Before that, we have to create PySpark DataFrame for demonstration.
Example:
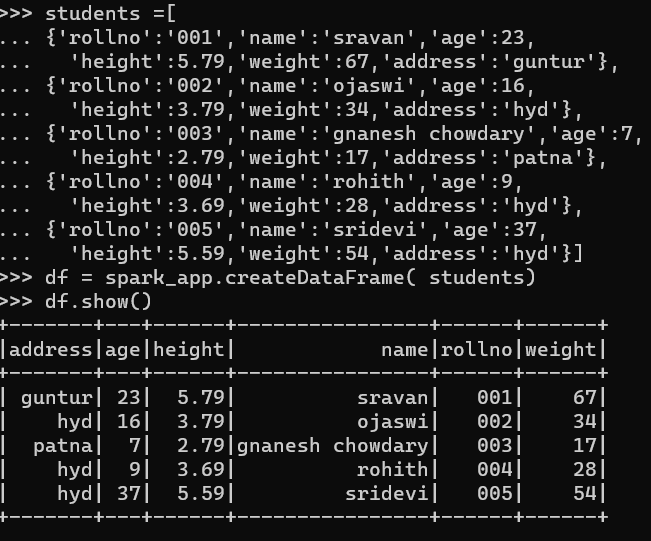
We will create a dataframe with 5 rows and 6 columns and display it using the show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#display dataframe
df.show()
Output Screenshot:
Method -1 : Using select() method
We can get the minimum value from the column in the dataframe using the select() method. Using the min() method, we can get the minimum value from the column. To use this method, we have to import it from pyspark.sql.functions module, and finally, we can use the collect() method to get the minimum from the column
Syntax:
Where,
- df is the input PySpark DataFrame
- column_name is the column to get the minimum value
If we want to return the minimum value from multiple columns, we have to use the min () method inside the select() method by specifying the column name separated by a comma.
Syntax:
Where,
- df is the input PySpark DataFrame
- column_name is the column to get the minimum value
Example 1: Single Column
This example will get the minimum value from the height column in the PySpark dataframe.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the minimum - min function
from pyspark.sql.functions import min
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#return the minimum from the height column
df.select(min('height')).collect()
Output:
In the above example, the minimum value from the height column is returned.
Example 2: Multiple Columns
This example will get the minimum value from the height, age, and weight columns in the PySpark dataframe.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#import the minimum function - min
from pyspark.sql.functions import min
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#return the minimum from the height ,age and weight columns
df.select(min('height'),min('age'),min('weight')).collect()
Output:
In the above example, the minimum value from the height, age and weight columns is returned.
Method – 2 : Using agg() method
We can get the minimum value from the column in the dataframe using the agg() method. This method is known as aggregation, which groups the values within a column. It will take dictionary as a parameter in that key will be column name and value is the aggregate function, i.e., min. Using the min () method, we can get the minimum value from the column, and finally, we can use the collect() method to get the minimum from the column.
Syntax:
Where,
- df is the input PySpark DataFrame
- column_name is the column to get the minimum value
- min is an aggregation function used to return the minimum value
If we want to return the minimum value from multiple columns, we have to specify the column name with the min function separated by a comma.
Syntax:
Where,
- df is the input PySpark DataFrame
- column_name is the column to get the minimum value
- min is an aggregation function used to return the minimum value
Example 1: Single Column
This example will get the minimum value from the height column in the PySpark dataframe.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame(students)
#return the minimum from the height column
df.agg({'height': 'min'}).collect()
Output:
In the above example, the minimum value from the height column is returned.
Example 2: Multiple Columns
This example will get the minimum value from the height, age, and weight columns in the PySpark dataframe.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#return the minimum from the height,age and weight columns
df.agg({'height': 'min','age': 'min','weight': 'min'}).collect()
Output:
In the above example, the minimum value from the height, age and weight columns is returned.
Method – 3 : Using groupBy() method
We can get the minimum value from the column in the dataframe using the groupBy() method. This method will return the minimum value by grouping similar values in a column. We have to use min() function after performing groupBy() function
Syntax:
Where,
- df is the input PySpark DataFrame
- group_column is the column where values are grouped based on this column
- column_name is the column to get the minimum value
- min is an aggregation function used to return the minimum value.
Example 1:
In this example, we will group the address column with the height column to return the minimum value based on this address column.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#return the minimum from the height column grouping with address column
df.groupBy('address').min('height').collect()
Output:
There are three unique values in the address field – hyd, guntur, and patna. So the minimum will be formed by grouping the values across the address values.
Row(address='guntur', min(height)=5.79),
Row(address='patna', min(height)=2.79)]
Example 2:
In this example, we will group the address column with the weight column to return the minimum value based on this address column.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[
{'rollno':'001','name':'sravan','age':23,
'height':5.79,'weight':67,'address':'guntur'},
{'rollno':'002','name':'ojaswi','age':16,
'height':3.79,'weight':34,'address':'hyd'},
{'rollno':'003','name':'gnanesh chowdary','age':7,
'height':2.79,'weight':17,'address':'patna'},
{'rollno':'004','name':'rohith','age':9,
'height':3.69,'weight':28,'address':'hyd'},
{'rollno':'005','name':'sridevi','age':37,
'height':5.59,'weight':54,'address':'hyd'}]
# create the dataframe
df = spark_app.createDataFrame( students)
#return the minimum from the weight column grouping with address column
df.groupBy('address').min('weight').collect()
Output:
There are three unique values in the address field – hyd, guntur, and patna. So the minimum will be formed by grouping the values across the address values.
Row(address='guntur', min(weight)=67),
Row(address='patna', min(weight)=17)]
Conclusion:
We discussed how to get the minimum value from the PySpark DataFrame using the select() and agg() methods. To get the minimum value by grouping with other columns, we used the groupBy along with the min() function. See also PySpark Max() article.