In this article, we have to create a dataframe with an array. Let’s create a dataframe with 2 columns. First column is Student_category which refers to the integer field to store student ids. The second column – Student_full_name is used to store string values in an array created using ArrayType().
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and other data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType,ArrayType
from pyspark.sql.functions import array_contains
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# consider an array with 5 elements
my_array_data = [(1, ['A']), (2, ['B','L','B']), (3, ['K','A','K']),(4, ['K']), (3, ['B','P'])]
#define the StructType and StructFields
#for the above data
schema = StructType([StructField("Student_category", IntegerType()),StructField("Student_full_name", ArrayType(StringType()))])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(my_array_data, schema=schema)
df.show()
Output:

Now, we will see what array_contains() do.
array_contains() is used to check if the array has the specified element. If yes, it will return True, otherwise False.
This is possible to check using the select() method. Inside this method, we can use array_contains() function and return the result.
Syntax:
Parameters:
- array_column contains array type values
- Value is used to check if it exists in the array_column or not.
Return:
It will return True/False across all the rows in an array column.
Example 1:
In this example, we will check if the student_full_name column has ‘ L’ in all rows using the array_contains() function.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and other data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType,ArrayType
from pyspark.sql.functions import array_contains
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# consider an array with 5 elements
my_array_data = [(1, ['A']), (2, ['B','L','B']), (3, ['K','A','K']),(4, ['K']), (3, ['B','P'])]
#define the StructType and StructFields
#for the above data
schema = StructType([StructField("Student_category", IntegerType()),StructField("Student_full_name", ArrayType(StringType()))])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(my_array_data, schema=schema)
# check the Student_full_name - L in all rows using array_contains() function.
df.select("Student_full_name",array_contains('Student_full_name', 'L')).show()
Output:

Here, we selected student_full_name columns. the first column is the actual column and the second column is the result returned by array_contains() function.
Only the second row has ‘L’ value, so it returns true, and the rest results to false.
Example 2:
In this example, we will check if the student_full_name column has ‘ K’ in all rows using the array_contains() function.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and other data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType,ArrayType
from pyspark.sql.functions import array_contains
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# consider an array with 5 elements
my_array_data = [(1, ['A']), (2, ['B','L','B']), (3, ['K','A','K']),(4, ['K']), (3, ['B','P'])]
#define the StructType and StructFields
#for the above data
schema = StructType([StructField("Student_category", IntegerType()),StructField("Student_full_name", ArrayType(StringType()))])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(my_array_data, schema=schema)
# check the Student_full_name - K in all rows using array_contains() function.
df.select("Student_full_name",array_contains('Student_full_name', 'K')).show()
Output:

Here, we selected student_full_name columns. The first column is the actual column and the second column is the result returned by array_contains() function.
Only the third and fourth row has ‘K’ value, so it returns true, and the rest results to false.
Now, if you want to return the entire row in the dataframe, based on the value specified in array_contains() method, then you can use where or filter() clause instead of select clause.
Example 1: using where()
In this example, we will return the row where the student_full_name column has ‘ K’ using the array_contains() function.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and other data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType,ArrayType
from pyspark.sql.functions import array_contains
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# consider an array with 5 elements
my_array_data = [(1, ['A']), (2, ['B','L','B']), (3, ['K','A','K']),(4, ['K']), (3, ['B','P'])]
#define the StructType and StructFields
#for the above data
schema = StructType([StructField("Student_category", IntegerType()),StructField("Student_full_name", ArrayType(StringType()))])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(my_array_data, schema=schema)
# return the Student_full_name - K using array_contains() function.
df.where(array_contains('Student_full_name', 'K')).show()
Output:
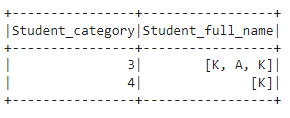
You can see that rows were returned where the Student_full_name has K value.
Example 2: using filter()
In this example, we will return the row where the student_full_name column has ‘K’ using the array_contains() function with filter clause.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#and import struct types and other data types
from pyspark.sql.types import StructType,StructField,StringType,IntegerType,FloatType,ArrayType
from pyspark.sql.functions import array_contains
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# consider an array with 5 elements
my_array_data = [(1, ['A']), (2, ['B','L','B']), (3, ['K','A','K']),(4, ['K']), (3, ['B','P'])]
#define the StructType and StructFields
#for the above data
schema = StructType([StructField("Student_category", IntegerType()),StructField("Student_full_name", ArrayType(StringType()))])
#create the dataframe and add schema to the dataframe
df = spark_app.createDataFrame(my_array_data, schema=schema)
# return the Student_full_name - K using array_contains() function.
df.filter(array_contains('Student_full_name', 'K')).show()
Output:
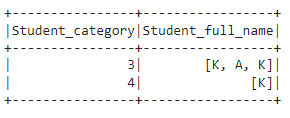
You can see that rows were returned where the Student_full_name has K value.
Conclusion
We came to know that array_contains() is used to check if the value is present in an array of columns. This can be achieved using the select clause.
If you need to return rows where the array contains values, then instead of select, you can use where or filter clause.