In this blog, the focus will be on how to measure this inference time for models in PyTorch.
What is Inference Time in PyTorch Models?
The meaning of inference is to analyze the input data and make calculated predictions. The time taken to make calculated predictions from new data is the inference time. Key points about inference time are listed below:
- Inference time can depend on a number of contributing factors such as the hardware available, volume of input data, type of data, and batch sizes.
- It is different from the time taken during the initial training of a machine learning model.
- Knowing how much time will be taken by a model helps data scientists to calculate how much resources to allocate and what specifications to optimize for the best results.
- The real-world application of deep learning models is critically dependent on faster inference times.
- Batch processing is an optimization technique for reducing model inference time by loading data in batches and running simultaneous processes.
How to Measure the Inference Time in PyTorch Models?
The best practice to calculate inference time is to measure for different iterations and obtain an average value for improved accuracy and to cater to varying factors.
Follow the steps below to learn how to measure the inference time for a pre-trained model in PyTorch:
Step 1: Open a Colab Notebook
Begin the project by going to the Colaboratory website and start a “New Notebook”:

Step 2: Install and Import the Necessary Libraries
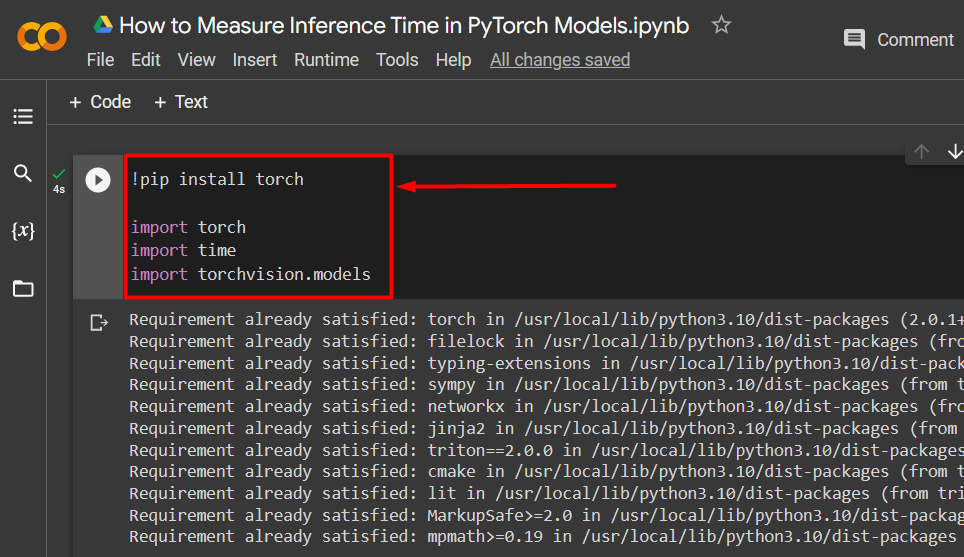
The first step to begin working in the Colab IDE is to install and import the required libraries. Library installation is done by using the “pip” installation package offered by Python. Then, the “import” command is used to add these libraries to the running project:
import torch
import time
import torchvision.models
The above code works as follows:
- The exclamation mark “!” is used to add packages into a Colab code cell.
- “pip” is the installation package for Python.
- The “torch” library contains all the essential functionality of PyTorch.
- “Time” library is used to calculate processing times.
- Lastly, the “torchvision.models” library contains pre-trained models such as ResNet:
Step 3: Load a Pre-trained Model for Inference
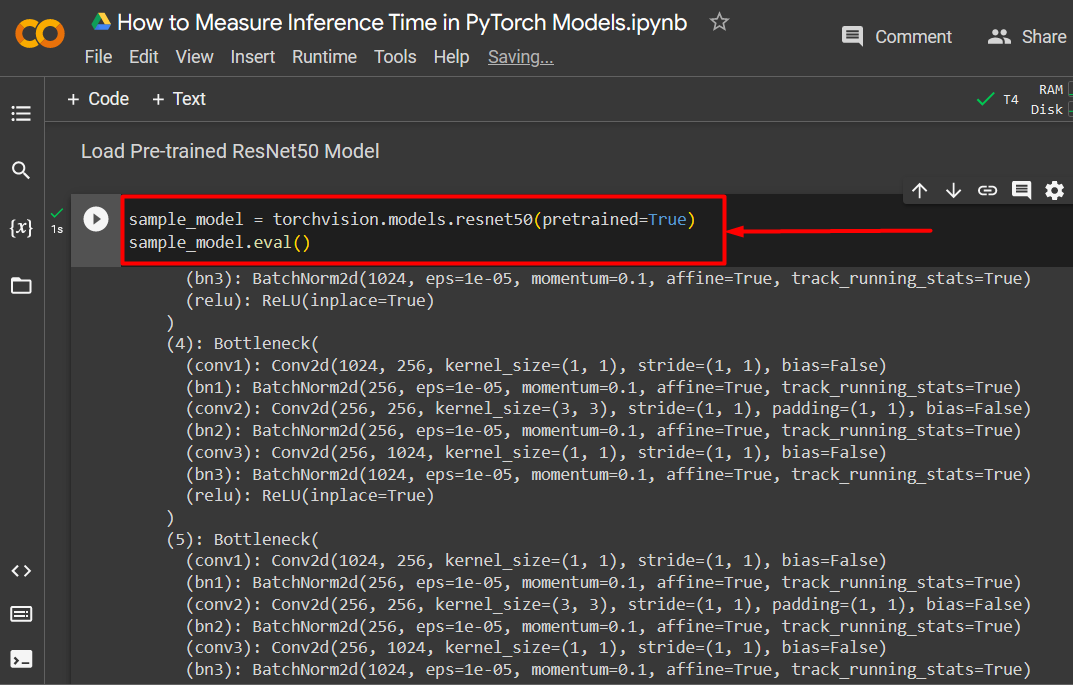
The most important step in this tutorial is to load a pre-trained model for inference. In this example, the “ResNet50” model will be used from the “torchvision.models” library catalog. “ResNet50” is a pre-trained residual neural network model that has 50 convoluted layers:
sample_model.eval()
The above code works as follows:
- The “torchvision.models” library is used to call the “resnet50()” pre-trained model.
- Next, the argument of the “resnet50()” is set as “pretrained=True” in order to run inference next.
- Then, this is assigned to the “sample_model” variable.
- Lastly, the model is put into its evaluation mode using the “eval()” method.
Loading Pre-trained ResNet50 model for Inference:
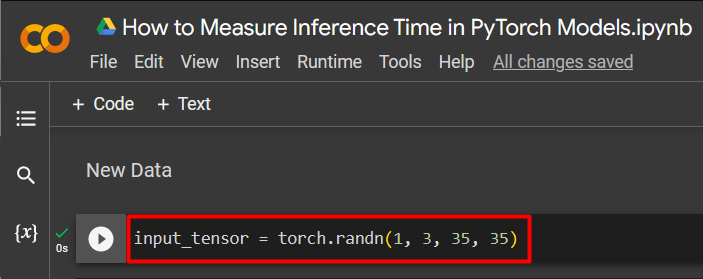
Step 4: Add New Tensor Data
Next, add some new tensor data to run inference by using the “torch.randn()” to fill random numbers:
Step 5: Measure Time to Run Inference
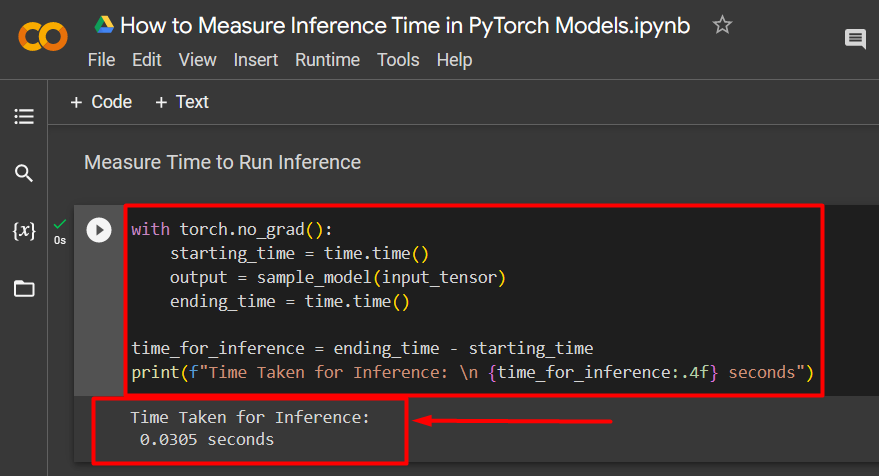
The last step is to measure the time taken to run inference on the newly input tensor data:
starting_time = time.time()
output = sample_model(input_tensor)
ending_time = time.time()
time_for_inference = ending_time - starting_time
print(f"Time Taken for Inference: \n {time_for_inference:.4f} seconds")
The above code works as follows:
- The “with torch.no_grad()” method acts like a loop to detach the gradient from the previously defined new PyTorch tensor.
- Next, the “starting_time” and “ending_time” variables are defined for the inference process.
- Then, a simple “subtraction equation” is used to calculate the time elapsed during inference.
- Lastly, use the “print()” method to showcase the output of the measured inference time.
Measured Inference time output for the ResNet50 pre-trained model is shown below:
Note: You can access our Google Colab Notebook to measure inference time at this link.
Pro-Tip
Data scientists and developers should be careful not to mistake the inference time with the time taken to run the training loop of machine learning models. These both are very different and must not be confused. Inference is the application of these AI models and it comes after a model has been adequately trained on a large enough dataset.
Success! We have just shown how to measure the inference time for a pre-trained ResNet50 model in PyTorch.
Conclusion
Measure inference time of PyTorch models using the “time” library. Load a pre-trained model, add new data, then use a “with” loop to measure inference time. Real-world use mandates prior knowledge of inference times for models for easier integration into the workflow. Knowing the time taken for inference, programmers can allocate hardware, optimize specifications, and gauge expectations. In this blog, we showed how to measure inference time for a ResNet50 model.