
CURL is a command line utility to make HTTP requests and get data from web servers. It is used to automate HTTP requests to web servers. CURL is just a tool to get data and manipulate HTTP requests. Once you get the data, you can pipe it to any other programs to do any sort of data parsing depending on your need. These days CURL is also used to test REST APIs (Application Programming Interfaces). As it is very lightweight and can easily be found on any Linux distribution, it is widely used to perform different tasks.
In this article, I will show you how to install and use CURL on Ubuntu 18.04 Bionic Beaver. Let’s get started.
Installing CURL
First update the package repository cache of your Ubuntu machine with the following command:

The package repository cache should be updated.
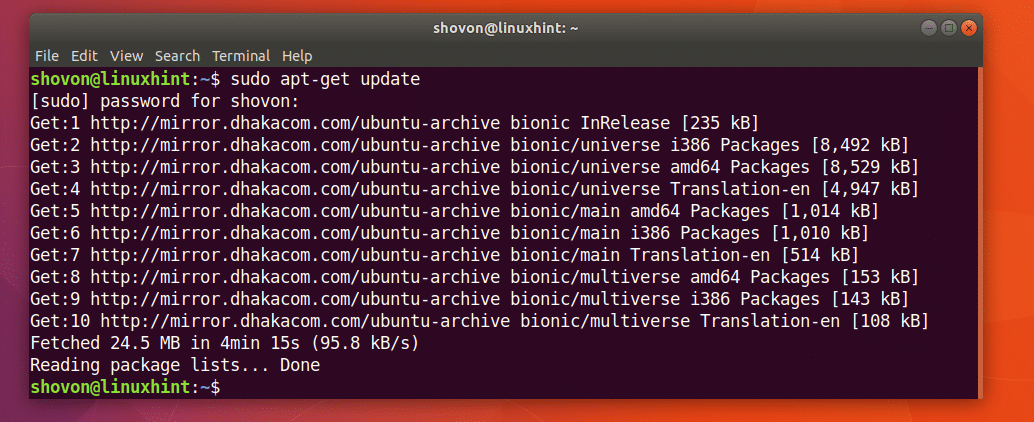
CURL is available in the official package repository of Ubuntu 18.04 Bionic Beaver.
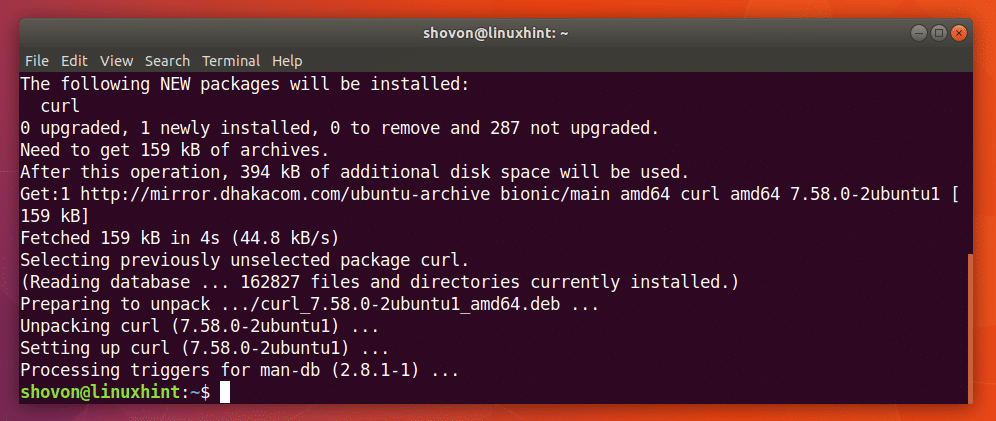
You can run the following command to install CURL on Ubuntu 18.04:

CURL should be installed.
Using CURL
In this section of the article, I will show you how to use CURL to different HTTP related tasks.
Checking a URL with CURL
You can check whether a URL is valid or not with CURL.
You can run the following command to check whether a URL for example https://www.google.com is valid or not.

As you can see from the screenshot below, a lot of texts are displayed on the terminal. It means the URL https://www.google.com is valid.
I ran the following command just to show you how a bad URL looks like.

As you can see from the screenshot below, it says Could not resolve host. It means the URL is not valid.
Downloading a Webpage with CURL
You can download a webpage from a URL using CURL.
The format of the command is:
Here, FILENAME is the name or path of the file where you want to save the downloaded webpage. URL is the location or address of the webpage.
Let’s say you want to download the official webpage of CURL and save it as curl-official.html file. Run the following command to do that:

The webpage is downloaded.

As you can see from the output of ls command, the webpage is save in curl-official.html file.

You can also open the file with a web browser as you can see from the screenshot below.

Downloading a File with CURL
You can also download a File from the internet using CURL. CURL is one of the best command line file downloaders. CURL also supports resumed downloads.
The format of the CURL command for downloading a file from the internet is:
Here FILE_URL is the link to the file you wish to download. The -O option saves the file with the same name as it is in the remote web server.
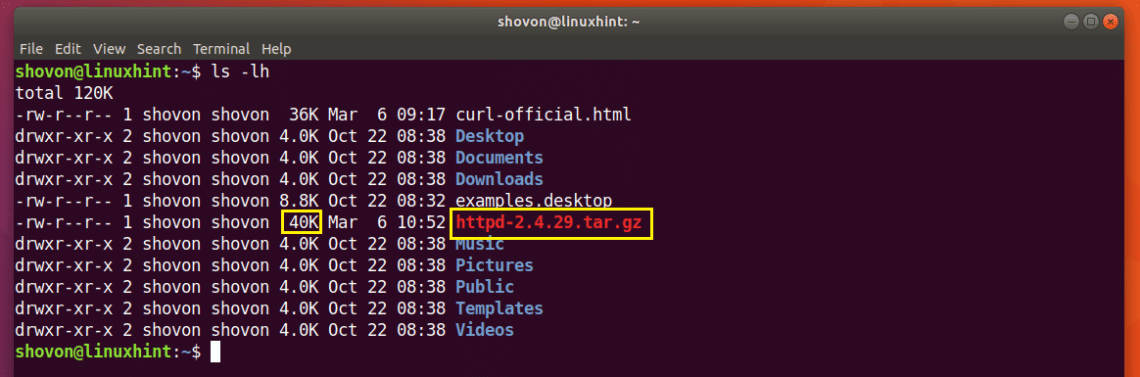
For example, let’s say you want to download the source code of Apache HTTP server from the internet with CURL. You would run the following command:

The file is being downloaded.

The file is downloaded to the current working directory.

You can see in the marked section of the output of the ls command below, the http-2.4.29.tar.gz file I just downloaded.

If you want to save the file with a different name from that in the remote web server, you just run the command as follows.

The download is complete.

As you can see from the marked section of the output of ls command below, the file is saved in a different name.

Resuming Downloads with CURL
You can resume failed downloads as well with CURL. This is what makes CURL one of the best command line downloaders.
If you used -O option to download a file with CURL and it failed, you run the following command to resume it again.
Here YOUR_DOWNLOAD_LINK is the URL of the file that you tried to download with CURL but it failed.
Let’s say you were trying to download Apache HTTP Server source archive and your network got disconnected half way, and you want to resume the download again.
Run the following command to resume the download with CURL:

The download is resumed.

If you’ve saved the file with a different name than that is in the remote web server, then you should run the command as follows:
Here FILENAME is the name of the file you defined for the download. Remember the FILENAME should match with the filename you tried to save the download as when the download failed.
Limit the Download Speed with CURL
You may have a single internet connection connected to the Wi-Fi router that everyone of your family or office is using. If you download a big file with CURL then, other members of the same network may have problems when they try to use the internet.
You can limit the download speed with CURL if you want.
The format of the command is:
Here DOWNLOAD_SPEED is the speed at which you want to download the file.
Let’s say you want the download speed to be 10KB, run the following command to do that:

As you can see, the speed is being limited to 10 Kilo Bytes (KB) which is equal to almost 10000 bytes (B).

Getting HTTP Header Information Using CURL
When you’re working with REST APIs or developing websites, you may need to check the HTTP headers of a certain URL to make sure your API or website is sending out the HTTP headers you want. You can do that with CURL.
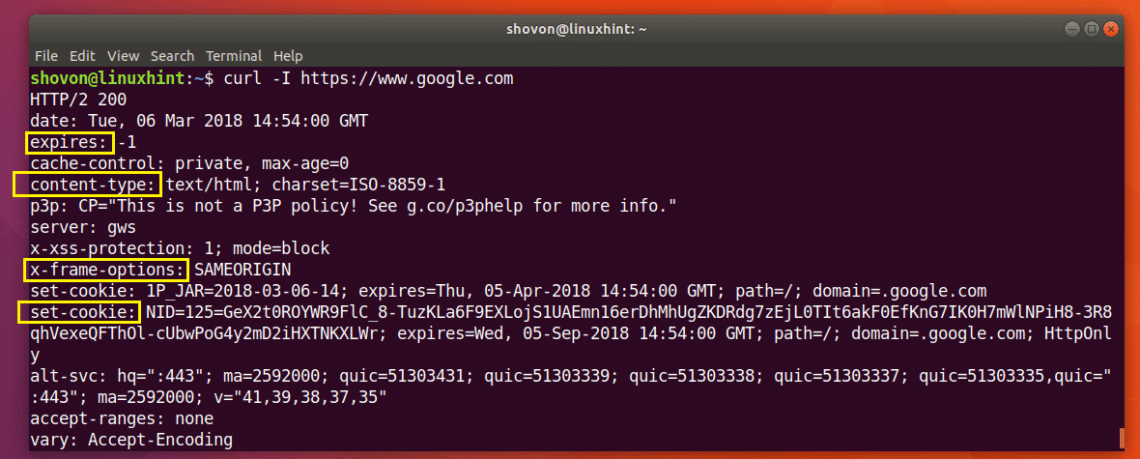
You can run the following command to get the header information of https://www.google.com:

As you can see from the screenshot below, all the HTTP response headers of https://www.google.com is listed.
That’s how you install and use CURL on Ubuntu 18.04 Bionic Beaver. Thanks for reading this article.