The objective of this tutorial is to help you learn how to filter out the duplicate data from a table using the SELECT DISTINCT clause.
Removing the duplicate values from a table can help you understand the actual number of unique records from a table. It can also help you reduce the resources and time which are required to apply a specific computation to the resulting data.
Oracle Distinct Clause
Using the DISTINCT clause in a select statement, we can remove all the duplicate rows from the result set and only return the unique values from the table.
The following statement shows the syntax of the SELECT DISTINCT clause in Oracle databases:
FROM table_name;
We start with the SELECT DISTINCT clause followed by the column’s name whose values are what we wish to be unique. Then, finally, we specify the target table.
If you wish the values of multiple columns to be unique, you can use the following statement:
DISTINCT column_1,
column_2,
column_3
FROM table_name;
You should understand that the more columns you specify, the more strict the select statement will be. This is because the rows in the specified columns MUST be unique to be included in the result set.
Oracle Select Distinct Example
The following is an example of using the SELECT DISTINCT clause in Oracle databases.
Suppose we have an employees table which dontains the information as shown in the following:
Table:
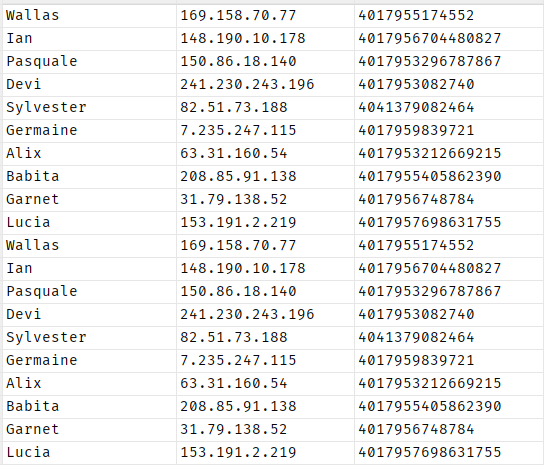
In the previous query, we fetched 20 rows before using the distinct clause.

Oracle Filter Duplicate
To remove the duplicate values, run the query with the distinct clause as shown:
This removes all the duplicate rows in the first_name column and returns the following table:
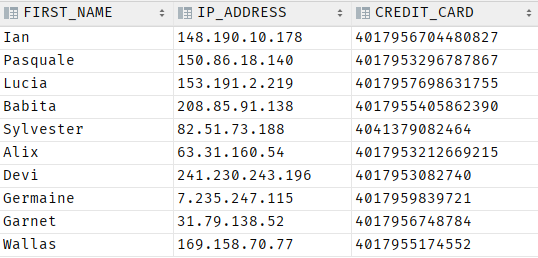
After using the distinct clause, we remove ten rows from the result set.
![]()
Keep in mind that the DISTINCT clause treats the NULL values as duplicates. Therefore, it only includes one NULL row in the result set.
If you are applying the distinct clause to more than one column while excluding the others, use the GROUP BY clause.
Conclusion
In this tutorial, you discovered the usage of the DISTINCT clause in Oracle databases to filter out the duplicate rows from a given result set.