Let’s look at the iconv utility of Linux in its terminal console now. So, we have been executing the instruction “iconv” with the “-l” flag to display all the known and most-used coded character sets on our terminal screen. It will display the coded character sets along with their aliases. You can see a long list of coded character sets after scrolling down a bit.
Now, it’s time to get started with the implementation of the iconv command in Linux. First, we need different types of files in our system to convert one type of file to another type. Thus, we are utilizing the “touch” query at the console terminal to create three different files, i.e., Java type, C type, and text type. Listing the current directory contents, you will find the newly generated files in it.
After this, we will look at the type of each file separately using the “file” query along with the name of each file. This query needs the “-I” option to display the type of coding character set for each file separately. If you forgot to use the “-I” option, use the “—mime” flag instead. Both the “-I” and “—mime” flags work the same.
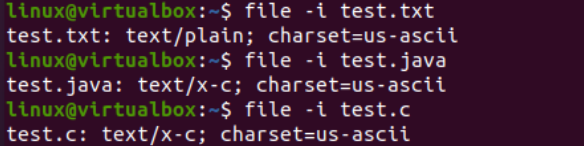
Now, after executing the “file” instruction for the “txt” type file, we got the “US-ASCII” character type encoding. While using the same instruction for the Java and C files, it shows that both files contain “BINARY” character type encoding. Along with that, this instruction shows that all these three files are empty.
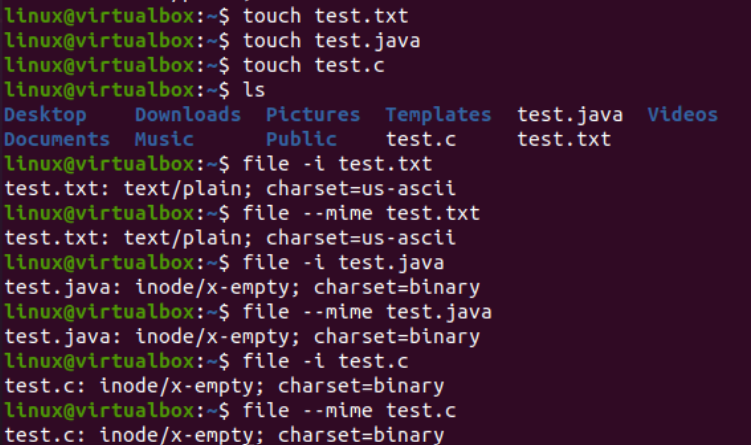
Now, we will illustrate the use of iconv instruction at the console to convert a specific character set encoding file to another character set encoding. Before that, we must add some code or data to our files. Therefore, we have added the Java code within the “text.java” file, C code within the “text.c” file, and added text data within the “test.txt” file. The cat query was used here to display the contents of all three files, as presented below:
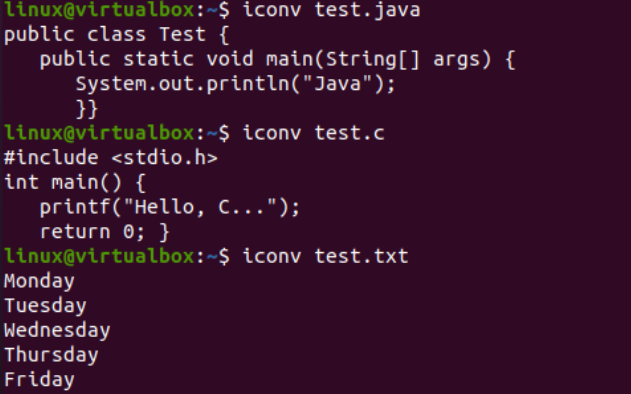
Now that we have added the data successfully, we will see the character set encoding of these files once again. So, we have tried the same file instruction within the shell with the “-I” flag and the file names, i.e., test.txt, test.java, and test.c. Running these three instructions separately for all three files shows that the character set encoding has been updated for the Java and C files while remaining the same for the text file, i.e., US-ASCII. The encoding of Java and C files was previously “binary”; now, it’s “US-ASCII”. Also, it shows that the text file contains plain text data while the other two code files contain the scripts as the content.
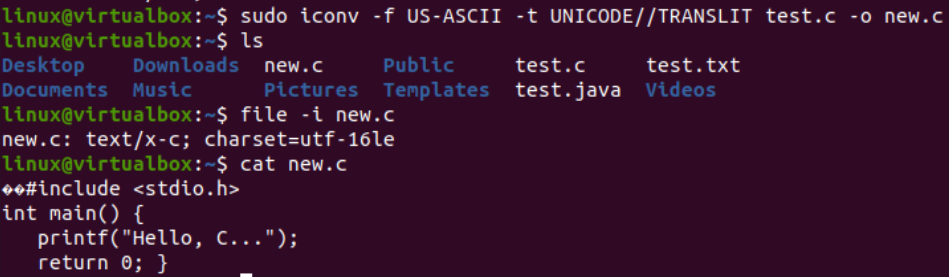
It’s time to perform the actual task needed for this article, i.e., convert one encoding to another using the iconv command in the shell. Thus, we have been using the “iconv” instruction within the shell terminal with the “sudo” privileges. This command takes the “-f” option stands for “from”, and the “-t” option stands for “to”, i.e., from one encoding to another.
After the “-f” option, you have to specify the encoding your file already has, i.e., US-ASCII. While after the “-t” option, you have to specify the encoding you want to replace with the old encoding, i.e., UNICODE. You have to specify the name of a file used as a source with the –o option to create its object image. The object image would be another file, i.e., “new.c”, of the same type but with the new encoding and the same data.
After executing the following instruction, you will get a new file in the same directory, i.e., as per the “ls” query. Now, we will check for the character set encoding of a new file generated using the iconv instruction. We will again utilize the “file” instruction with the “-I” option and the new file name, i.e., new.c.
You will see that the character set for this new file has been different from the character set of an old file, i.e., the UTF-16LE character set. This is because we have translated the US-ASCII encoding to the UNICODE encoding using the iconv instruction for our new.c file. The “cat” query displayed the same C code within the file but started with some Unicode characters, as presented already.
In a very similar way, we will change the encoding of the test.txt text file. The file instruction shows it has a US-ASCII character set encoding. The iconv command has been used with the very same format to convert the encoding of the test.txt file from US-ASCII to TURKISH8. You will see that it doesn’t change the US-ASCII to Turkish.
After this, we used the same command to cover US-ASCII to UTF-32 character set encoding for the same file. This time, it works. This is because sometimes there might be an issue converting one encoding set to another, or the other encoding may not support it.

Conclusion
This article discussed how to use the iconv Linux instructions to convert one encoding character set to another using their aliases. In this manner, we had to create some files of different types.