Data retrieval from the vector stores using LangChain is the most important aspect of the question-answering bots. The user inserts data in the form of text or JSON and then trains the model to answer questions related to the saved data. However, the model does not have an idea about the most relevant questions related to the provided data and it does not have any way to fetch answers efficiently.
This guide will explain the process of getting meaningful data using contextual compression in LangChain.
What is Contextual Compression in LangChain?
Contextual compression is a way of making it easy for models to fetch answers or relevant information from the pool of data quickly. It allows the system to compress the files and filter out the irrelevant information before making a similarity search or any kind of search. The compression is related to both the data compression within the document and document compression from the pool of data:
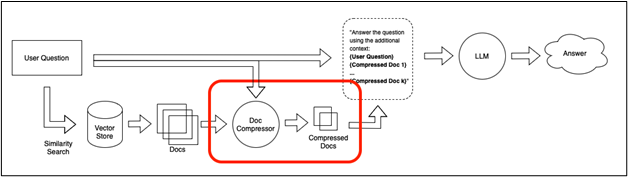
How to Get Meaningful Data Using Contextual Compression in LangChain?
To get meaningful data using the contextual compression in LangChain, simply follow this guide explaining multiple methods of using it:
Install Prerequisites Modules
Install LangChain before starting to work on it by running the following command:
Install the OpenAI module using the “pip” command to get all its libraries and methods contained inside it:
After that, install the tiktoken tokenizer which can be used to split text into small chunks:
Type the following command to install the FAISS library to apply efficient similarity search in LangChain:
After installing all the necessary modules to use contextual compression in LangChain, simply provide the OpenAI API key as the environment variables for generating text:
import getpass
os.environ['OPENAI_API_KEY'] = getpass.getpass('OpenAI API Key:')
The following screenshot displays that the API key has been processed successfully:

Upload the documents of data using the files.upload() method in the Google Collaboratory after importing the files library:
upload = files.upload()
Running the above code allows the user to upload a file from the local system by clicking on the “Choose Files” button. Select the “state_of_the_union.txt” file that contains multiple documents:

Define the function to print documents using the docs variable and configuring the function:
def pretty_print_docs(docs):
print(f"\n{'-' * 100}\n".join
([f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]))

Method 1: Using a Vanilla Vector Store Retriever
Create a vector store retriever by importing libraries necessary for it and then apply the retriever with some query related to data to retrieve information accordingly:
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import TextLoader
from langchain.vectorstores import FAISS
documents = TextLoader('state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
retriever = FAISS.from_documents(texts, OpenAIEmbeddings()).as_retriever()
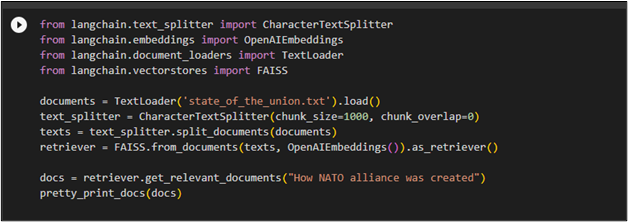
docs = retriever.get_relevant_documents("How NATO alliance was created")
pretty_print_docs(docs)
Output
Running the above code retrieves multiple documents from data related to the query applied in the retriever:
Method 2: Using Contextual Compression with an LLMChainExtractor
Import the “LLMChainExtractor” library which is used as the contextual compression in LangChain to fetch data after compressing documents and display it on the screen:
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor,
base_retriever=retriever)
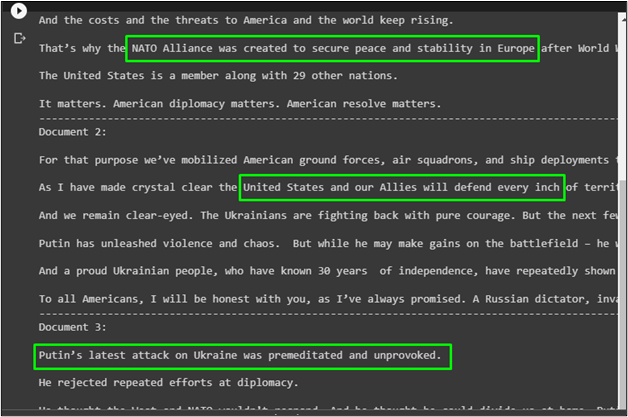
compressed_docs = compression_retriever.get_relevant_documents("How America is going to be transformed")
pretty_print_docs(compressed_docs)
The following screenshot displays the compressed version of answers retrieved according to the prompt:
Method 3: Using Built-in Compressors with an LLMChainFilter
The LLMChianFilter library which uses a built-in compressor in LangChain to fetch data using LLMs:
_filter = LLMChainFilter.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=_filter,
base_retriever=retriever)
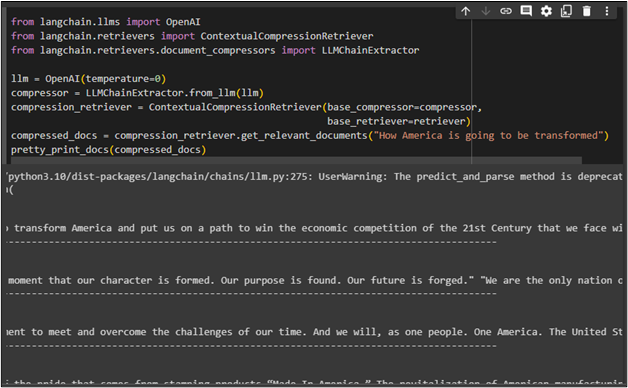
compressed_docs = compression_retriever.get_relevant_documents("How America is going to be transformed")
pretty_print_docs(compressed_docs)
The following screenshot displays multiple documents retrieved using the contextual compressor:
Method 4: Using Contextual Compression with an EmbeddingsFilter
The next method for using contextual compression is with the EmbeddingFilter which uses embedding and similarity threshold as the parameters:
from langchain.retrievers.document_compressors import EmbeddingsFilter
embeddings = OpenAIEmbeddings()
embeddings_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
compression_retriever = ContextualCompressionRetriever(base_compressor=embeddings_filter,
base_retriever=retriever)
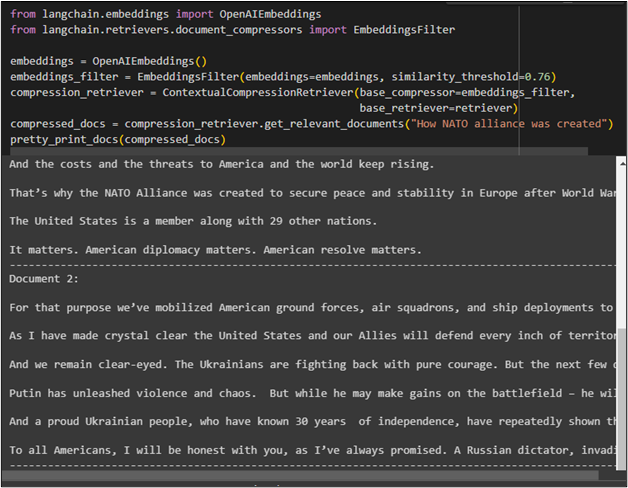
compressed_docs = compression_retriever.get_relevant_documents("How NATO alliance was created")
pretty_print_docs(compressed_docs)
The following screenshot displays the documents retrieved using the prompt provided in the compression retriever function:
Method 5: Using String Compressor and Document Transformers
EmbeddingRedundantFilter library is used to apply the filter for efficient search through the data. After that, the DocumnetCompressorPipeline library is imported to use the transformer on splitter and filter:
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain.text_splitter import CharacterTextSplitter
splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0, separator=". ")
redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings)
relevant_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
pipeline_compressor = DocumentCompressorPipeline(
transformers=[splitter, redundant_filter, relevant_filter]
)
Use ContextualCompressionRetriver() function to get relevant answer for the query prompted in natural language:
base_retriever=retriever)
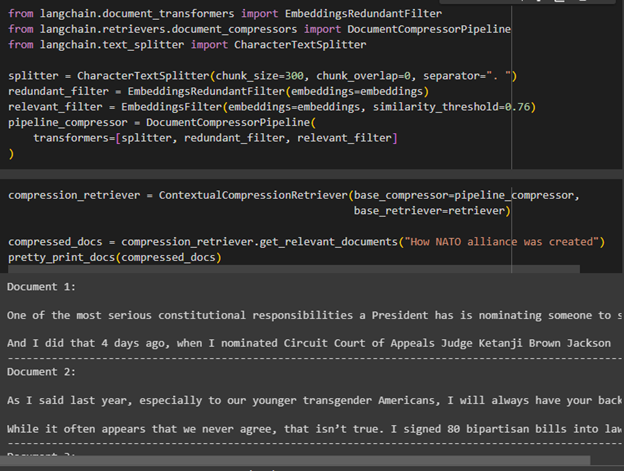
compressed_docs = compression_retriever.get_relevant_documents("How NATO alliance was created")
pretty_print_docs(compressed_docs)
That is all about getting meaningful data using contextual compression in LangChain.
Conclusion
To get meaningful data using contextual compression in LangChain, install the necessary modules and libraries. Contextual compressions are used to filter information by compressing documents and then retrieving text from compressed data. There are multiple methods for applying contextual compression such as using LLMChainExtractor, built-in compressors, filters, and transformers. This guide has explained the process of getting information using contextual compression in LangChain using multiple methods.