“The term sed is an abbreviation of stream editor. In UNIX/Linux, the sed command parses and transforms streams (texts, in most cases). It’s a command-line tool that comes pre-installed in every UNIX/Linux system.”
In this guide, we will explore the G option in sed.
Basic Usage of Sed
The most common usage of the sed command is finding and replacing contents in a given stream. The command structure is as follows:
Have a look at the following example:

Here,
-
- The echo command prints the given string on the STDOUT. In Bash, STDOUT, STDIN, and STDERR are built-in data streams.
- The sed command uses STDOUT as the stream, operates as specified, and prints the output on the console.
If you’re trying to edit a text file, sed won’t change the file contents by default. This is to avoid accidental data loss. To change the contents of a file directly, you need to run sed with in-place editing.
The g Option in Sed
When finding and replacing, the default behavior of sed is to terminate its actions upon finding the first instance. The following example demonstrates this behavior perfectly:

Here,
-
- Using the echo command, we’re passing the same word “the” multiple times to the sed command.
- However, in the output, only the first instance of “the” is transformed into “THE”.
To instruct sed to transform all the matching instances of the given pattern, we have to add the g option. Update the command as follows:

Now, all the instances of “the” are changed to “THE” properly.
The G Option in Sed
We finally arrive at the focus point of this guide. While the g option is applicable for text substitution, the G option is used for a completely different purpose.
Using the G option, we can append hold space to pattern space. In simple terms, we can add new lines before/after the matching pattern.
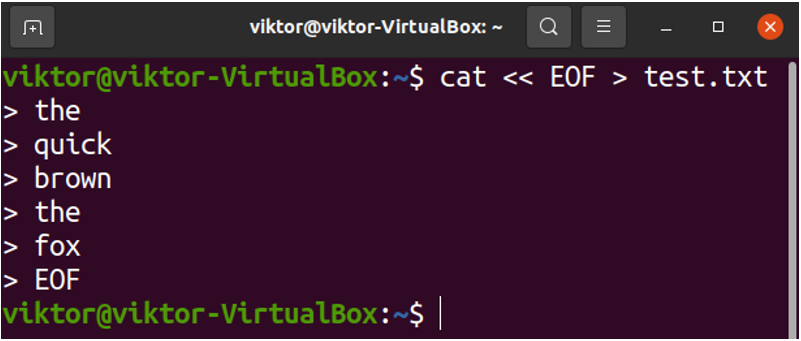
For demonstration, I’ve created a sample text file test.txt:
the
quick
brown
the
fox
EOF
Additional Spacing
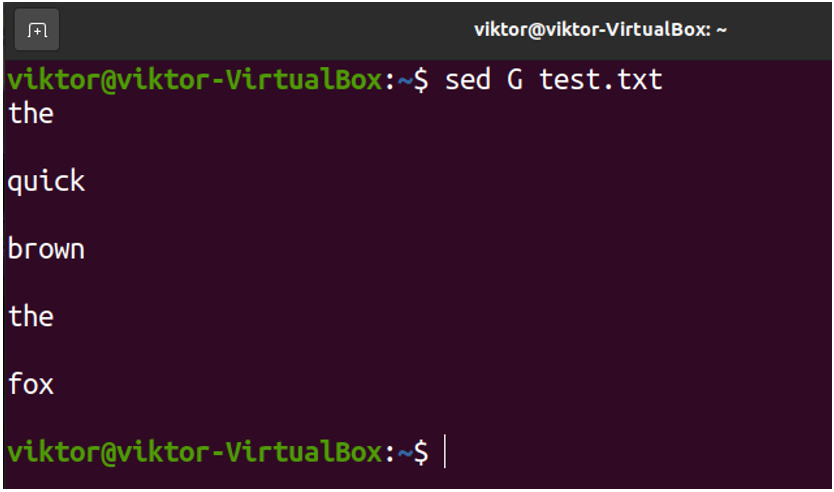
We can now perform various operations on the spacing of the file. For example, to double space the file, use the following command:
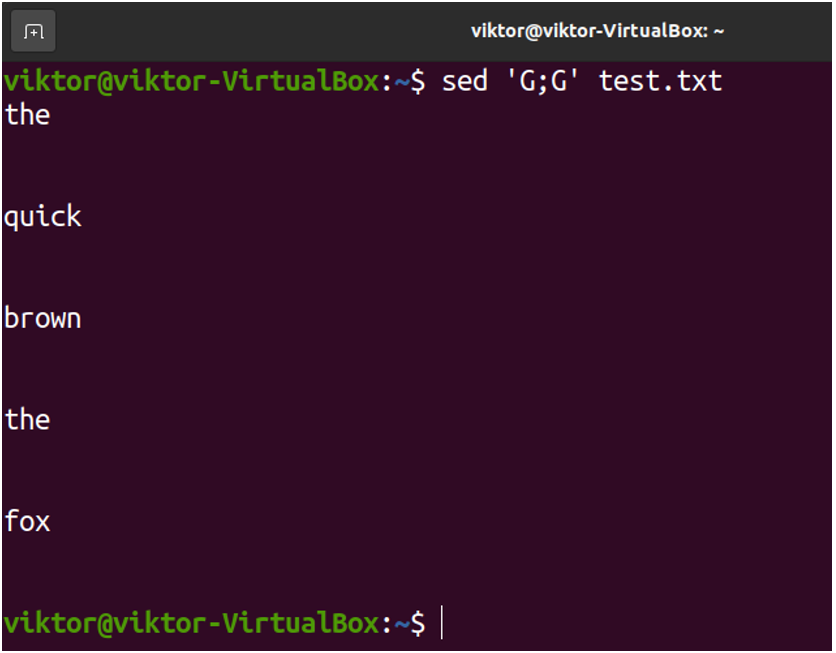
Similarly, we can triple space the file:
Here,
-
- In both cases, because we’re not providing any pattern to match for, sed is matching for all the texts in the file.
- The sed command works line-by-line on a given text stream. After matching each line (because no specific pattern was provided), a new line is added.
Removing Additional Spacing
We can also use the G option to delete all blank lines and double space:
Inserting Blank Lines Before/After the Matches
We can specify a pattern using regular expression and tell sed to add a blank line before/after it.
The first example will be adding a blank line below the matching pattern:
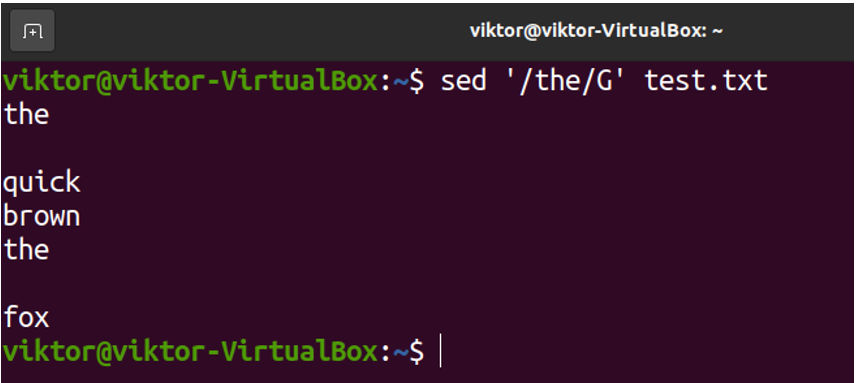
The next example will be adding a blank line above the matching pattern:
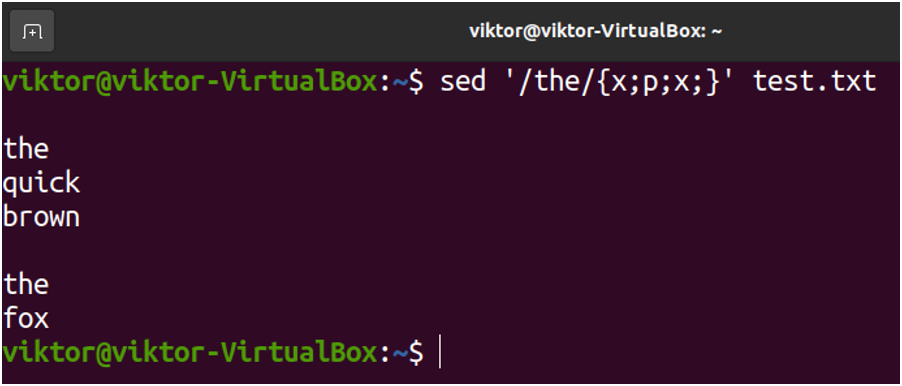
Finally, we can combine both of them together to insert blank lines around the matching pattern:
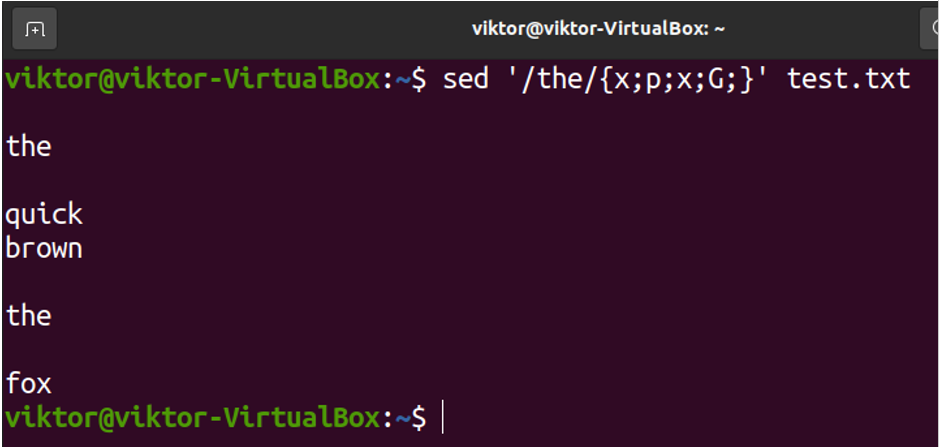
Final Thoughts
In this guide, we successfully demonstrated various ways to use the G option with sed to add spaces in the text. This technique can be useful in various situations, for example, singling out specific lines in a debug log.
A huge advantage of sed is its regular expression support. Learn more about sed with regex. The sed command can also easily be integrated into shell scripting.
Happy computing!