
If you are a keen book reader, it would be quite difficult for you to carry even more than two books. That’s no more the case, thanks to ebooks that save a lot of space in your home and your bag as well. Carrying hundreds of books with you is literally no more a dream.
Ebooks come in different formats, but the common one is PDF. Most of the ebook PDFs have hundreds of pages, and just like real books, with the help of a PDF reader navigating these pages is quite easy.
Suppose you are reading a PDF file and want to extract some specific pages from it and save it as a separate file; how would you do that? Well, it is a cinch! No need to get premium applications and tools to accomplish it.
This guide focuses on extracting a specific part from any PDF file and saving it with a different name in Linux. Though there are multiple ways to do this, I will be focusing on the less cluttered approach. So, let’s begin:
There are two main approaches:
- Extracting PDF pages through GUI
- Extracting PDF pages through the terminal
You can follow any method according to your convenience.
How to extract PDF pages in Linux via GUI:
This method is more like a trick for extracting pages from a PDF file. Most of the Linux distributions come with a PDF reader. So, let’s learn a step by step process of extracting pages using the default PDF reader of Ubuntu:\
Step 1:
Simply open your PDF file in the PDF reader. Now click on the menu button and as shown in the following image:
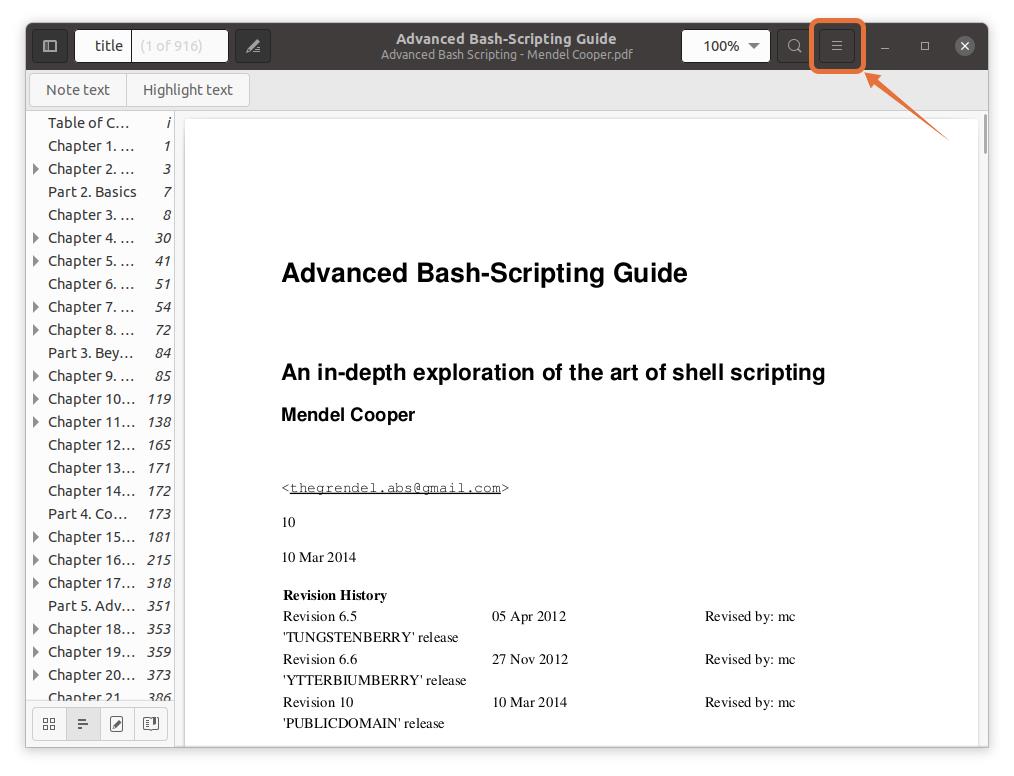
Step 2:
A menu will appear; now click on the “Print” button, a window will come out with print options. You can also use the shortcut keys “ctrl+p” to quickly get this window:
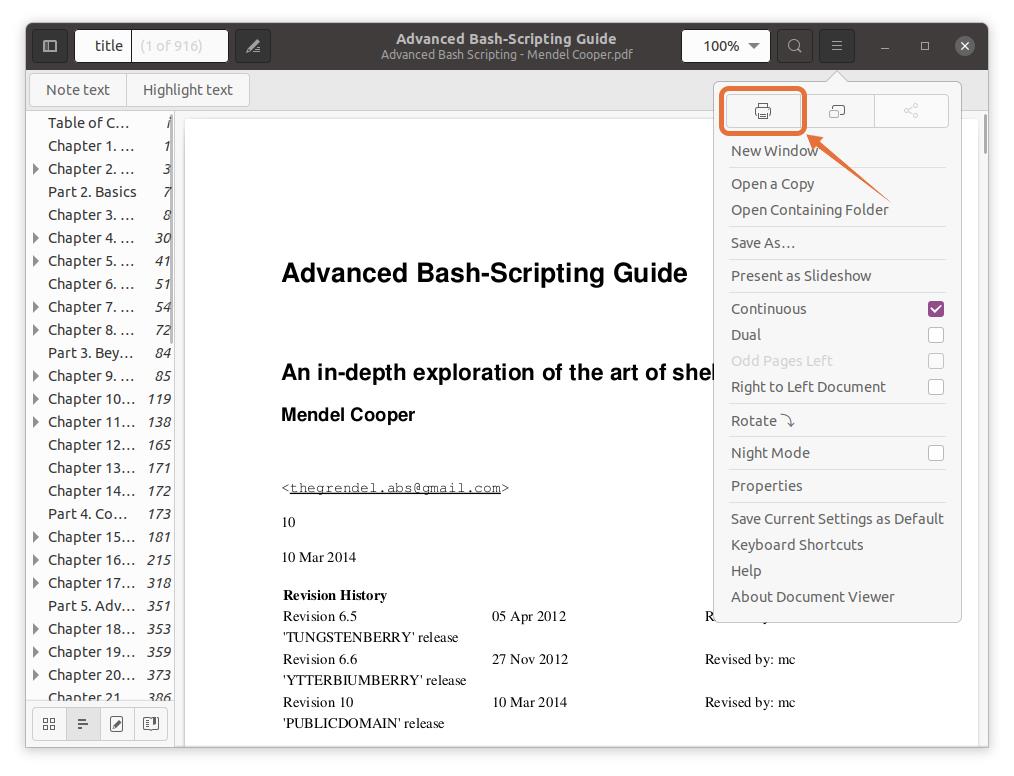
Step 3:
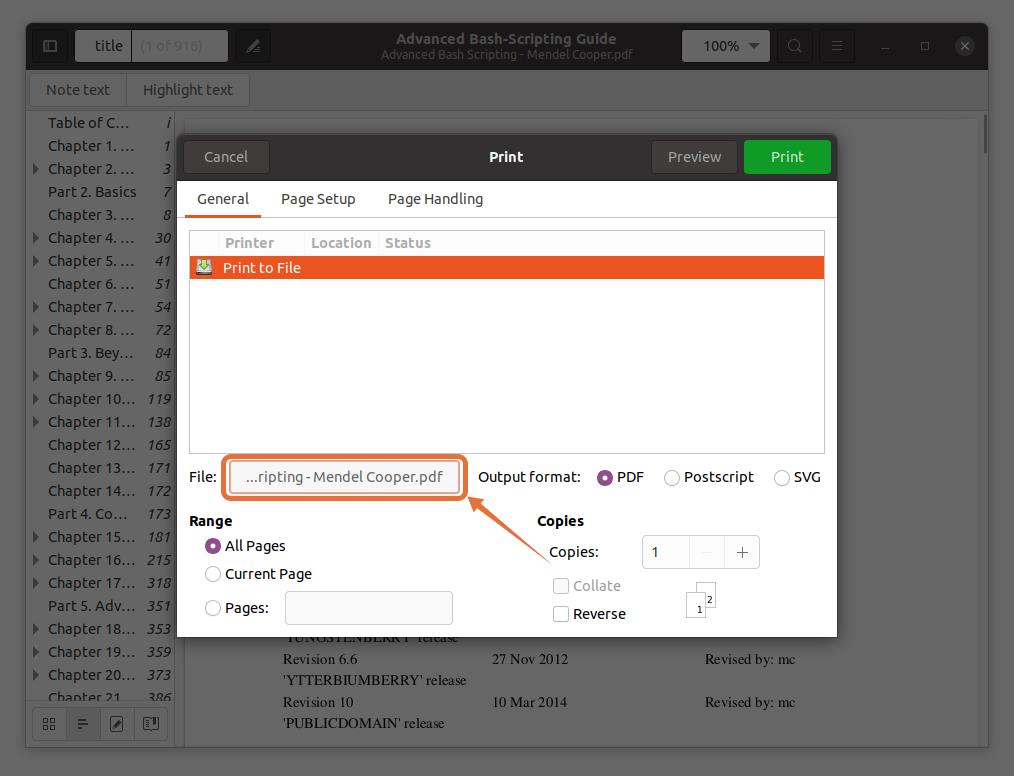
To extract pages in a separate file, click on the “File” option, a window will open, give the file name, and select a location to save it:
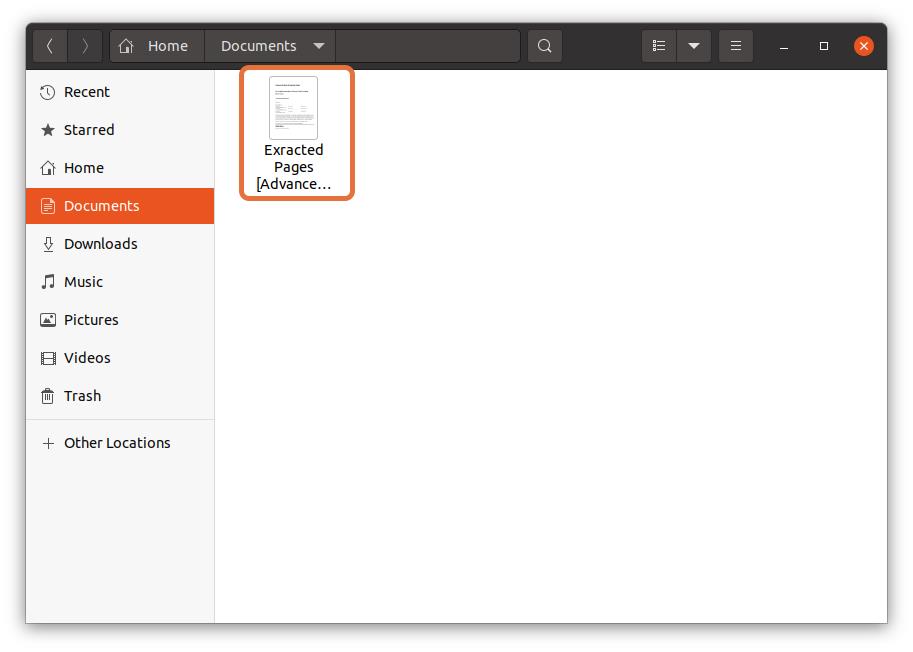
I am selecting “Documents” as the destination location:
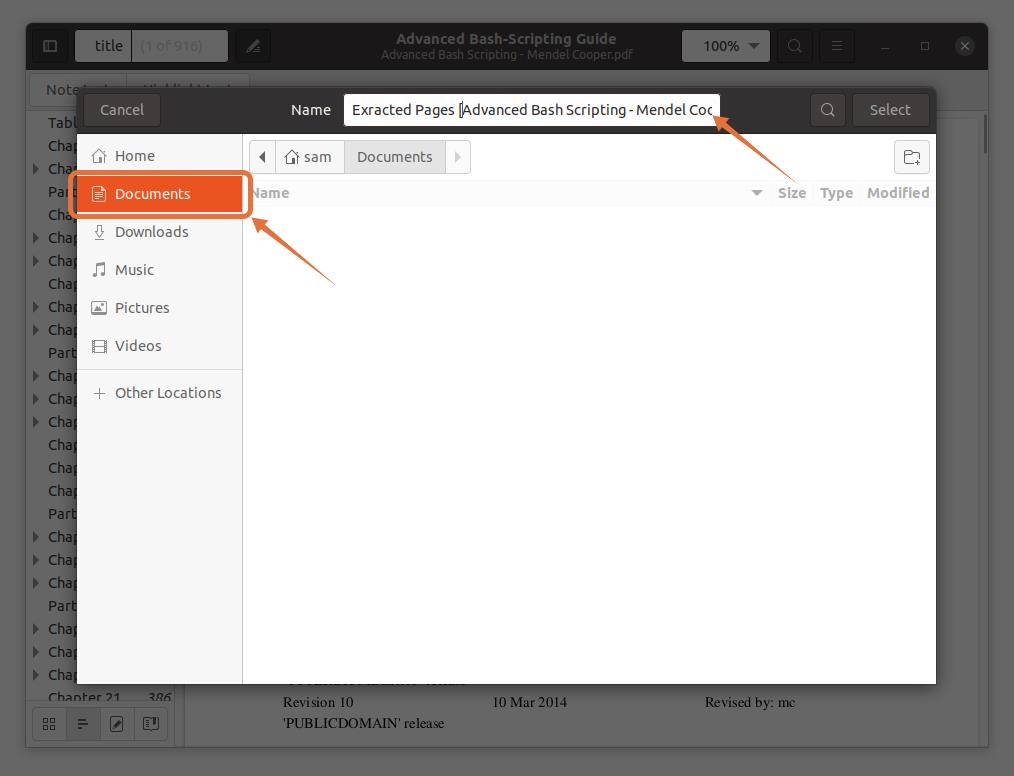
Step 4:
These three output formats PDF, SVG, and Postscript check PDF:
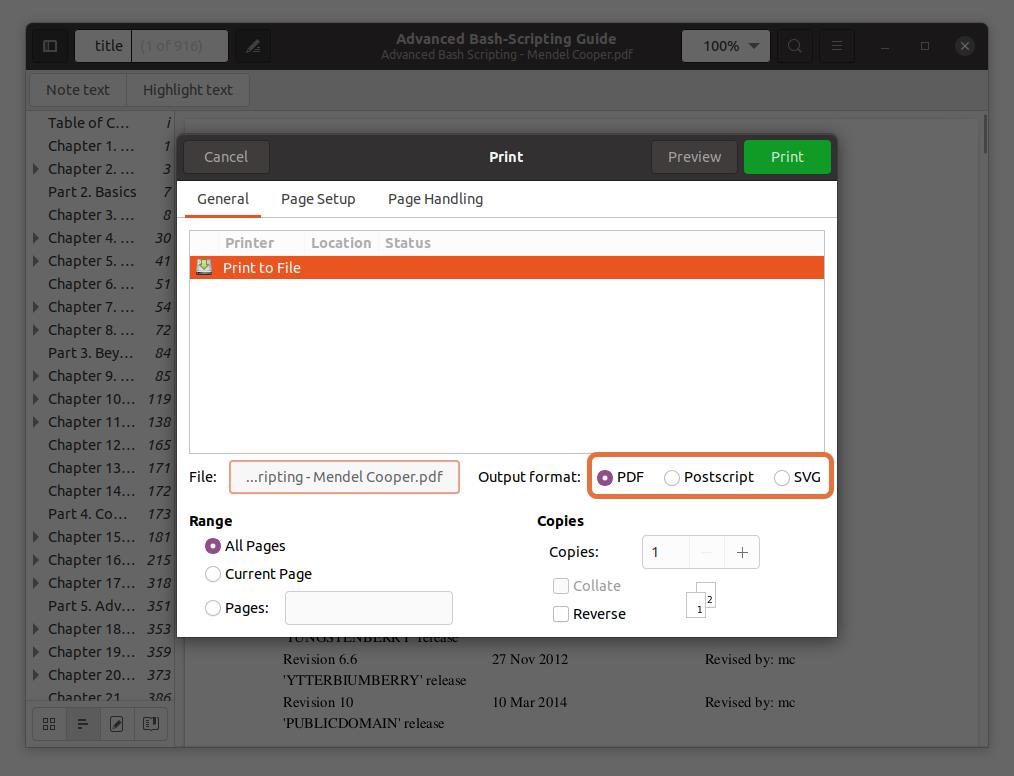
Step 5:
In the “Range” section, check the “Pages” option and set the range of page numbers you want to extract. I am extracting the first five pages so that I would type “1-5”.
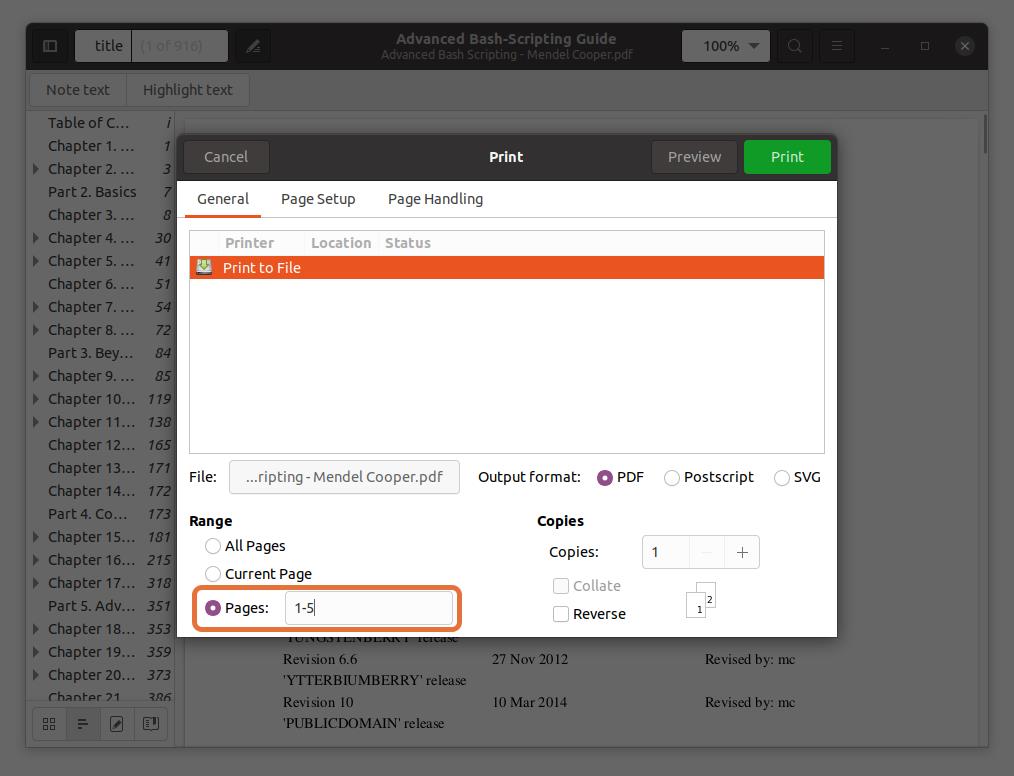
You can also extract any page from the PDF file by typing the page number and separating it by a comma. I am extracting pages number 10 and 11 along with a range for the first five pages.
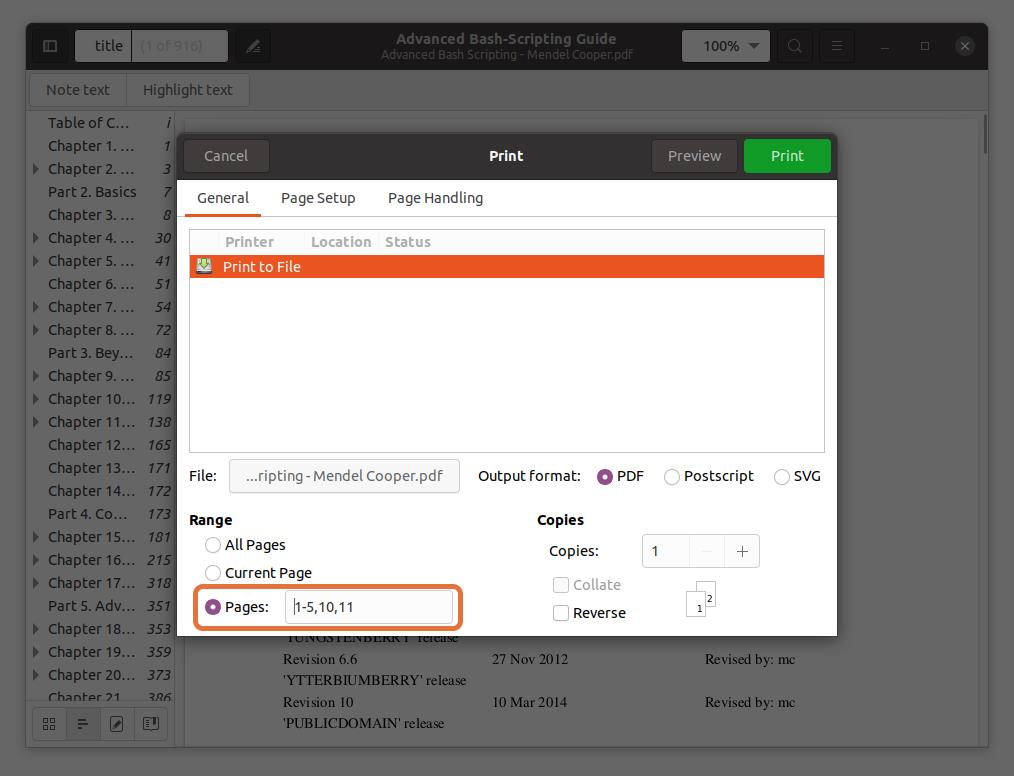
Note that the page numbers I am typing are according to the PDF reader, not the book. Ensure that you enter the page numbers that the PDF reader indicates.
Step 6:
Once all the settings are done, click on the “Print” button, the file will be saved in the specified location:
How to extract PDF pages in Linux via terminal:
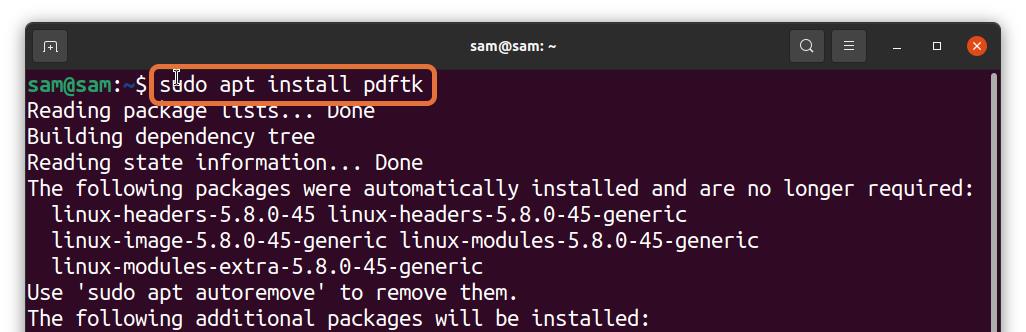
Many Linux users prefer to work with the terminal, but can you extract PDF pages from the terminal? Absolutely! It can be done; all you need a tool to install called PDFtk. To get PDFtk on Debian and Ubuntu, use the command given below:
For Arch Linux, use:
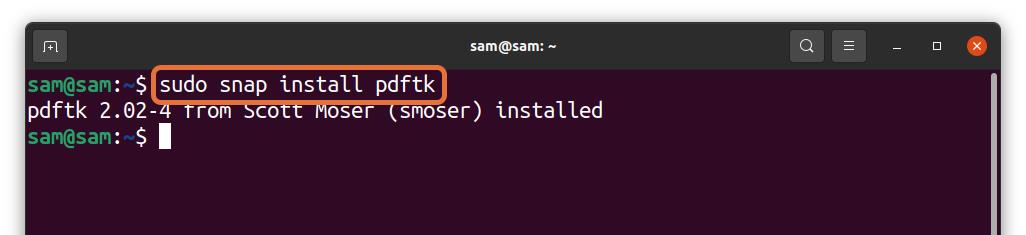
PDFtk can also be installed through snap:
Now, follow the below-mentioned syntax to use PDFtk tool for extracting pages from a PDF file:
- [sample.pdf] – Replace it with the file name from where you want to extract pages.
- [page_numbers] – Replace it with the range of page numbers, for example, “3-8”.
- [output_file_name.pdf] – Type the name of the output file of extracted pages.
Let’s understand it with an example:
extracted_adv_bash_scripting.pdf
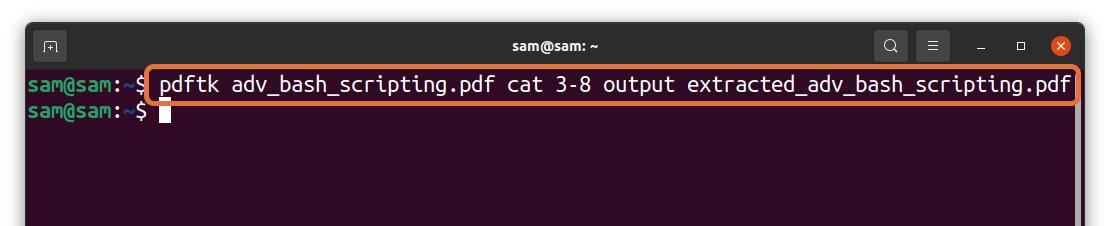
In the above command, I am extracting 6 pages (3 – 8) from a file “adv_bash_scripting.pdf” and saving extracted pages by the name of “extracted_adv_bash_scripting.pdf.” The extracted file will be saved in the same directory.
If you need to extract a specific page, then type the page number and separate them by a “space”:
extracted_adv_bash_scripting_2.pdf

In the above command, I am extracting page numbers 5, 9, and 11 and saving them as “extracted_adv_bash_scripting_2”.
Conclusion:
You may occasionally need to extract some specific portion of a PDF file for several purposes. There are many ways to do it. Some are complex, and some are obsolete. This write-up is about how to extract pages from a PDF file in Linux through two simple methods.
The first method is a trick to extract a certain part of a PDF through Ubuntu’s default PDF reader. The second method is via terminal since many geeks prefer it. I used a tool called PDFtk to extract pages from a pdf file through the use of commands. Both methods are simple; you can choose any according to your convenience.