Logical Replication
The way to replicate the data objects and their changes is called logical replication. It works based on the publication and subscription. It uses WAL (Write-Ahead Logging) to record the logical changes in the database. The changes to the database are published on the publisher database, and the subscriber receives the replicated database from the publisher in real-time to ensure the sync of the database.
The Architecture of Logical Replication
The publisher/subscriber model is used in PostgreSQL logical replication. The replication set is published on the publisher node. One or more publication is subscribed by the subscriber node. The logical replication copies a snapshot of the publishing database to the subscriber, which is called the table synchronization phase. The transactional consistency is maintained by using commit when any change is done on the subscriber node. The manual method of PostgreSQL logical replication has been shown in the next part of this tutorial.
The logical replication process is shown in the following diagram.

All operation types (INSERT, UPDATE, and DELETE) are replicated in logical replication by default. But the changes in the object that will be replicated can be limited. The replication identity must be configured for the object that is required to add to the publication. The primary or index key is used for the replication identity. If the table of the source database does not contain any primary or index key, then the full will be used for the replica identity. That means all columns of the table will be used as a key. The publication will be created in the source database by using CREATE PUBLICATION command, and the subscription will be created in the destination database by using CREATE SUBSCRIPTION command. The subscription can be stopped or resumed by using ALTER SUBSCRIPTION command and removed by the DROP SUBSCRIPTION command. Logical replication is implemented by the WAL sender, and it is based on WAL decoding. The WAL sender loads the standard logical decoding plugin. This plugin transforms the changes retrieved from the WAL into the logical replication process, and the data is filtered based on the publication. Next, the data is transferred continuously by using the replication protocol to the replication worker that maps the data with the table of the destination database and applies the changes based on the transactional order.
Logical Replication Features
Some important features of logical replication have been mentioned below.
- The data objects replicate based on the replication identity, such as the primary key or the unique key.
- Different indexes and security definitions can be used to write data into the destination server.
- Event-based filtering can be done by using logical replication.
- Logical replication supports cross version. That means it can be implemented between two different versions of the PostgreSQL database.
- Multiple subscriptions are supported by the publication.
- The small set of tables can be replicated.
- It takes minimum server load.
- It can be used for upgrades and migration.
- It allows parallel streaming among the publishers.
Advantages of Logical Replication
Some benefits of logical replication are mentioned below.
- It is used for the replication between two different versions of PostgreSQL databases.
- It can be used to replicate data among different groups of users.
- It can be used to join multiple databases into a single database for analytical purposes.
- It can be used to send incremental changes in a subset of a database or a single database to other databases.
Disadvantages of Logical Replication
Some limitations of the logical replication are mentioned below.
- It is mandatory to have the primary key or unique key in the table of the source database.
- The full qualified name of the table is required between the publication and the subscription. If the table name is not the same for the source and destination, then the logical replication will not work.
- It does not support bi-directional replication.
- It can’t be used to replicate schema/DDL.
- It can’t be used to replicate truncate.
- It can’t be used to replicate sequences.
- It is mandatory to add super user privileges to all tables.
- Different order of columns can be used in the destination server, but the column names must be the same for the subscription and the publication.
Implementing Logical Replication
The steps of implementing logical replication in the PostgreSQL database have been shown in this part of this tutorial.
Pre-requisites
A. Setup the master and replica nodes
You can set the master and the replica nodes in two ways. One way is to use two separate computers where Ubuntu operating system is installed, and another way is to use two virtual machines that are installed on the same computer. The testing process of the physical replication process will be easier if you use two separate computers for the master node and replica node because a specific IP address can be assigned easily for each computer. But if you use two virtual machines on the same computer, then the static IP address will require to be set for each virtual machine and make sure both virtual machines can communicate with each other through the static IP address. I have used two virtual machines to test the physical replication process in this tutorial. The hostname of the master node has been set to fahmida-master, and the hostname of the replica node has been set to fahmida-slave here.
B. Install PostgreSQL on both master and replica nodes
You have to install the latest version of the PostgreSQL database server on two machines before starting the steps of this tutorial. PostgreSQL version 14 has been used in this tutorial. Run the following commands to check the installed version of the PostgreSQL in the master node.
Run the following command to become a root user.

Run the following commands to log in as a postgres user with superuser privileges and make the connection with the PostgreSQL database.
$ psql
The output shows that PostgreSQL version 14.4 has been installed on Ubuntu version 22.04.1.

Primary Node Configurations
The necessary configurations for the primary node have been shown in this part of the tutorial. After setting up the configuration, you have to create a database with the table in the primary node and create a role and publication to receive a request from the replica node, and store the updated content of the table in the replica node.
A. Modify the postgresql.conf file
You have to set up the IP address of the primary node in the PostgreSQL configuration file named postgresql.conf that is located on the location, /etc/postgresql/14/main/postgresql.conf. Log in as the root user in the primary node and run the following command to edit the file.
Find out the listen_addresses variable in the file, remove the hash (#) from the beginning of the variable to uncomment the line. You can set an asterisk (*) or the IP address of the primary node for this variable. If you set asterisk (*), then the primary server will listen to all IP addresses. It will listen to the specific IP address if the IP address of the primary server is set to this variable. In this tutorial, the IP address of the primary server that has been set to this variable is 192.168.10.5.
Next, find out the wal_level variable to set the replication type. Here, the value of the variable will be logical.
Run the following command to restart the PostgreSQL server after modifying the postgresql.conf file.
***Note: After setting up the configuration, if you face a problem starting the PostgreSQL server, then run the following commands for the PostgreSQL version 14.
$ sudo -i -u postgres
# /usr/lib/postgresql/10/bin/pg_ctl restart -D /var/lib/postgresql/10/main
You will be able to connect with the PostgreSQL server after executing the above command successfully.
Login to the PostgreSQL server and run the following statement to check the current WAL level value.

B. Create a database and table
You can use any existing PostgreSQL database or create a new database for testing the logical replication process. Here, a new database has been created. Run the following SQL command to create a database named sampled.
The following output will appear if the database is created successfully.

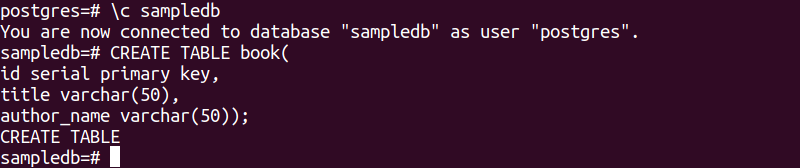
You have to change the database to create a table for the sampledb. The “\c” with the database name is used in PostgreSQL to change the current database.
The following SQL statement will change the current database from postgres to sampledb.
The following SQL statement will create a new table named book into the sampledb database. The table will contain three fields. These are id, title, and author_name.
id serial primary key,
title varchar(50),
author_name varchar(50));
The following output will appear after executing the above SQL statements.
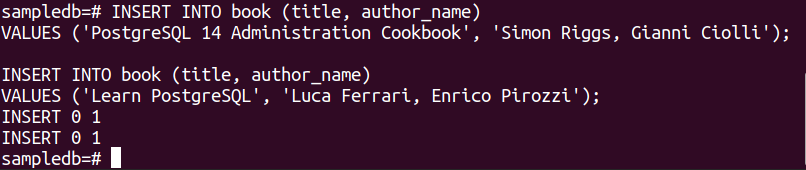
Run the following two INSERT statements to insert two records into the book table.
VALUES ('PostgreSQL 14 Administration Cookbook', 'Simon Riggs, Gianni Ciolli');
# INSERT INTO book (title, author_name)
VALUES ('Learn PostgreSQL', 'Luca Ferrari, Enrico Pirozzi');
The following output will appear if the records are inserted successfully.
Run the following command to create a role with the password that will be used to make a connection with the primary node from the replica node.
The following output will appear if the role is created successfully.

Run the following command to grant all permissions on the book table for the replicauser.
The following output will appear if permission is granted for the replicauser.

C. Modify the pg_hba.conf file
You have to set up the IP address of the replica node in the PostgreSQL configuration file named pg_hba.conf that is located on the location, /etc/postgresql/14/main/pg_hba.conf. Log in as the root user in the primary node and run the following command to edit the file.
Add the following information at the end of this file.
The IP of the slave server is set to “192.168.10.10” here. According to the previous steps, the following line has been added to the file. Here, the database name is sampledb, the user is replicauser, and the IP address of the replica server is 192.168.10.10.
Run the following command to restart the PostgreSQL server after modifying the pg_hba.conf file.
D. Create publication
Run the following command to create a publication for the book table.
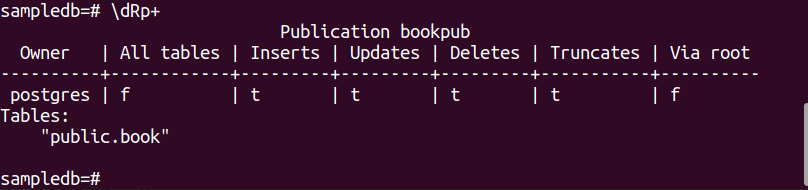
Run the following PSQL meta-command to verify that the publication is created successfully or not.
The following output will appear if the publication is created successfully for the table book.
Replica Node Configurations
You have to create a database with the same table structure that was created in the primary node in the replica node and create a subscription to store the updated content of the table from the primary node.
A. Create a database and table
You can use any existing PostgreSQL database or create a new database for testing the logical replication process. Here, a new database has been created. Run the following SQL command to create a database named replicadb.
The following output will appear if the database is created successfully.

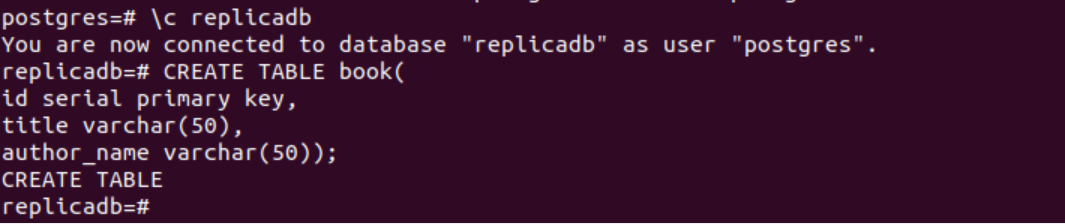
You have to change the database to create a table for the replicadb. Use the “\c” with the database name to change the current database like before.
The following SQL statement will change the current database from postgres to replicadb.
The following SQL statement will create a new table named book into the replicadb database. The table will contain the same three fields as the table created in the primary node. These are id, title, and author_name.
id serial primary key,
title varchar(50),
author_name varchar(50));
The following output will appear after executing the above SQL statements.
B. Create subscription
Run the following SQL statement to create a subscription for the database of the primary node to retrieve the updated content of the book table from the primary node to the replica node. Here, the database name of the primary node is sampledb, the IP address of the primary node is “192.168.10.5”, the user name is replicauser, and the password is “12345”.
The following output will appear if the subscription is created successfully in the replica node.

Run the following PSQL meta-command to verify that the subscription is created successfully or not.
The following output will appear if the subscription is created successfully for the table book.
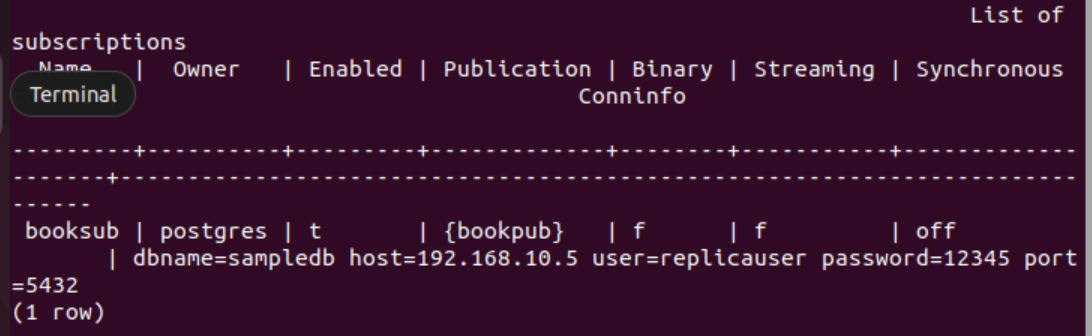
C. Check the table content in the replica node
Run the following command to check the content of the book table in the replica node after subscription.
The following output shows that two records that were inserted in the table of the primary node have been added to the table of the replica node. So, it is clear that the simple logical replication has been completed properly.

You can add one or more records or update records or delete records in the book table of the primary node or add one or more tables in the selected database of the primary node and check the database of the replica node to verify that the updated content of the primary database is replicated properly in the database of the replica node or not.
Insert new records in the primary node:
Run the following SQL statements to insert three records into the book table of the primary server.
VALUES (' The Art of PostgreSQL', ' Dimitri Fontaine'),
('PostgreSQL: Up and Running, 3rd Edition', 'Regina Obe and Leo Hsu'),
('PostgreSQL High Performance Cookbook', ' Chitij Chauhan, Dinesh Kumar');
Run the following command to check the current content of the book table in the primary node.
The following output shows that three new records have been inserted properly into the table.

Check the replica node after insertion
Now, you have to check whether the book table of the replica node has been updated or not. Login to the PostgreSQL server of the replica node and run the following command to check the content of the book table.
The following output shows that three new records have been inserted in the books table of the replica node that was inserted in the primary node of the book table. So, the changes in the main database have been replicated properly in the replica node.

Update record in the primary node
Run the following UPDATE command that will update the value of the author_name field where the value of the id field is 2. There is only one record in the book table that matches the condition of the UPDATE query.
Run the following command to check the current content of the book table in the primary node.
The following output shows that the author_name field value of the particular record has been updated after executing the UPDATE query.

Check the replica node after the update
Now, you have to check whether the book table of the replica node has been updated or not. Login to the PostgreSQL server of the replica node and run the following command to check the content of the book table.
The following output shows that one record has been updated in the book table of the replica node, which was updated in the primary node of the book table. So, the changes in the main database have been replicated properly in the replica node.

Delete record in the primary node
Run the following DELETE command that will delete a record from the book table of the primary node where the value of the author_name field is “Fahmida”. There is only one record in the book table that matches the condition of the DELETE query.
Run the following command to check the current content of the book table in the primary node.
The following output shows that one record has been deleted after executing the DELETE query.
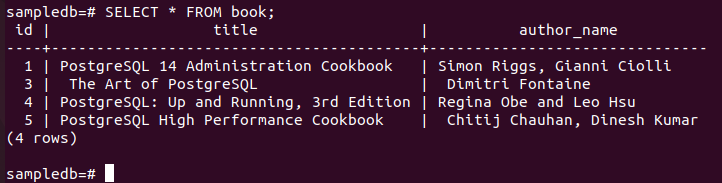
Check the replica node after deleting
Now, you have to check whether the book table of the replica node has been deleted or not. Login to the PostgreSQL server of the replica node and run the following command to check the content of the book table.
The following output shows that one record has been deleted in the book table of the replica node, which was deleted in the primary node of the book table. So, the changes in the main database have been replicated properly in the replica node.

Conclusion
The purpose of logical replication for keeping the backup of the database, the architecture of the logical replication, the advantages and disadvantages of the logical replication, and the steps of implementing logical replication in the PostgreSQL database have been explained in this tutorial with examples. I hope the concept of logical replication will be cleared for the users, and the users will be able to use this feature in their PostgreSQL database after reading this tutorial.