Syntax:
The comma-separated values (CSV) are known as the delimited text type file which separates the values using a comma. Every line in this file holds a data record and each data record contains one or more than one fields that are separated using a comma. The LangChain framework connects the AI models to the different kinds of data sources to provide customized natural language processing solutions and also allows to build the data with responsive and dynamic applications to harness the recent breakthroughs in NLP.
The framework has an attribute CSV loader that can help to import any file or the training data with the “CSV” file type into the application or AI models so that the model can be trained and tested on it.
Here in the guide, we will learn how we can import first the attribute CSV loader from the LangChain and then use it to load any CSV file to the project. The syntax for the CSV loader function is given in the following line:
The file path is an input parameter, and it specifies the path where the CSV file is located in our systems or machines.
Example 1:
In the first example of this article, we load the CSV to the project using the LangChain CSV loader function. To implement this example, we use the cloud-based and open-source Jupyternotebook-like environment that allows us to build the deep learning and machine learning models and it runs entirely in the “Google Colab” browser (web). To use the LangChain’s attribute CSV loader, we first install and download the packages of the LangChain. For this purpose, we run the following executable command:
Once we get through the installation process now, we import from the LangChain’s document.CSV loader, the “CSVLoader” attribute, as shown in the next line:
At this point, we successfully imported the CSV loader and we may utilize it now to load any CSV format file. Since the CSV file loader function asks for the file path, we first have to upload the CSV file to the directories of the Google Colab. To do so, we first upload the file by selecting the “file” icon in the sidebar and then selecting the “upload file” icon.
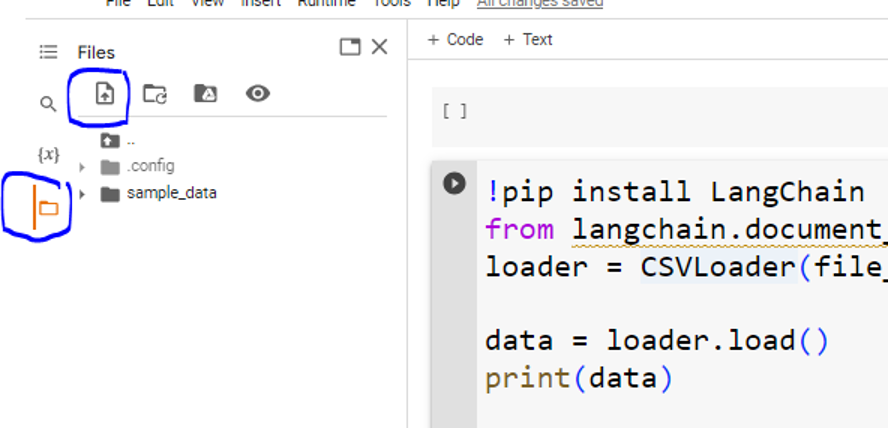
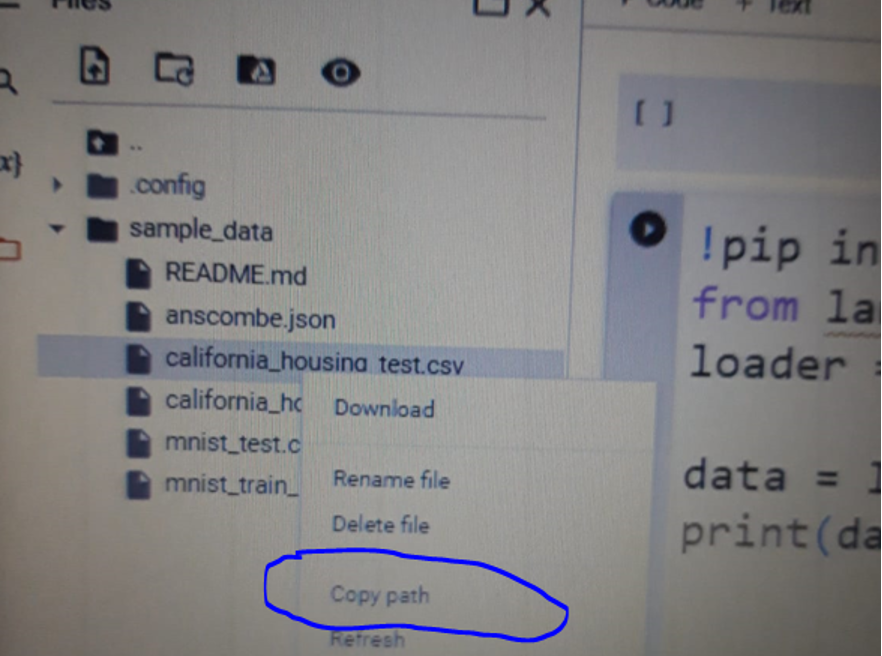
Once the file is uploaded, we can copy the path of the file. For this, we right-click on the file, and select the “copy path” option from the drop-down menu.
Now, we call the “CSVLoader()” function and pass the copied file path to it as an input argument. We save the output of this function as one variable, e.g., load file, and use the “load file.load()” function. We load and print the output for this file. The following attached the code and the output of this example:
from langchain.document_loaders.csv_loader import CSVLoader
loadfile = CSVLoader(file_path='/content/sample_data/california_housing_test.csv')
data = loadfile.load()
print(data)

The code after execution loads the CSV file and then displays the contents of the file in the CSV file format.
Example 2:
Now, we use LangChain’s Pandas agent to load the CSV file. This is the tool from the Pandas LangChain and it processes the large datasets and loads the data from the Pandas’ dataframes to perform the advanced query operations on it. We install LangChain first using the “pip” command as done in the earlier example. Then, we create an environment to set the “OpenAI API” key in a string value. This OpenAI API key is authentication for those Open AI models from the OpenAI that we want to utilize through LangChain.
$ os.environ["OPENAI_API_KEY"]="”
After the previous step from LangChain, we import the LangChain Pandas’ dataframe agent with the following command:
From the LangChain large language models, we import the “Open AI”. Then, from the Python libraries, we import the Pandas’ library as “pd”. This Pandas library is imported since we are well familiar with the fact that to read the CSV file in Python, we use the Pandas attribute as a prefix with the “csv_read (‘name of the file’)” function. The input argument of this function is the name of the file with the format (CSV) that we are required to read.
Now, if we want to print some of the rows or the columns in this file, we use the name of the variable where we store the results from the csv_read() function which, in our example, is “dataframe” and specify the rows as “dataframe[0:10]”. The “0” represents the index and the 10 represents the number of rows that we want to display as the output from the CSV file. The whole code and the output of this example are mentioned as follows:
from langchain. agents import create_pandas_dataframe_agent
from langchain.llms import OpenAI
import pandas as pd
import os
os.environ["OPENAI_API_KEY"]="”
dataframe = pd.read_csv('/content/sample_data/mnist_test.csv')
dataframe[0:10]
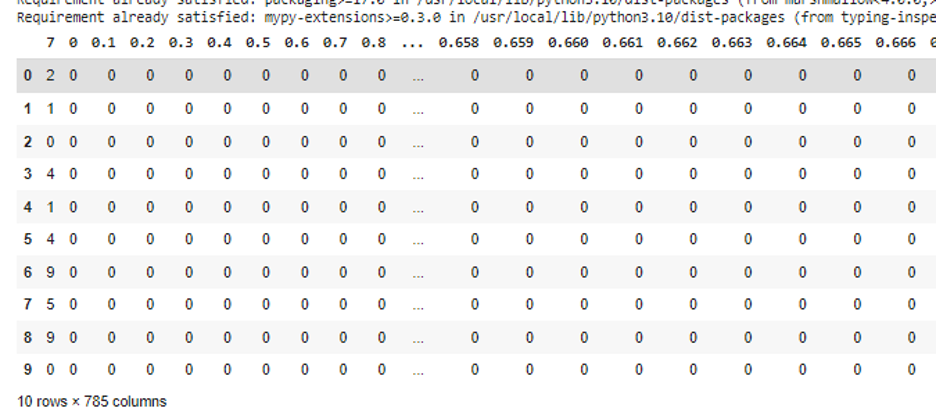
First, we install LangChain. Then, we import the LangChain Pandas’ agent and create an environment variable to set the API key. Then, we read the first ten rows of the CSV file using the csv_read() function.
Conclusion
This guide showed the two ways to use the LangChain CSV loader. This guide first gives a brief introduction to LangChain and the CSV file format. Then, it shows the method to load the CSV file using the LangChain CSVLoader function and the LangChain Pandas’ agent, respectively. We hope that this guide will help you with ongoing hands-on with the LangChain CSV loader.