Amazon offers Simple Storage Service to store unlimited data on the cloud with complete security and secrecy. It allows the user to download and upload the data on it using the management console and AWS Command Line Interface (CLI) commands like “sync” and “cp”.
This guide will explain the downloading of folders from the AWS S3 bucket using AWS CLI commands.
Downloading Folders From AWS S3 Bucket cp vs sync
There are two commands to download files from the AWS S3 bucket that are “sync” and “cp”. “sync” command downloads the updates in the folder from the AWS S3 bucket. On the other hand, the “cp” command simply copies all files placed on the AWS S3 bucket and pastes them into the local folder. The “cp” command downloads all files regardless of their availability in the local directory. Whereas the “sync” only downloads the files that have been updated or not already downloaded to the local folder.
How to Download S3 Folder?
Follow these steps to learn how to download folders available on the S3 bucket using AWS CLI commands.
Step 1: Upload the Folder to S3 Bucket
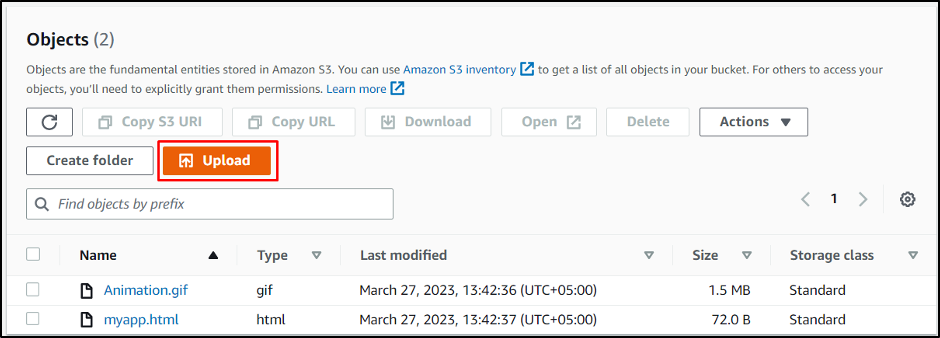
Create an S3 bucket and then head into it to click on the “Upload” button:
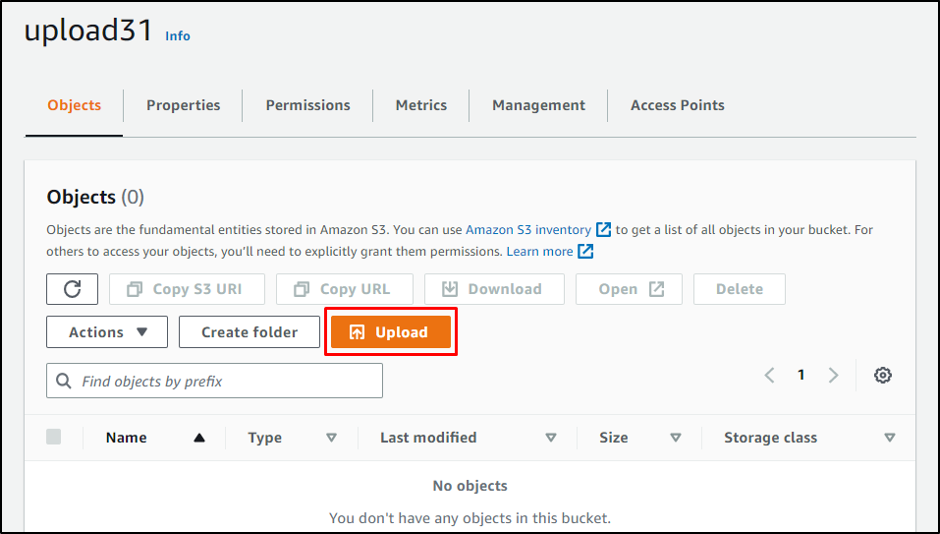
Click on the “Add folder” or drag and drop the folder from the system to the S3 bucket:
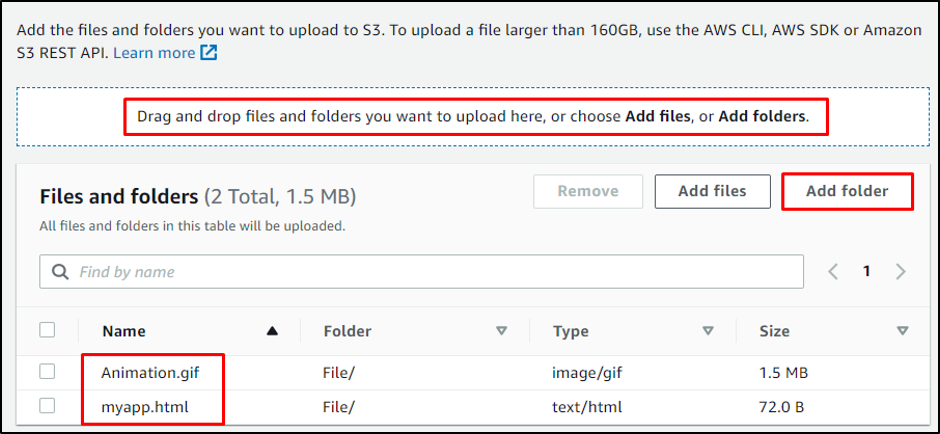
Click on the “Upload” button:
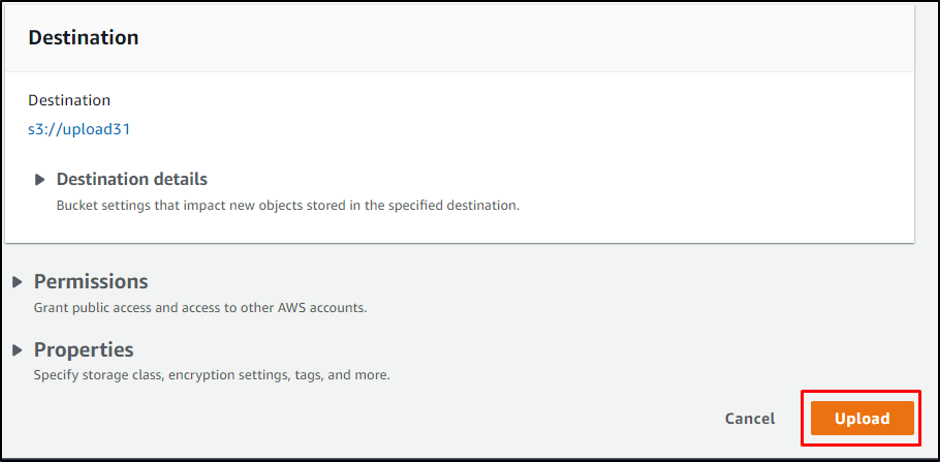
Head inside the folder by clicking on its name:
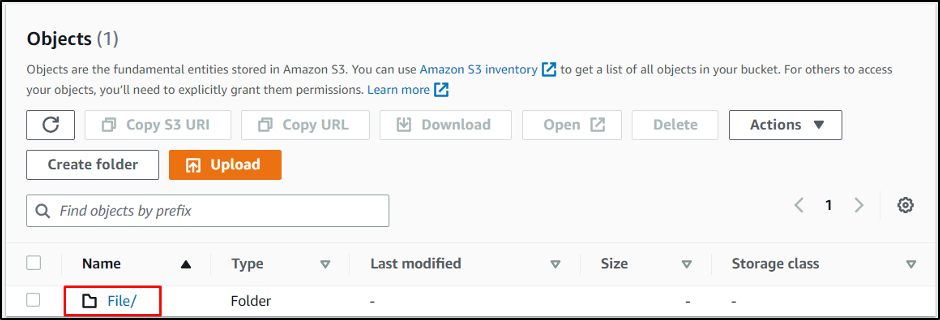
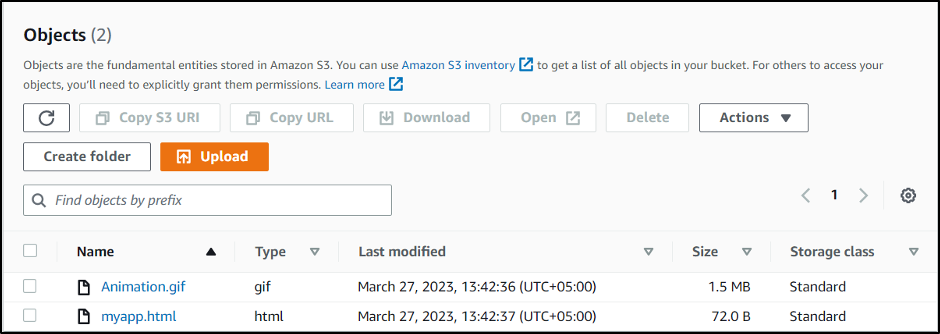
Here are the files uploaded on the S3 bucket:
Step 2: Verify and Configure AWS CLI
Verify the installation of the AWS CLI by typing this:
Running the above command will display the aws-cli/2.0.30 version:

Configure the AWS CLI using the following command:
As a result, you will be prompt to provide IAM credentials:

Step 3: Use of “sync” Command
Head into the folder in which the files should be downloaded:
Use the following syntax and change the <S3Bucket> to the name of your bucket to download the folder from S3 bucket:
In our case, the following command is used to download the folder from the S3 bucket:

It can be observed that the files have been downloaded to the local directory:

Now, let’s upload another file into the S3 bucket:
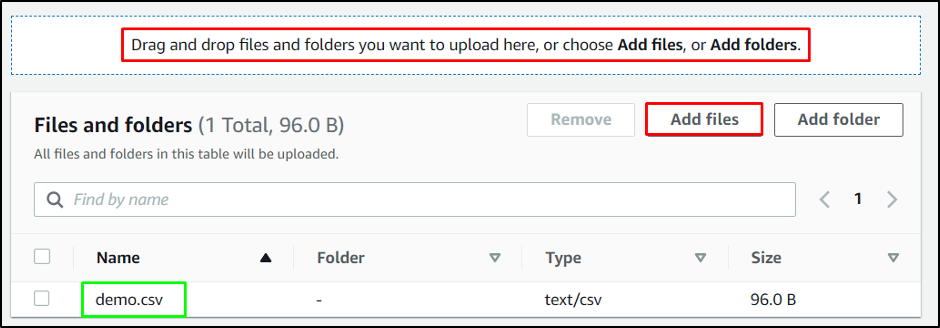
Drag the file and drop it onto the S3 bucket:
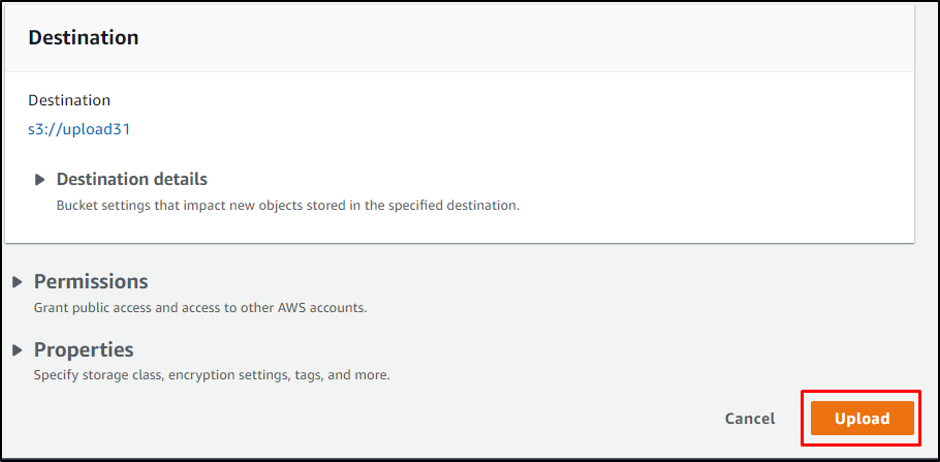
Click on the “Upload” button:
The file has been added to the folder:
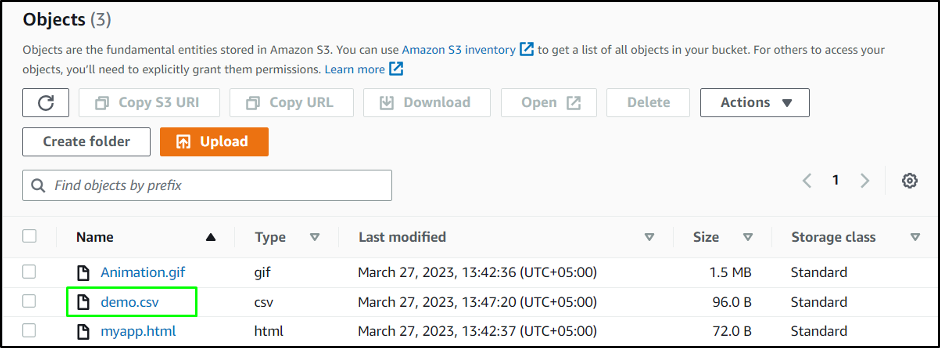
Use the following command to download the newly added file:
Running the above command will only download the “demo.csv” file:

The file has been downloaded to the local directory:
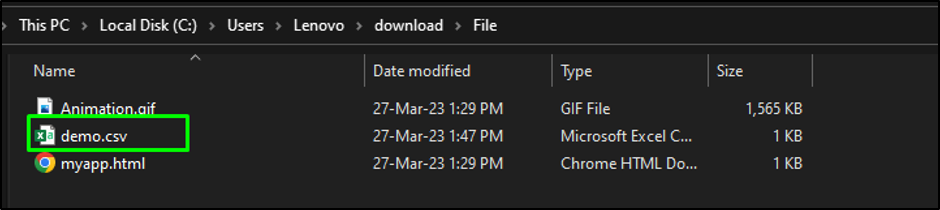
Step 4: Use “cp” Command
Syntax for using the “cp” command is mentioned below:
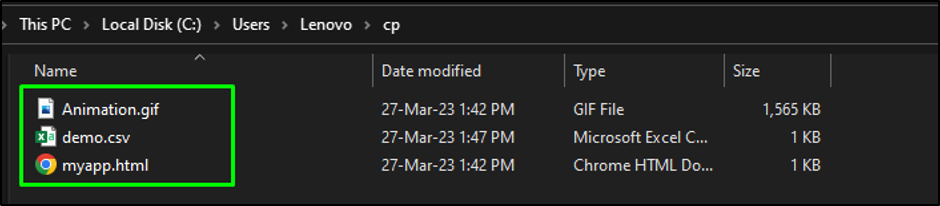
Change the <Bucket> to the S3 bucket name, <Folder> to the folder uploaded on the bucket, and <LocalFolder> to the local directory where the files will be downloaded:

The files have been downloaded from the S3 bucket to the local directory:
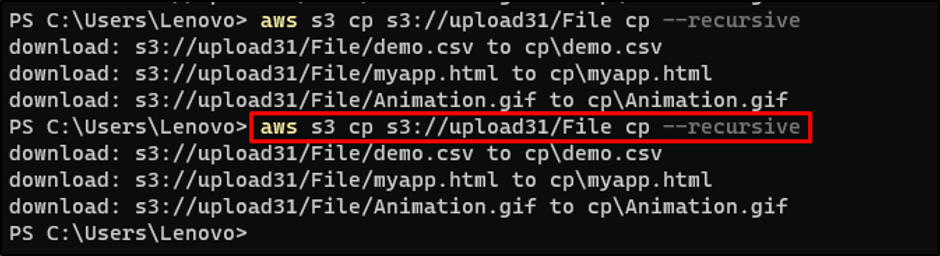
Again, use the same command to download S3 folder:
Running the above command will again download all the files available on the folder:
This guide has explained the process of downloading folders from S3 bucket using “cp” or “sync” command.
Conclusion
There are two methods to download folders from the AWS S3 bucket using AWS CLI commands that are “cp” and “sync” commands. The sync command will download the updated files from the last download whereas, the cp command will always download each file available in the folder. This guide has explained the process of downloading folders from an S3 bucket using the cp and sync commands.