This post guides you on the steps to install PySpark on Ubuntu 22.04. We will understand PySpark and offer a detailed tutorial on the steps to install it. Take a look!
How to Install PySpark on Ubuntu 22.04
Apache Spark is an open-source engine that supports different programming languages including Python. When you want to utilize it with Python, you need PySpark. With the new Apache Spark versions, PySpark comes bundled with it which means that you don’t need to install it separately as a library. However, you must have Python 3 running on your system.
Additionally, you need to have Java installed on your Ubuntu 22.04 for you to install Apache Spark. Still, you are required to have Scala. But it now comes with the Apache Spark package, eliminating the need to install it separately. Let’s dig in on the installation steps.
First, start by opening your terminal and updating the package repository.
Next, you must install Java if you’ve not already installed it. Apache Spark requires Java version 8 or later. You can run the following command to quickly install Java:
After the installation is completed, check the installed Java version to confirm that the installation is success:
We installed the openjdk 11 as evident in the following output:
With Java installed, the next thing is to install Apache Spark. For that, we must get the preferred package from its website. The package file is a tar file. We download it using wget. You can also use curl or any suitable download method for your case.
Visit the Apache Spark downloads page and get the latest or preferred version. Note that with the latest version, Apache Spark comes bundled with Scala 2 or later. Thus, you don’t need to worry about installing Scala separately.
For our case, let’s install the Spark version 3.3.2 with the following command:
Ensure that the download completes. You will see the “saved” message to confirm that the package has been downloaded.
The downloaded file is archived. Extract it using tar as shown in the following. Replace the archive filename to match the one that you downloaded.

Once extracted, a new folder which contains all the Spark files are created in your current directory. We can list the directory contents to verify that we have the new directory.


You then should move the created spark folder to your /opt/spark directory. Use the move command to achieve this.
Before we can use the Apache Spark on the system, we must set up an environment path variable. Run the following two commands on your terminal to export the environmental paths in the “.bashrc” file:
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin

Refresh the file to save the environmental variables with the following command:

With that, you now have Apache Spark installed on your Ubuntu 22.04. With Apache Spark installed, it implies that you have PySpark also installed with it.
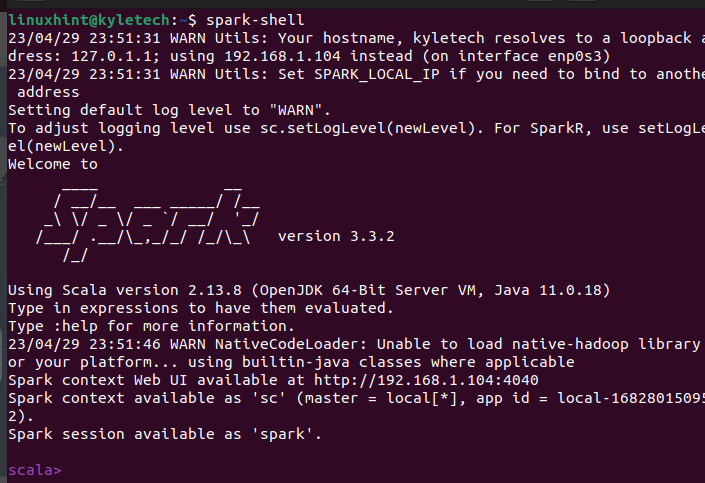
Let’s first verify that Apache Spark is installed successfully. Open the spark shell by running the spark-shell command.
If the installation is successful, it oepns an Apache Spark shell window where you can start interacting with the Scala interface.
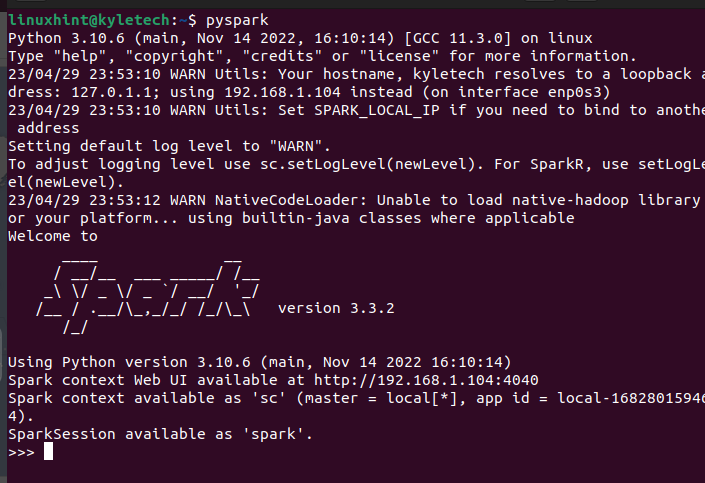
The Scala interface is not everyone’s choice, depending on the task that you want to accomplish. You can verify that PySpark is also installed by running the pyspark command on your terminal.
It should open the PySpark shell where you can start executing the various scripts and creating programs that utilize the PySpark.
Suppose you don’t get PySpark installed with this option, you can utilize pip to install it. For that, run the following pip command:
Pip downloads and sets up PySpark on your Ubuntu 22.04. You can start using it for your data analytics tasks.

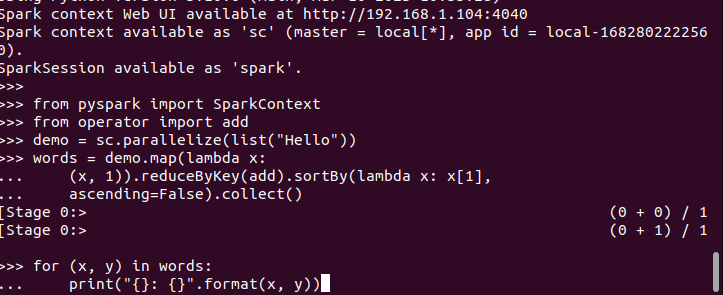
When you have the PySpark shell open, you are free to write the code and execute it. Here, we test if PySpark is running and ready for use by creating a simple code that takes the inserted string, checks all the characters to find the matching ones, and returns the total count of how many times a character is repeated.
Here’s the code for our program:
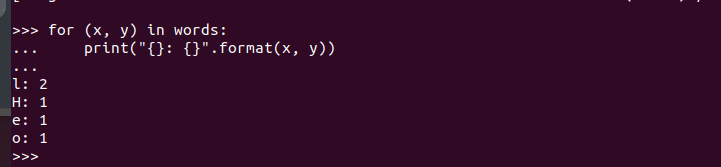
By executing it, we get the following output. That confirms that PySpark is installed on Ubuntu 22.04 and can be imported and utilized when creating different Python and Apache Spark programs.
Conclusion
We presented the steps to install Apache Spark and its dependencies. Still, we’ve seen how to verify if PySpark is installed after installing Spark. Moreover, we’ve given a sample code to prove that our PySpark is installed and running on Ubuntu 22.04.