Topic of Contents:
- PySpark DataFrame to CSV by Converting to Pandas DataFrame
- PySpark Pandas DataFrame to CSV Using the To_Csv() Method
- PySpark Pandas DataFrame to CSV by Converting to NumPy Array
- PySpark DataFrame to CSV Using the Write.Csv() Method
If you want to know about PySpark DataFrame and module installation, go through this article.
PySpark DataFrame to CSV by Converting to Pandas DataFrame
The to_csv() is a method that is available in the Pandas module which converts the Pandas DataFrame to CSV. First, we need to convert our PySpark DataFrame to Pandas DataFrame. The toPandas() method is used to do that. Let’s see the syntax of to_csv() along with its parameters.
Syntax:
- We need to specify the file name of the CSV file. If you want to store the downloaded CSV in a particular location on your PC, you can also specify the path along with the file name.
- Columns are included if the header is set to “True”. If you don’t need columns, set the header to “False”.
- Indices are specified if the index is set to “True”. If you don’t need indices, set the index to “False”.
- Columns parameter takes a list of column names in which we can specify which particular columns are extracted to the CSV file.
- We are able to add the records to CSV using the mode parameter. Append – “a” is used to do this.
Example 1: With the Header and Index Parameters
Create the “skills_df” PySpark DataFrame with 3 rows and 4 columns. Convert this DataFrame to CSV by first converting it into the Pandas DataFrame.
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# skills data with 3 rows and 4 columns
skills =[{'id':123,'person':'Honey','skill':'painting','prize':25000},
{'id':112,'person':'Mouni','skill':'dance','prize':2000},
{'id':153,'person':'Tulasi','skill':'reading','prize':1200}
]
# create the skills dataframe from the above data
skills_df = linuxhint_spark_app.createDataFrame(skills)
skills_df.show()
# Convert skills_df to pandas DataFrame
pandas_skills_df= skills_df.toPandas()
print(pandas_skills_df)
# Convert this DataFrame to csv with header and index
pandas_skills_df.to_csv('pandas_skills1.csv', header=True, index=True)
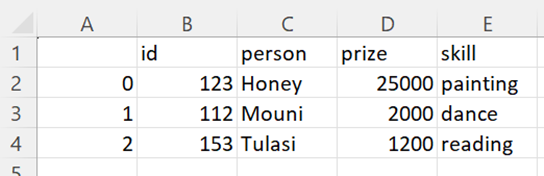
Output:

We can see that the PySpark DataFrame is converted to Pandas DataFrame. Let’s see whether it is converted to CSV with column names and indices:
Example 2: Append the Data to CSV
Create one more PySpark DataFrame with 1 record and append this to CSV which is created as part of our first example. Make sure that we need to set the header to “False” along with the mode parameter. Otherwise, the column names are also appended as a row.
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
skills =[{'id':90,'person':'Bhargav','skill':'reading','prize':12000}
]
# create the skills dataframe from the above data
skills_df = linuxhint_spark_app.createDataFrame(skills)
# Convert skills_df to pandas DataFrame
pandas_skills_df= skills_df.toPandas()
# Add this DataFrame to pandas_skills1.csv file
pandas_skills_df.to_csv('pandas_skills1.csv', mode='a',header=False)
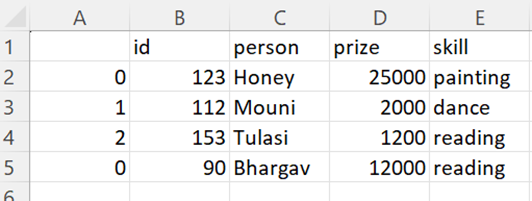
CSV Output:
We can see that a new row is added to the CSV file.
Example 3: With the Columns Parameter
Let’s have the same DataFrame and convert it into CSV with two columns: “person” and “prize”.
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# skills data with 3 rows and 4 columns
skills =[{'id':123,'person':'Honey','skill':'painting','prize':25000},
{'id':112,'person':'Mouni','skill':'dance','prize':2000},
{'id':153,'person':'Tulasi','skill':'reading','prize':1200}
]
# create the skills dataframe from the above data
skills_df = linuxhint_spark_app.createDataFrame(skills)
# Convert skills_df to pandas DataFrame
pandas_skills_df= skills_df.toPandas()
# Convert this DataFrame to csv with specific columns
pandas_skills_df.to_csv('pandas_skills2.csv', columns=['person','prize'])
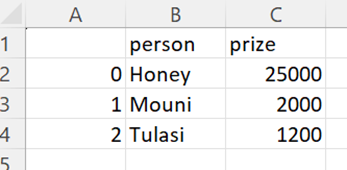
CSV Output:
We can see that only the “person” and “prize” columns exist in the CSV file.
PySpark Pandas DataFrame to CSV Using the To_Csv() Method
The to_csv() is a method that is available in the Pandas module which converts the Pandas DataFrame to CSV. First, we need to convert our PySpark DataFrame to Pandas DataFrame. The toPandas() method is used to do that. Let’s see the syntax of to_csv() along with its parameters:
Syntax:
- We need to specify the file name of the CSV file. If you want to store the downloaded CSV in a particular location on your PC, you can also specify the path along with the file name.
- Columns are included if the header is set to “True”. If you don’t need columns, set the header to “False”.
- Indices are specified if the index is set to “True”. If you don’t need indices, set the index to “False”.
- The columns parameter takes a list of column names in which we can specify which particular columns are extracted to the CSV file.
Example 1: With the Columns Parameter
Create a PySpark Pandas DataFrame with 3 columns and convert it to CSV using to_csv() with the “person” and “prize” columns.
pyspark_pandas_dataframe=pandas.DataFrame({'id':[90,78,90,57],'person':['Honey','Mouni','sam','radha'],'prize':[1,2,3,4]})
print(pyspark_pandas_dataframe)
# Convert this DataFrame to csv with specific columns
pyspark_pandas_dataframe.to_csv('pyspark_pandas1', columns=['person','prize'])
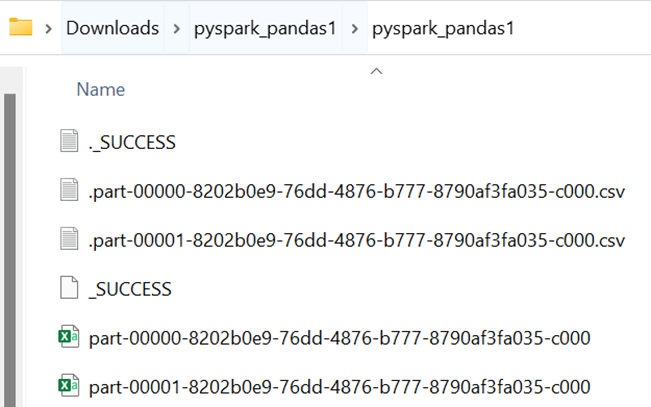
Output:

We can see that the PySpark Pandas DataFrame is converted to CSV with two partitions. Each partition holds 2 records. Also, the columns in the CSV are “person” and “prize” only.
Partition File 1:
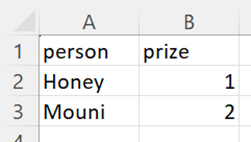
Partition File 2:
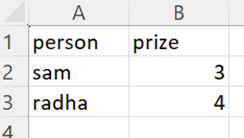
Example 2: With the Header Parameter
Use the previous DataFrame and specify the header parameter by setting it to “True”.
pyspark_pandas_dataframe=pandas.DataFrame({'id':[90,78,90,57],'person':['Honey','Mouni','sam','radha'],'prize':[1,2,3,4]})
# Convert this DataFrame to csv with header.
pyspark_pandas_dataframe.to_csv('pyspark_pandas2', header=True)
CSV Output:

We can see that the PySpark Pandas DataFrame is converted to CSV with two partitions. Each partition holds 2 records with column names.
Partition File 1:
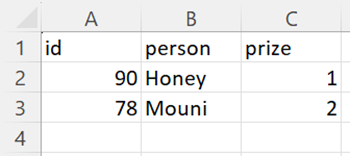
Partition File 2:

PySpark Pandas DataFrame to CSV by Converting to NumPy Array
We have an option to convert the PySpark Pandas DataFrame to CSV by converting into the Numpy array. The to_numpy() is a method that is available in the PySpark Pandas module which converts the PySpark Pandas DataFrame to the NumPy array.
Syntax:
It won’t take any parameters.
Using the Tofile() Method
After converting to the NumPy array, we can use the tofile() method to convert NumPy to CSV. Here, it stores each record in a new cell columnar wise in CSV file.
Syntax:
It takes the file name or path of a CSV and a separator.
Example:
Create PySpark Pandas DataFrame with 3 columns and 4 records and convert it to CSV by first converting it into a NumPy array.
pyspark_pandas_dataframe=pandas.DataFrame({'id':[90,78,90,57],'person':['Honey','Mouni','sam','radha'],'prize':[1,2,3,4]})
# Convert the above DataFrame to numpy array
converted = pyspark_pandas_dataframe.to_numpy()
print(converted)
# Using tofile()
converted.tofile('converted1.csv', sep = ',')
Output:
[78 'Mouni' 2]
[90 'sam' 3]
[57 'radha' 4]]
We can see that the PySpark Pandas DataFrame is converted to a NumPy array (12 values). If you can see the CSV data, it stores each cell value in a new column.

PySpark DataFrame to CSV Using the Write.Csv() Method
The write.csv() method takes the file name/path where we need to save the CSV file as a parameter.
Syntax:
Actually, the CSV is saved as partitions (more than one). In order to get rid of this, we merge all the partitioned CSV files into one. In this scenario, we use the coalesce() function. Now, we can see only one CSV file with all rows from the PySpark DataFrame.
Example:
Consider the PySpark DataFrame with 4 records having 4 columns. Write this DataFrame to CSV with the file named “market_details”.
from pyspark.sql import SparkSession
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint').getOrCreate()
# market data with 4 rows and 4 columns
market =[{'m_id':'mz-001','m_name':'ABC','m_city':'delhi','m_state':'delhi'},
{'m_id':'mz-002','m_name':'XYZ','m_city':'patna','m_state':'lucknow'},
{'m_id':'mz-003','m_name':'PQR','m_city':'florida','m_state':'usa'},
{'m_id':'mz-004','m_name':'ABC','m_city':'delhi','m_state':'lucknow'}
]
# create the market dataframe from the above data
market_df = linuxhint_spark_app.createDataFrame(market)
# Actual market data
market_df.show()
# write.csv()
market_df.coalesce(1).write.csv("market_details")
Output:

Let’s check for the file:
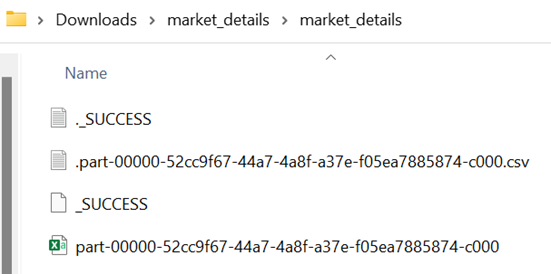
Open the last file to see the records.

Conclusion
We learned the four different scenarios that convert the PySpark DataFrame to CSV with examples by considering different parameters. When you are working with the PySpark DataFrame, you have two options to convert this DataFrame to CSV: one way is using the write() method and another is using the to_csv() method by converting to Pandas DataFrame. If you are working with PySpark Pandas DataFrame, you can also utilize the to_csv() and tofile() by converting to NumPy array.