Initialization is the process of defining the starting values of weights and biases for machine learning models created using the PyTorch framework. These help us to regulate the quality of the results obtained from multiple reruns of the project. Optimal “initialization” values of weights and biases are required because the skewed starting points can shift the output away from the most favorable results.
In this article, we will discuss how PyTorch initializes weights in machine-learning models.
How to Define Weights Initialization in PyTorch?
Essentially, the initialization of a Neural Network model in PyTorch is the process of assigning starting values to ensure adequate progression of the results. There are several techniques for initialization that are meant for different types of models. A major point to note is that care is taken to not let the gradient vanish and for the results to converge to a solution and not diverge endlessly.
A few important techniques for initialization are given below:
- Zero Initialization – This technique sets all the starting values to zero. It has a few uses but it makes it difficult for complicated models to be able to generate valuable inferences.
- Random Initialization – As the name suggests, random initial values are assigned to the weights and biases. It is important to keep checking the progress of the model with random initialization.
- Xavier Initialization – This technique also assigns random values but these have a mean value of 0 in the normal distribution.
- Kaiming Initialization – This technique is primarily used for non-linear models and it generates values based on the Gaussian distribution.
How Does PyTorch Initialize Weights?
In PyTorch, the initial weights for a model are defined by the user. These values can be changed as the model proceeds to achieve optimal results. However, it is critical to have the best starting point so that little to no corrections are required.
Follow the below examples to learn different techniques of initialization in PyTorch:
Example 1: Use Zero Initialization Technique to Initialize Weights
Follow the steps given below to learn how to use the “Zero” initialization technique to initialize weights:
Step 1: Launch Google Colab
Go over to the Colaboratory website and click on the “New Notebook” option to start a new project:
Step 2: Begin the PyTorch Project in Colab
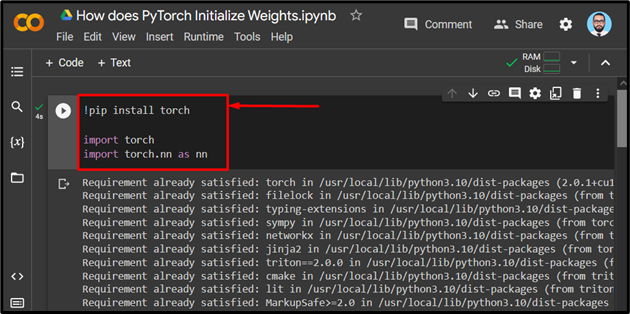
Install and import the Torch library and its neural network library using the package installer “pip” and the “import” command respectively:
import torch
import torch.nn as nn
Step 3: Zero Initialization
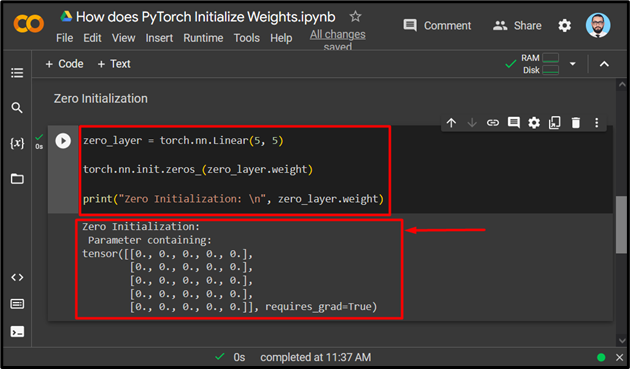
For demonstration, we will use the “Zero Initialization” technique to initialize the weights. Use the code below for the Zero Initialization to set all starting values to zero in a PyTorch model:
torch.nn.init.zeros_(zero_layer.weight)
print("Zero Initialization: \n", zero_layer.wei
The output shows the initial (5×5) tensor with all values set to zero:
Example 2: Use Kaiming Initialization Technique to Initialize Weights
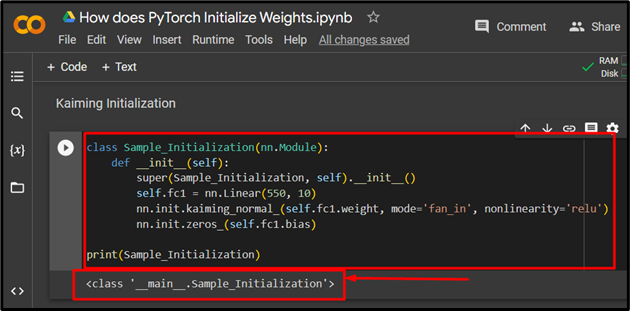
The next technique for initializing a neural network model is the “Kaiming” Initializing. Use the “__init__” method to define the technique within the “nn.Module” class as shown:
def __init__(self):
super(Sample_Initialization, self).__init__()
self.fc1 = nn.Linear(550, 10)
nn.init.kaiming_normal_(self.fc1.weight, mode='fan_in', nonlinearity='relu')
nn.init.zeros_(self.fc1.bias)
print(Sample_Initialization)
Follow these steps to understand the code:
- Assign the input and output values in the argument of the “nn.Linear()” method.
- Use the “nn.init.kaiming_normal_()” method to “initialize” the weight, define the mode, and the nonlinearity of the model as a “Rectified Linear Unit” (relu).
- Then, use the “print()” method to show the class output.
The output for Kaiming Initialization:
Example 3: Use Xavier Initialization Technique to Initialize Weights
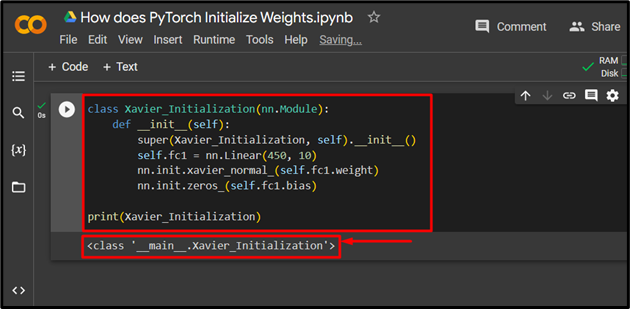
Similar to Kaiming, the “Xavier” Initialization is also defined using the “nn.Module” class in PyTorch:
def __init__(self):
super(Xavier_Initialization, self).__init__()
self.fc1 = nn.Linear(450, 10)
nn.init.xavier_normal_(self.fc1.weight)
nn.init.zeros_(self.fc1.bias)
print(Xavier_Initialization)
The output for the Xavier Initialization:
Note: You can access our Google Colab Notebook at this link.
Pro-Tip
The initialization of weights is important to start off the model properly. However, it can be easily assessed at any point. You should check the provided results at each step to perform the necessary corrections to ensure optimal results.
Success! We have shown you how to initialize weights in PyTorch using three separate techniques.
Conclusion
Weights in PyTorch are initialized using different techniques for different models such as Zero, Random, Xavier, and Kaiming Initialization. These techniques are used to provide PyTorch models with the proper stepping stone to get off to a flying start. In this article, we have explained multiple types of initialization techniques and demonstrated their use in neural networks.