Let’s discuss them one by one
StructType()
This method is used to define the structure of the PySpark dataframe. It will accept a list of data types along with column names for the given dataframe. This is known as the schema of the dataframe. It stores a collection of fields
StructField()
This method is used inside the StructType() method of the PySpark dataframe. It will accept column names with the data type.
ArrayType()
This method is used to define the array structure of the PySpark dataframe. It will accept a list of data types. It stores a collection of fields. We can place datatypes inside ArrayType().
So In this article, we have to create a dataframe with an array. Let’s create a dataframe with 3 columns. The first column is Student_category which refers to the integer field to store students id’s and the second column – Student_first_name, third column – Student_last_name is used to store string values in an array created using ArrayType().
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and other data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType,ArrayType
from pyspark.sql.functions import *
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# consider an array with 5 elements
my_array_data = [(1, ['A'],['A']), (2, ['B','L','B'],['A']), (3, ['K','A','K'],['K','A','K']),(4, ['K'],['K','A','K']), (3, ['B','P'],['A'])]
#define the StructType and StructFields
#for the above data
schema = StructType([StructField("Student_category", IntegerType()),StructField("Student_first_name", ArrayType(StringType())),StructField("Student_last_name", ArrayType(StringType()))])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(my_array_data, schema=schema)
df.show()
Output

array_union()
array_union() is used to join the two array-type columns in the PySpark DataFrame by returning values from both the array columns into an array. It takes two array-type columns as parameters.
It returns all the values unique (only once).
Syntax
Parameters
- array_column1 is the first array column that has arrays with values
- array_column2 is the second array column that has arrays with values.
array_union() function is used with the select() method to do the action.
Example
In this example, we will join two array type columns – Student_first_name and Student_last_name
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and other data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType,ArrayType
from pyspark.sql.functions import *
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# consider an array with 5 elements
my_array_data = [(1, ['A'],['A']), (2, ['B','L','B'],['A']), (3, ['K','A','K'],['K','A','K']),(4, ['K'],['K','A','K']), (3, ['B','P'],['A'])]
#define the StructType and StructFields
#for the above data
schema = StructType([StructField("Student_category", IntegerType()),StructField("Student_first_name", ArrayType(StringType())),StructField("Student_last_name", ArrayType(StringType()))])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(my_array_data, schema=schema)
#apply array_union on Student_first_name and Student_last_name
df.select("Student_first_name","Student_last_name",
array_union("Student_first_name","Student_last_name")).show()
Output

We can see that
- In first row -[ A] union [A] : [A] (return unique)
- In second row – [B,L,B] union [A] : [B,L,A]
- In third row – [K,A,K] union [K,A,K] : [K,A] (only K and A are unique)
- In fourth row -[K] union [K,A,K] : [K,A] (only K and A are unique)
- In fifth row -[B,P] union [A] : [B,P,A]
array_intersect()
array_intersect() is used to join the two array type columns in the PySpark DataFrame by returning only common values from both the arrays into a new array. It takes two array type columns as parameters.
Syntax
Parameters
- array_column1 is the first array column that has arrays with values
- array_column2 is the second array column that has arrays with values.
array_intersect() function is used with the select() method to do the action.
Example
In this example, we will intersect two array type columns – Student_first_name and Student_last_name
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and other data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType,ArrayType
from pyspark.sql.functions import *
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# consider an array with 5 elements
my_array_data = [(1, ['A'],['A']), (2, ['B','L','B'],['A']), (3, ['K','A','K'],['K','A','K']),(4, ['K'],['K','A','K']), (3, ['B','P'],['A'])]
#define the StructType and StructFields
#for the above data
schema = StructType([StructField("Student_category", IntegerType()),StructField("Student_first_name", ArrayType(StringType())),StructField("Student_last_name", ArrayType(StringType()))])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(my_array_data, schema=schema)
#apply array_intersect on Student_first_name and Student_last_name
df.select("Student_first_name","Student_last_name",
array_intersect("Student_first_name","Student_last_name")).show()
Output
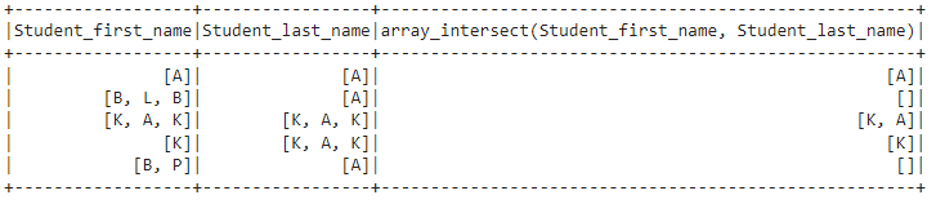
We can see that
- In first row -[ A] intersect [A] : [A] (A is common)
- In second row – [B,L,B] intersect [A] : [] (no element is common)
- In third row – [K,A,K] intersect [K,A,K] : [K,A] (K and A are common)
- In fourth row -[K] intersect [K,A,K] : [K] (only K is common)
- In fifth row -[B,P] intersect [A] : [] (no element is common)
array_except()
array_except() is used to join the two array type columns in the PySpark DataFrame by returning values in array1 but not in array2.
It returns all the values unique (only once).
Syntax
Parameters
- array_column1 is the first array column that has arrays with values
- array_column2 is the second array column that has arrays with values.
array_except() function is used with the select() method to do the action.
Example
In this example, we will perform array_except two array type columns –
- Student_last_name and Student_first_name
- Student_first_name and Student_last_name
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and other data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType,ArrayType
from pyspark.sql.functions import *
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# consider an array with 5 elements
my_array_data = [(1, ['A'],['A']), (2, ['B','L','B'],['A']), (3, ['K','A','K'],['K','A','K']),(4, ['K'],['K','A','K']), (3, ['B','P'],['A'])]
#define the StructType and StructFields
#for the above data
schema = StructType([StructField("Student_category", IntegerType()),StructField("Student_first_name", ArrayType(StringType())),StructField("Student_last_name", ArrayType(StringType()))])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(my_array_data, schema=schema)
#apply array_except on Student_last_name and Student_first_name
df.select("Student_last_name","Student_first_name",
array_except("Student_last_name","Student_first_name")).show()
#apply array_except on Student_first_name and Student_last_name
df.select("Student_first_name","Student_last_name",
array_except("Student_first_name","Student_last_name")).show()
Output

In the first result
- [A] except [A] – [] (Since A from column1 exists in column2 also)
- [A] except [B,L,B] – [A] (Since A from column1 not exists in column2)
- [K,A,K] except [K,A,K] – [] (Since K,A,K from column1 exists in column2 also)
- [K,A,K] except [K] – [A] (Since A from column1 not exists in column2)
- [A] except [B,P] – [A] (Since A from column1 not exists in column2)
In the second result
- [A] except [A] – [] (Since A from column1 exists in column2 also)
- [B,L,B] except [A] – [B,L] (Since B,L from column1 not exists in column2)
- [K,A,K] except [K,A,K] – [] (Since K,A,K from column1 exists in column2 also)
- [K] except [K,A,K] – [] (Since K from column1 exists in column2 also)
- [B,P] except [A] – [B,P] (Since B,P from column1 not exists in column2)
Conclusion
In this tutorial, we saw three different functions performed on array-type columns in PySpark DataFrame. array_union() is used to join the two array-type columns in the PySpark DataFrame by returning values from both the array columns into an array. array_intersect() is used to join the two array-type columns in the PySpark DataFrame by returning only common values from both the arrays into a new array. array_except() is used to join the two array-type columns in the PySpark DataFrame by returning values in array1 but not in array2.