It is possible to partition the rows in the DataFrame using the Window function. It is available in the pyspark.sql.window module.
Syntax:
It takes two parameters:
- Column is the column name in the PySpark DataFrame in which the lagged row values are placed based on the values in this column.
- The offset specifies the integer to return that number of previous rows to the current row values.
Steps:
- Create a PySpark DataFrame that has some similar values in at least one column.
- Partition the data using the partitionBy() method available in the Window function and order them based on the column using the orderBy() function.
Syntax:
We can order the partitioned data with the partitioned column or any other column.
Now, you can use lag() function on the partitioned rows using the over() function.
We add a column to store the row number using the withColumn() function.
Syntax:
Here, the NAME specifies the row name and the dataframe_obj is our PySpark DataFrame.
Let’s implement the code.
Example 1:
Here, we create a PySpark DataFrame that has 5 columns – [‘subject_id’,’name’,’age’,’technology1′,’technology2′] with 10 rows and partition the rows based on technology1 using the Window function. After that, we lag 1 row.
from pyspark.sql import *
spark_app = SparkSession.builder.appName('_').getOrCreate()
students =[(4,'sravan',23,'PHP','Testing'),
(4,'sravan',23,'PHP','Testing'),
(46,'mounika',22,'.NET','HTML'),
(4,'deepika',21,'Oracle','HTML'),
(46,'mounika',22,'Oracle','Testing'),
(12,'chandrika',22,'Hadoop','C#'),
(12,'chandrika',22,'Oracle','Testing'),
(4,'sravan',23,'Oracle','C#'),
(4,'deepika',21,'PHP','C#'),
(46,'mounika',22,'.NET','Testing')
]
dataframe_obj = spark_app.createDataFrame( students,['subject_id','name','age','technology1','technology2'])
print("----------Actual DataFrame----------")
dataframe_obj.show()
# import the Window Function
from pyspark.sql.window import Window
#import the lag from pyspark.sql.functions
from pyspark.sql.functions import lag
#partition the dataframe based on the values in technology1 column and
#order the rows in each partition based on subject_id column
partition = Window.partitionBy("technology1").orderBy('subject_id')
print("----------Partitioned DataFrame----------")
#Now mention LAG with offset-1 based on subject_id
dataframe_obj.withColumn("LAG",lag("subject_id",1).over(partition)).show()
Output:

Explanation:
In the first output represents the actual data present in the DataFrame. In the second output, the partition is done based on the technology1 column.
The total number of partitions is 4.
Partition 1:
The .NET occurred two times in the first partition. Since we specified the lag-offset as 1, the first .NET value is null and the next .NET value is the previous row subject_id value – 46.
Partition 2:
Hadoop occurred one time in the second partition. So, lag is null.
Partition 3:
Oracle occurred four times in the third partition.
For the first Oracle, lag is null.
For the second Oracle, the lag value is 4 (since the previous row subject_id value is 4).
For the third Oracle, the lag value is 4 (since the previous row subject_id value is 4).
For the fourth Oracle, the lag value is 12 (since the previous row subject_id value is 12).
Partition 4:
PHP occurred three times in the fourth partition.
The lag value for the 1st PHP is null.
The lag value for the 2nd PHP is 4 (since the previous row subject_id value is 4).
The lag value for the 3rd PHP is 4 (since the previous row subject_id value is 4).
Example 2:
Lag the rows by 2. Make sure that you created the PySpark DataFrame as seen in Example 1.
from pyspark.sql.window import Window
#import the lag from pyspark.sql.functions
from pyspark.sql.functions import lag
#partition the dataframe based on the values in technology1 column and
#order the rows in each partition based on subject_id column
partition = Window.partitionBy("technology1").orderBy('subject_id')
print("----------Partitioned DataFrame----------")
#Now mention LAG with offset-2 based on subject_id
dataframe_obj.withColumn("LAG",lag("subject_id",2).over(partition)).show()
Output:
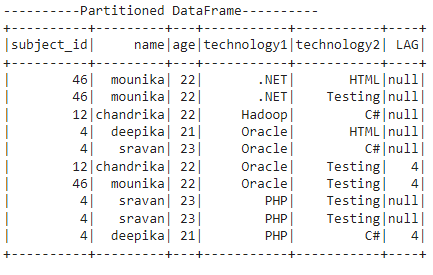
Explanation:
The partition is done based on the technology1 column. The total number of partitions is 4.
Partition 1:
The .NET occurred two times in the first partition. Since we specified the lag-offset as 2, the offset is null for both values.
Partition 2:
Hadoop occurred one time in the second partition. So, lag is null.
Partition 3:
Oracle occurred four times in the third partition.
For the first and second Oracle, lag is null.
For the third Oracle, the lag value is 4 (since the previous 2 rows subject_id value is 4).
For the fourth Oracle, the lag value is 4 (since the previous 2 rows subject_id value is 4).
Partition 4:
PHP occurred three times in the fourth partition.
The lag value for the 1st and 2nd PHP is null.
The lag value for the 3rd PHP is 4 (since the previous 2 rows subject_id value is 4).
Example 3:
Lag the rows by 2 based on the age column. Make sure that you created the PySpark DataFrame as seen in Example 1.
from pyspark.sql.window import Window
#import the lag from pyspark.sql.functions
from pyspark.sql.functions import lag
#partition the dataframe based on the values in technology1 column and
#order the rows in each partition based on age column
partition = Window.partitionBy("technology1").orderBy('age')
print("----------Partitioned DataFrame----------")
#Now mention LAG with offset-2 based on age
dataframe_obj.withColumn("LAG",lag("age",2).over(partition)).show()
Output:
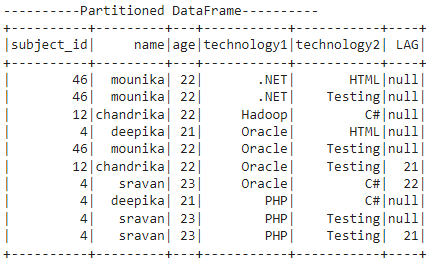
Explanation:
The partition is done based on the technology1 column and lag is defined based on the age column. The total number of partitions is 4.
Partition 1:
The .NET occurred two times in the first partition. Since we specified the lag-offset as 2, the offset is null for both values.
Partition 2:
Hadoop occurred one time in the second partition. So, lag is null.
Partition 3:
Oracle occurred four times in the third partition.
For the first and second Oracle, lag is null.
For the third Oracle, the lag value is 21 (the age value from the previous two rows is 21).
For the fourth Oracle, the lag value is 22 (the age value from the previous two rows is 22).
Partition 4:
PHP occurred three times in the fourth partition.
The lag value for the 1st and 2nd PHP is null.
The lag value for the 3rd HP is 21 (the age value from the previous two rows is 21).
Conclusion
We learned how to get the lag values in the PySpark DataFrame in partitioned rows. The lag() function in PySpark is available in the Window module which is used to return the previous rows values to the current rows. We learned the different examples by setting the different offsets.