioned functions.
Required Module:
Install the PySpark library in your environment if it is not yet installed. You can refer to the following command to install it:
PySpark DataFrame to JSON Using To_json() with ToPandas()
The to_json() method is available in the Pandas module which converts the Pandas DataFrame to JSON. We can utilize this method if we convert our PySpark DataFrame to Pandas DataFrame. In order to convert the PySpark DataFrame to Pandas DataFrame, the toPandas() method is used. Let’s see the syntax of to_json() along with its parameters.
Syntax:
- Orient is used to display the converted JSON as the desired format. It takes “records”, “table”, “values”, “columns”, “index”, “split”.
- Index is used to include/remove the index from the converted JSON string. If it is set to “True”, the indices are displayed. Otherwise, the indices won’t be displayed if the orient is “split” or “table”.
Example 1: Orient as “Records”
Create a “skills_df” PySpark DataFrame with 3 rows and 4 columns. Convert this DataFrame to JSON by specifying the orient parameter as “records”.
import pandas
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# skills data with 3 rows and 4 columns
skills =[{'id':123,'person':'Honey','skill':'painting','prize':25000},
{'id':112,'person':'Mouni','skill':'dance','prize':2000},
{'id':153,'person':'Tulasi','skill':'reading','prize':1200}
]
# create the skills dataframe from the above data
skills_df = linuxhint_spark_app.createDataFrame(skills)
# Actual skills data
skills_df.show()
# Convert to JSON using to_json() with orient as 'records'
json_skills_data = skills_df.toPandas().to_json(orient='records')
print(json_skills_data)
Output:
| id|person|prize| skill|
+---+------+-----+--------+
|123| Honey|25000|painting|
|112| Mouni| 2000| dance|
|153|Tulasi| 1200| reading|
+---+------+-----+--------+
[{"id":123,"person":"Honey","prize":25000,"skill":"painting"},{"id":112,"person":"Mouni","prize":2000,"skill":"dance"},{"id":153,"person":"Tulasi","prize":1200,"skill":"reading"}]
We can see that the PySpark DataFrame is converted to the JSON array with a dictionary of values. Here, the keys represent the column name and the value represents the row/cell value in the PySpark DataFrame.
Example 2: Orient as “Split”
The JSON format that is returned by the “split” orient includes the column names which have a list of columns, list of index, and list of data. The following is the format of the “split” orient.

json_skills_data = skills_df.toPandas().to_json(orient='split')
print(json_skills_data)
Output:
Example 3: Orient as “Index”
Here, each row from the PySpark DataFrame is retired in the form of a dictionary with the key as the column name. For each dictionary, the index position is specified as a key.

json_skills_data = skills_df.toPandas().to_json(orient='index')
print(json_skills_data)
Output:
Example 4: Orient as “Columns”
Columns are the key for each record. Each column holds a dictionary that takes the column values with index numbers.

json_skills_data = skills_df.toPandas().to_json(orient='columns')
print(json_skills_data)
Output:
Example 5: Orient as “Values”
If you need only the values in JSON, you can go for the “values” orient. It displays each row in a list. Finally, all the lists are stored in a list. This JSON is of the nested list type.

json_skills_data = skills_df.toPandas().to_json(orient='values')
print(json_skills_data)
Output:
Example 6: Orient as “Table”
The “table” orient returns the JSON that includes the schema with field names along with the column data types, the index as a primary key and the Pandas version. The column names with values are displayed as “data”.

json_skills_data = skills_df.toPandas().to_json(orient='table')
print(json_skills_data)
Output:
Example 7: With Index Parameter
First, we pass the index parameter by setting it to “True”. You will see for each column value that the index position is returned as a key in a dictionary.
In the second output, only the column names (“columns”) and records (“data”) are returned without the index positions since the index is set to “False”.
json_skills_data = skills_df.toPandas().to_json(index=True)
print(json_skills_data,"\n")
# Convert to JSON using to_json() with index=False
json_skills_data= skills_df.toPandas().to_json(index=False,orient="split")
print(json_skills_data)
Output:
{"columns":["id","person","prize","skill"],"data":[[123,"Honey",25000,"painting"],[112,"Mouni",2000,"dance"],[153,"Tulasi",1200,"reading"]]
PySpark DataFrame to JSON Using ToJSON()
The toJSON() method is used to convert the PySpark DataFrame to a JSON object. Basically, it returns a JSON string which is surrounded by a list. The [‘{column:value,…}’,…. ] is the format that is returned by this function. Here, each row from the PySpark DataFrame is returned as a dictionary with the column name as the key.
Syntax:
It can be possible to pass the parameters like the index, column labels, and data type.
Example:
Create a “skills_df” PySpark DataFrame with 5 rows and 4 columns. Convert this DataFrame to JSON using the toJSON() method.
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# skills data with 5 rows and 4 columns
skills =[{'id':123,'person':'Honey','skill':'painting','prize':25000},
{'id':112,'person':'Mouni','skill':'music/dance','prize':2000},
{'id':153,'person':'Tulasi','skill':'reading','prize':1200},
{'id':173,'person':'Ran','skill':'music','prize':2000},
{'id':43,'person':'Kamala','skill':'reading','prize':10000}
]
# create the skills dataframe from the above data
skills_df = linuxhint_spark_app.createDataFrame(skills)
# Actual skills data
skills_df.show()
# Convert to JSON array
json_skills_data = skills_df.toJSON().collect()
print(json_skills_data)
Output:
| id|person|prize| skill|
+---+------+-----+-----------+
|123| Honey|25000| painting|
|112| Mouni| 2000|music/dance|
|153|Tulasi| 1200| reading|
|173| Ran| 2000| music|
| 43|Kamala|10000| reading|
+---+------+-----+-----------+
['{"id":123,"person":"Honey","prize":25000,"skill":"painting"}', '{"id":112,"person":"Mouni","prize":2000,"skill":"music/dance"}', '{"id":153,"person":"Tulasi","prize":1200,"skill":"reading"}', '{"id":173,"person":"Ran","prize":2000,"skill":"music"}', '{"id":43,"person":"Kamala","prize":10000,"skill":"reading"}']
There are 5 rows in the PySpark DataFrame. All these 5 rows are returned as a dictionary of strings which are separated by comma.
PySpark DataFrame to JSON Using Write.json()
The write.json() method is available in PySpark which writes/saves the PySpark DataFrame to a JSON file. It takes the file name/path as a parameter. Basically, it returns the JSON in multiple files (partitioned files). To merge all of them in a single file, we can use the coalesce() method.
Syntax:
- Append Mode – dataframe_object.write.mode(‘append’).json(‘file_name’)
- Overwrite Mode – dataframe_object.write.mode(‘overwrite’).json(‘file_name’)
It can be possible to append/overwrite the existing JSON. Using the write.mode(), we can append the data by passing “append” or overwrite the existing JSON data by passing “overwrite” to this function.
Example 1:
Create a “skills_df” PySpark DataFrame with 3 rows and 4 columns. Write this DataFrame to JSON.
import pandas
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# skills data with 3 rows and 4 columns
skills =[{'id':123,'person':'Honey','skill':'painting','prize':25000},
{'id':112,'person':'Mouni','skill':'dance','prize':2000},
{'id':153,'person':'Tulasi','skill':'reading','prize':1200}
]
# create the skills dataframe from the above data
skills_df = linuxhint_spark_app.createDataFrame(skills)
# write.json()
skills_df.coalesce(1).write.json('skills_data')
JSON File:
We can see that the skills_data folder includes the partitioned JSON data.
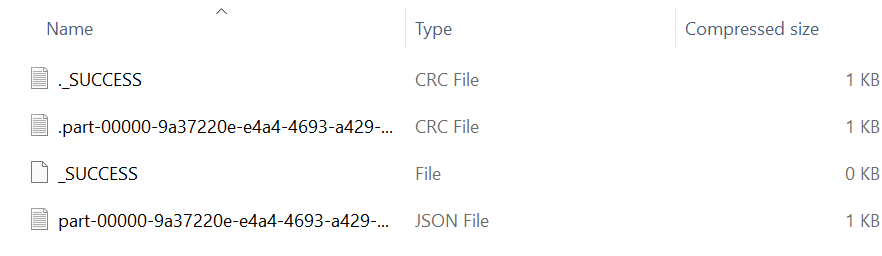
Let’s open the JSON file. We can see that all the rows from the PySpark DataFrame are converted into JSON.

There are 5 rows in the PySpark DataFrame. All these 5 rows are returned as a dictionary of strings which are separated by comma.
Example 2:
Create a “skills2_df” PySpark DataFrame with one row. Append one row to the previous JSON file by specifying the mode as “append”.
import pandas
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
skills2 =[{'id':78,'person':'Mary','skill':'riding','prize':8960}
]
# create the skills dataframe from the above data
skills2_df = linuxhint_spark_app.createDataFrame(skills2)
# write.json() with append mode.
skills2_df.write.mode('append').json('skills_data')
JSON File:
We can see the partitioned JSON files. The first file holds the first DataFrame records and the second file holds the second DataFrame record.

Conclusion
There are three different ways to convert the PySpark DataFrame to JSON. First, we discussed the to_json() method which converts to JSON by converting the PySpark DataFrame to the Pandas DataFrame with different examples by considering different parameters. Next, we utilized the toJSON() method. Lastly, we learned how to use the write.json() function to write the PySpark DataFrame to JSON. Appending, and overwriting are possible with this function.