Data
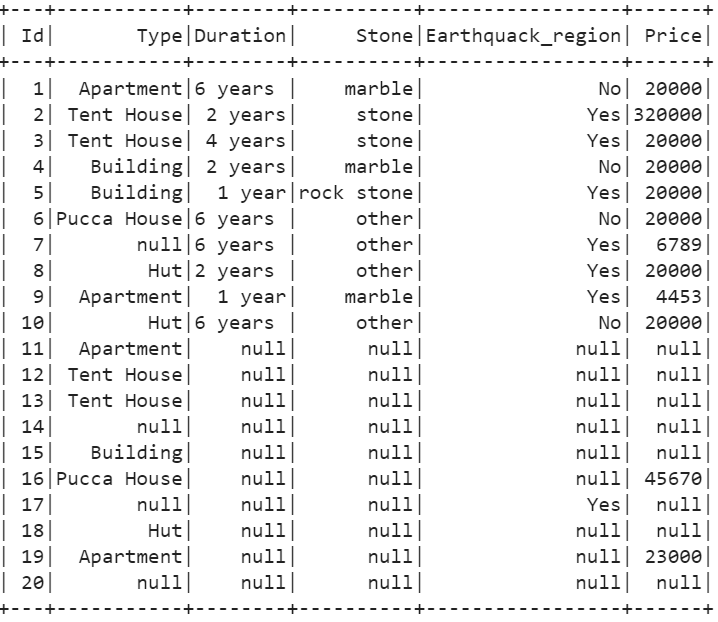
Consider the CSV file named “houses.csv” with 6 columns and 20 records. We can see that some cells are empty in this CSV.

Create a PySpark DataFrame from this CSV.
import pyspark
from pyspark.sql import SparkSession,Row
linuxhint_spark_app = SparkSession.builder.appName('Linux Hint - data processing').getOrCreate()
# Load the houses.csv file which holds 20 records.
house_details = linuxhint_spark_app.read.csv('houses.csv',header=True)
# Actual DataFrame
house_details.show()
Output:
We can see that the empty cells are considered as null in the PySpark DataFrame. In this entire tutorial, we remove the null rows or fill the null rows with some other values/elements.
First, we need to convert the “Price” column to Integer. Using the withColumn() function, cast this column to Integer with the “int” keyword.
Use the following snippet to count the null values in all columns:
# Return total null values from all the columns
house_details.select([count(when(col(iterator).isNull(), iterator)).alias(iterator) for iterator in house_details.columns]).show()
Output:

Pyspark.sql.DataFrame.dropna()
We can directly use this function which removes the null values based on particular column/s or all records in the PySpark DataFrame.
Syntax:
- It can be possible to include some records that have null value/s using the “thresh” parameter. It takes a threshold value (Integer) such that the specified records that have nulls can be included. Beyond this, all the records with null values are removed from the PySpark DataFrame.
- If you want to drop the rows that have at least one null, you need to specify “any” to the “how” parameter. If you want to drop the rows that have all null values, you need to specify “all”.
- The subset takes a list of column/s such that the null values are removed based on these column/s.
Example 1: No Parameter
In this example, we won’t pass any parameter to the drop() function. All the null records are removed from the DataFrame.
house_details.na.drop().show()
Output:

There are ten records which are not null.
Example 2: Thresh Parameter
In this example, we pass the thresh parameter and drop the null values that are present in the records which are greater than 3.
house_details.na.drop(thresh=3).show()
Output:
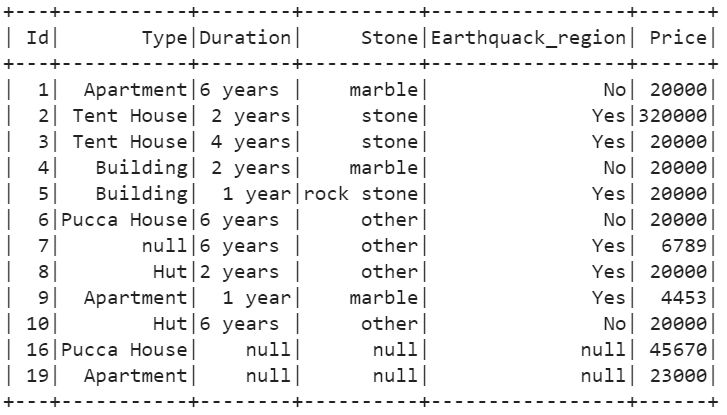
There are 12 records that have nulls which are less than 4.
Example 3: How Parameter
Drop the rows that have at least one null with the “how=’any’” parameter.
house_details.na.drop(how='any').show()
Output:
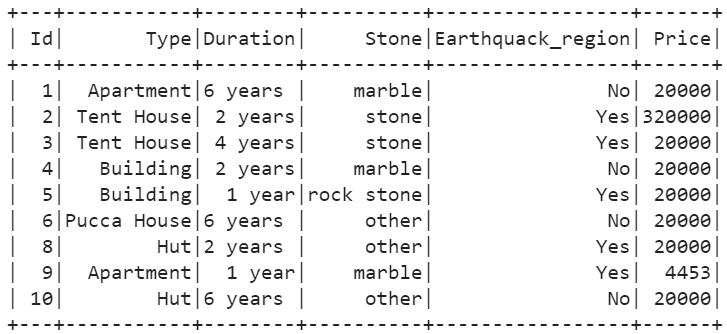
Example 4: Subset Parameter with Single Column
Drop the rows based on the “Duration” column. If the null value exists in the “Duration” column, that row will be removed.
house_details.na.drop(subset=['Duration']).show()
Output:

Example 5: Subset Parameter with Multiple Columns
Drop the rows based on the “Type”, “Stone”, and “Earthquack_region” columns.
house_details.na.drop(subset=['Type','Stone','Earthquack_region']).show()
Output:

Pyspark.sql.DataFrameNaFunctions.fill()
Until now, we have seen how to remove the null values. If you want to maintain the data without removal, you can use the fill() method to replace the null values with other values.
Syntax:
It takes two parameters. The first parameter replaces the null values and the second parameter takes the column names where the values/elements are replaced in this column only.
Example 1: Replace with Mean()
In this example, we get the average value from the “Price” column from the existing values using the mean() function. Then, we replace all the null values in the “Price” column with the mean_Price.
# Compute the mean of the Price column.
mean_Price=house_details.select(mean(house_details.Price)).collect()
print("Mean: ",mean_Price[0][0])
# Replace all the null values in the 'Price' column with the mean_Price
house_details.na.fill(mean_Price[0][0],subset=['Price']).show()
Output:
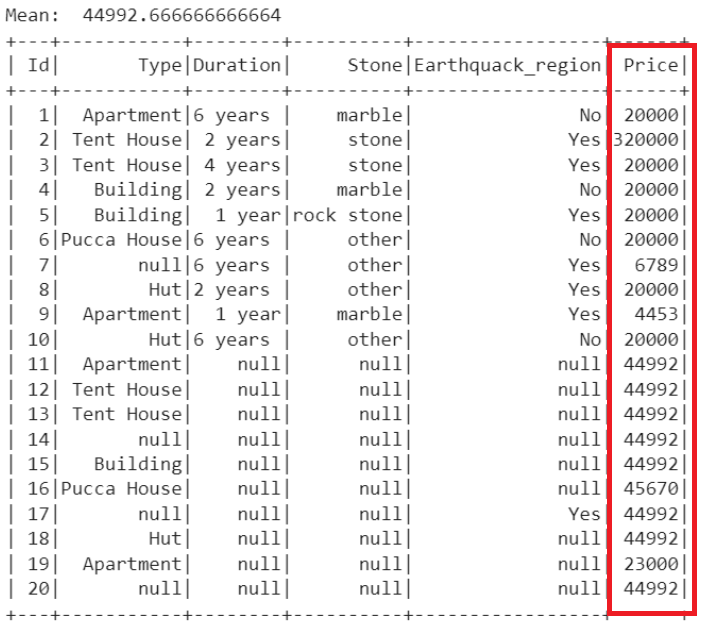
The mean of the non-null records is 44992.666. So, all the null values (Total – 8) in the “Price” column are replaced with 44992.
Example 2: Replace with Sum()
In this example, we get the total value from the “Price” column from the existing values using the sum() function. Then, we replace all the null values in the “Price” column with the total_Price.
# Compute the total sum of the Price column.
total_Price=house_details.select(sum(house_details.Price)).collect()
print("Sum: ",total_Price[0][0])
# Replace all the null values in the 'Price' column with the total_Price
house_details.na.fill(total_Price[0][0],subset=['Price']).show()
Output:
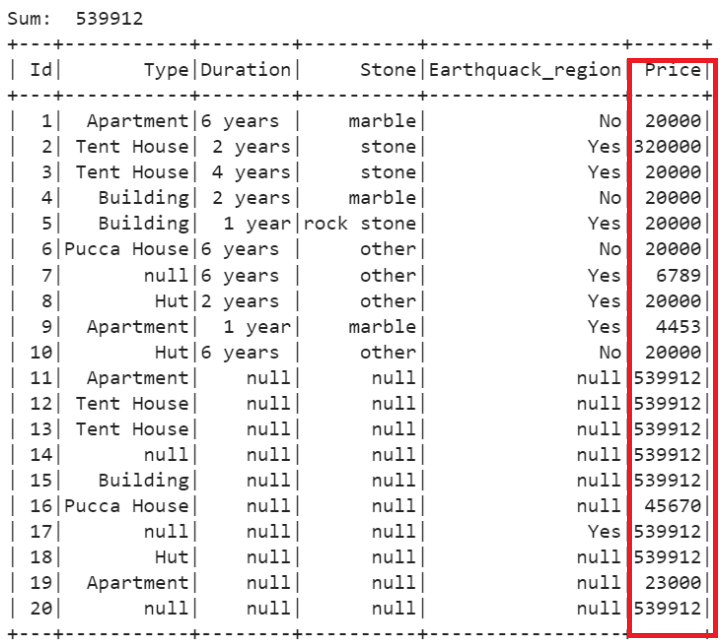
The sum of non-null records is 539912. So, all the null values (Total – 8) in the “Price” column are replaced with 539912.
Example 3: Replace with Min()
Let’s replace all the null values in the “Earthquack_region” column with the minimum element. Here, the min() function is used which returns the minimum element from [“Yes” , “No”].
# Get the minimum element from the 'Earthquack_region' column.
minimum=house_details.select(min(house_details.Earthquack_region)).collect()
print("Minimum: ",minimum[0][0])
# Replace all the null values in the 'Earthquack_region' column with the minimum element
house_details.na.fill(minimum[0][0],subset=['Earthquack_region']).show()
Output:
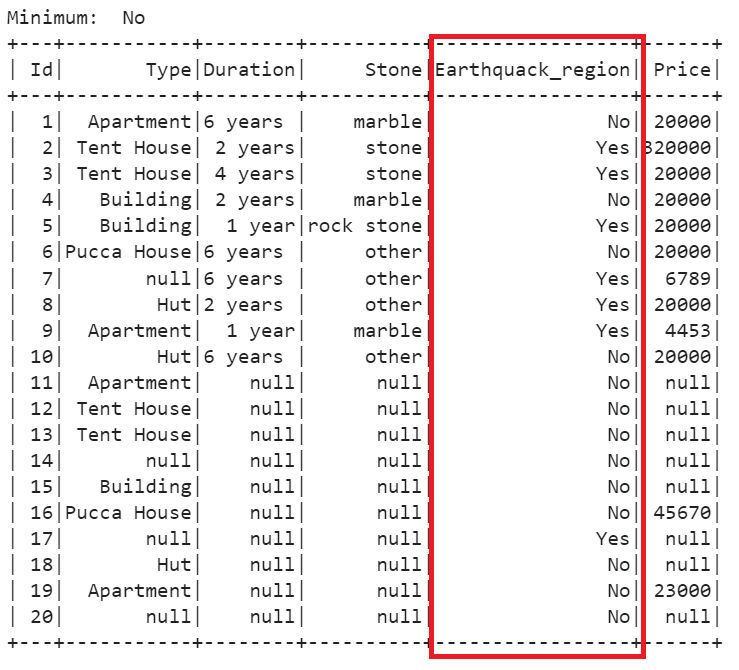
“No” is the minimum (ASCII value). All the null values are replaced with “No”.
Example 4: Replace with Max()
Replace all the null values in the “Stone” column with the maximum element.
# Get the maximum element from the 'Stone' column.
maximum=house_details.select(min(house_details.Stone)).collect()
print("Maximum: ",maximum[0][0])
# Replace all the null values in the 'Stone' column with the maximum element
house_details.na.fill(maximum[0][0],subset=['Stone']).show()
Output:

The “marble” is the minimum (ASCII value) among [“other”, “stone”, and “rock stone”]. All the null values are replaced with “marble”.
Example 5: Replace with Other Element
Replace all the null values in the “Duration” column with “10 Years”.
# Replace all the null values in the 'Duration' column with '10 Years'.
house_details.na.fill('10 Years',subset=['Duration']).show()
Output:
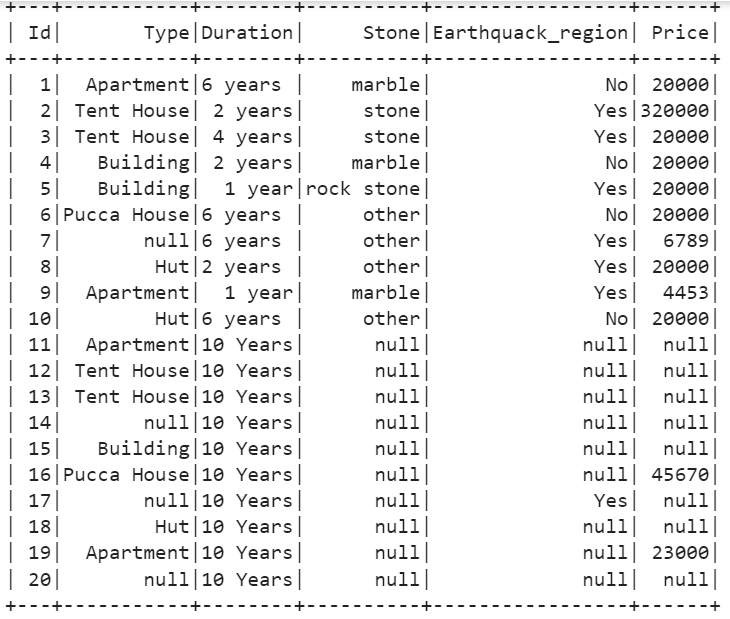
“10 Years” replaces the null values in the “Duration” column.
Conclusion
Data Preprocessing handles the removal of null values as well as the replacement of null values. The dropna() function removes the null values based on particular column/s or all records in the PySpark DataFrame. We explained this function by considering all the parameters. We can use the fill() function to replace the null values with some other elements. In this scenario, five different examples were discussed by utilizing the statistical functions – mean(), sum(), min() and max().