Pandas.DataFrame.to_parquet
The pandas.DataFrame.to_parquet() function is used to write a Pandas DataFrame to the parquet file (binary format).
Syntax:
Let’s see the syntax of the pandas.DataFrame.to_parquet() function with the parameters in detail:
- file – The parquet is created with the specified file name into the specified location.
- engine – Parquet is an open source and there are many different Python libraries and engines that can be used to write the parquet. The supported engines are “auto” (by default), “pyarrow”, “fastparquet”.
- compression (by default = “Snappy”) – We can do any of the compressions like “snappy”, “gzip”, “brotli”. No compression is done if it is set to “None”.
- index (by default = True) – The DataFrame index can be included or excluded while generating the parquet file. If you don’t want them, set this parameter to “False”.
- partition_cols (by default = None) – If you want to generate multiple parquet files for each column value, you need to specify the columns to this parameter. For example, if a column holds two categories, two parquet files are generated in a separate folder. A single parquet file is generated if this parameter is not specified with columns.
- storage_options (by default = None) – We can specify the storage connection with localhost, username, password, etc. as additional options.
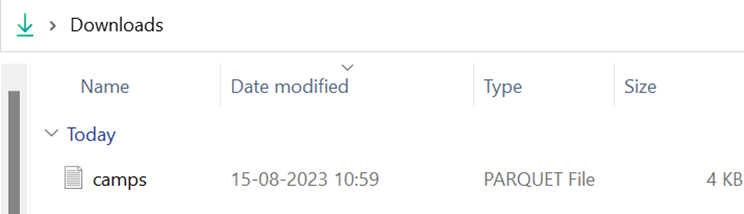
Example 1: With Default Parameters
Create a “camps” DataFrame with five rows and four columns. Write this DataFrame into the “camps.parquet” parquet with the default parameters. The DataFrame indices (0, 1, 2, 3, 4) are included in the parquet file.
# Create DataFrame - camps 5 rows and 4 columns.
camps = pandas.DataFrame([['Marketing','Conference','Completed',1200],
['Sales','Trade show','Completed',1500],
['Service','Conference','Planned',2500],
['Technical','Conference','Completed',5000],
['Others','Public Relations','Planned',6000],
],columns=['Campaign_Name', 'Campaign_Type', 'Status', 'Budget'])
print(camps)
# Write camps to the parquet file (camps.parquet)
camps.to_parquet('camps.parquet',engine='auto',index='True')
Output:

You will see the indices in the parquet file when you open it.
Example 2: Without an Index
Write the DataFrame into the parquet without indices. Set the index parameter to “False”.
# Create DataFrame - camps 5 rows and 4 columns.
camps = pandas.DataFrame([['Marketing','Conference','Completed',1200],
['Sales','Trade show','Completed',1500],
['Service','Conference','Planned',2500],
['Technical','Conference','Completed',5000],
['Others','Public Relations','Planned',6000],
],columns=['Campaign_Name', 'Campaign_Type', 'Status', 'Budget'])
# Write camps to the parquet file (camps.parquet) without indices
camps.to_parquet('camps.parquet',index=False)
Output:

When you open the parquet file, the indices will be empty.
Example 3: With Compression
Write the “camps” DataFrame to parquet by compressing it. Set the compression parameter to “gzip”.
# Create DataFrame - camps 5 rows and 4 columns.
camps = pandas.DataFrame([['Marketing','Conference','Completed',1200],
['Sales','Trade show','Completed',1500],
['Service','Conference','Planned',2500],
['Technical','Conference','Completed',5000],
['Others','Public Relations','Planned',6000],
],columns=['Campaign_Name', 'Campaign_Type', 'Status', 'Budget'])
# Write camps to the parquet file (camps.parquet) with compression
camps.to_parquet('camps.parquet',compression='gzip')
Output:
Example 4: With Partition_Cols
- Write “camps” to the parquet files based on status. Specify the partition_cols parameter and pass the “Status” column.
# Create DataFrame - camps 5 rows and 4 columns.
camps = pandas.DataFrame([['Marketing','Conference','Completed',1200],
['Sales','Trade show','Completed',1500],
['Service','Conference','Planned',2500],
['Technical','Conference','Completed',5000],
['Others','Public Relations','Planned',6000],
],columns=['Campaign_Name', 'Campaign_Type', 'Status', 'Budget'])
# Write camps to the parquet files based on Status
camps.to_parquet('camps.parquet',partition_cols=['Status'])
Output:
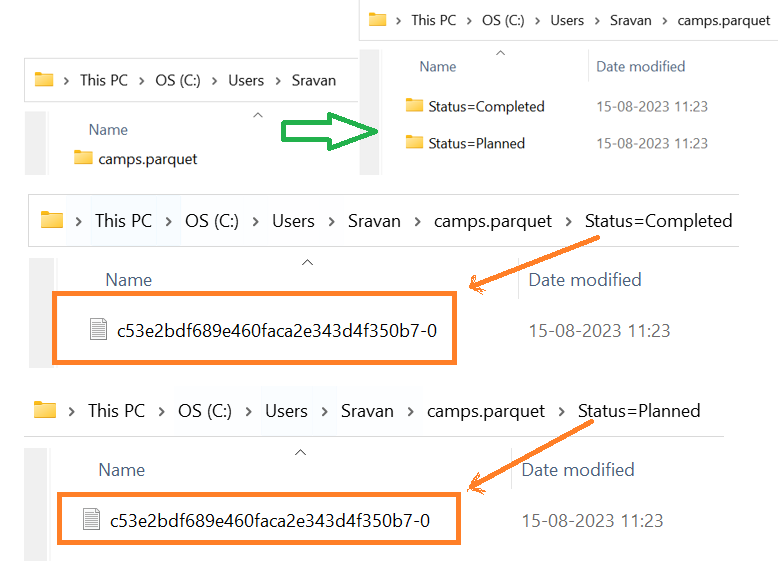
There are two categories in the “Status” column – “Completed” and “Planned”. The parquet file is created for “Completed” and “Planned” columns separately.
- Write “camps” to the parquet files based on Campaign_Type.
camps.to_parquet('camps2.parquet',partition_cols=['Campaign_Type'])
Output:
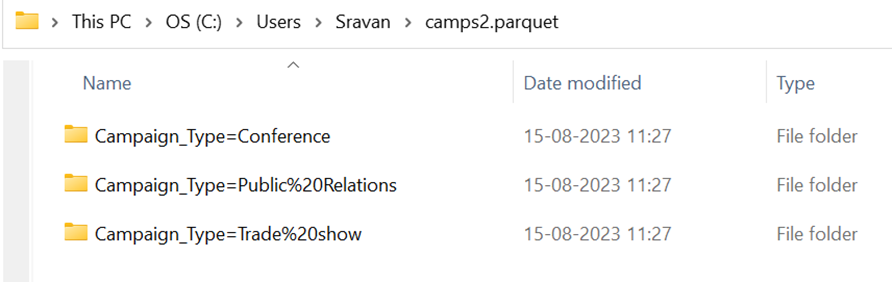
There are three categories in the Campaign_Type column – “Conference”, “Public Relations”, and “Trade show”. Parquet file is created for three categories separately. You can open each folder and verify the data that is present in the parquet file.
Conclusion
Now, you are able to write the Pandas DataFrame to a parquet file in binary format using the pandas.DataFrame.to_parquet() function. We learned how to write into parquet with and without indices. Then, we created parquet files based on the columns. In this entire guide, we used only one DataFrame which is “camps” for all the examples.