Method 1: Using Dictionary
Dictionary is a datastructure which will store the data in key,value pair format.
The key acts as column and value act as row value/data in the PySpark DataFrame. This has to be passed inside the list.
Structure:
We can also provide multiple dictionaries.
Structure:
Example:
Here, we are going to create PySpark DataFrame with 5 rows and 6 columns through the dictionary. Finally, we are displaying the DataFrame using show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName(‘linuxhint’).getOrCreate()
# create student data with 5 rows and 6 attributes
students =[{‘rollno’:’001’,’name’:’sravan’,’age’:23,
’height’:5.79,’weight’:67,’address’:’guntur’},
{‘rollno’:’002’,’name’:’ojaswi’,’age’:16,
’height’:3.79,’weight’:34,’address’:’hyd’},
{‘rollno’:’003’,’name’:’gnanesh chowdary’,’age’:7,
’height’:2.79,’weight’:17,’address’:’patna’},
{‘rollno’:’004’,’name’:’rohith’,’age’:9,
’height’:3.69,’weight’:28,’address’:’hyd’},
{‘rollno’:’005’,’name’:’sridevi’,’age’:37,
’height’:5.59,’weight’:54,’address’:’hyd’}]
# create the dataframe
df = spark_app.createDataFrame( students)
#display the dataframe
df.show()
Output:

Method 2: Using list of tuples
Tuple is a data structure which will store the data in ().
We can pass the rows separated by comma in a tuple surrounded by a list.
Structure:
We can also provide multiple tuples in a list.
Structure:
We need to provide the column names through a list while creating the DataFrame.
Syntax:
spark_app.createDataFrame( list_of_tuple,column_names)
Example:
Here, we are going to create PySpark DataFrame with 5 rows and 6 columns through the dictionary. Finally, we are displaying the DataFrame using show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[('001','sravan',23,5.79,67,'guntur'),
('002','ojaswi',16,3.79,34,'hyd'),
('003','gnanesh chowdary',7,2.79,17,'patna'),
('004','rohith',9,3.69,28,'hyd'),
('005','sridevi',37,5.59,54,'hyd')]
#assign the column names
column_names = ['rollno','name','age','height','weight','address']
# create the dataframe
df = spark_app.createDataFrame( students,column_names)
#display the dataframe
df.show()
Output:
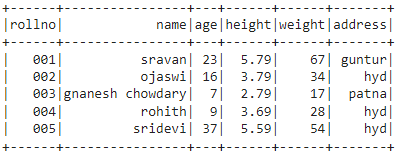
Method 3: Using tuple of lists
List is a data structure which will store the data in [].
We can pass the rows separated by comma in a list surrounded by a tuple.
Structure:
We can also provide multiple lists in a tuple.
Structure:
We need to provide the column names through a list while creating the DataFrame.
Syntax:
spark_app.createDataFrame( tuple_of_list,column_names)
Example:
Here, we are going to create PySpark DataFrame with 5 rows and 6 columns through the dictionary. Finally, we are displaying the DataFrame using show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =(['001','sravan',23,5.79,67,'guntur'],
['002','ojaswi',16,3.79,34,'hyd'],
['003','gnanesh chowdary',7,2.79,17,'patna'],
['004','rohith',9,3.69,28,'hyd'],
['005','sridevi',37,5.59,54,'hyd'])
#assign the column names
column_names = ['rollno','name','age','height','weight','address']
# create the dataframe
df = spark_app.createDataFrame( students,column_names)
#display the dataframe
df.show()
Output:
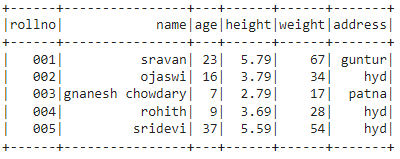
Method 4: Using nested list
List is a datastructure which will store the data in [].
So, we can pass the rows separated by comma in a list surrounded by a list.
Structure:
We can also provide multiple lists in a list.
Structure:
We need to provide the column names through a list while creating the DataFrame.
Syntax:
spark_app.createDataFrame( nested_list,column_names)
Example:
Here, we are going to create PySpark DataFrame with 5 rows and 6 columns through the dictionary. Finally, we are displaying the DataFrame using show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =[['001','sravan',23,5.79,67,'guntur'],
['002','ojaswi',16,3.79,34,'hyd'],
['003','gnanesh chowdary',7,2.79,17,'patna'],
['004','rohith',9,3.69,28,'hyd'],
['005','sridevi',37,5.59,54,'hyd']]
#assign the column names
column_names = ['rollno','name','age','height','weight','address']
# create the dataframe
df = spark_app.createDataFrame( students,column_names)
#display the dataframe
df.show()
Output:
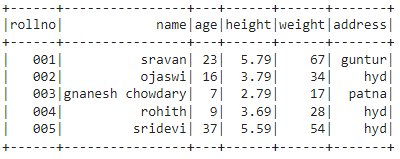
Method 5: Using nested tuple
Structure:
We can also provide multiple tuples in a tuple.
Structure:
((value1,value2,.,valuen), (value1,value2,.,valuen), ………………,(value1,value2,.,valuen))
We need to provide the column names through a list while creating the DataFrame.
Syntax:
spark_app.createDataFrame( nested_tuple,column_names)
Example:
Here, we are going to create PySpark DataFrame with 5 rows and 6 columns through the dictionary. Finally, we are displaying the DataFrame using show() method.
import pyspark
#import SparkSession for creating a session
from pyspark.sql import SparkSession
#create an app named linuxhint
spark_app = SparkSession.builder.appName('linuxhint').getOrCreate()
# create student data with 5 rows and 6 attributes
students =(('001','sravan',23,5.79,67,'guntur'),
('002','ojaswi',16,3.79,34,'hyd'),
('003','gnanesh chowdary',7,2.79,17,'patna'),
('004','rohith',9,3.69,28,'hyd'),
('005','sridevi',37,5.59,54,'hyd'))
#assign the column names
column_names = ['rollno','name','age','height','weight','address']
# create the dataframe
df = spark_app.createDataFrame( students,column_names)
#display the dataframe
df.show()
Output:
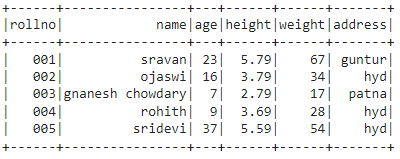
Conclusion
In this tutorial, we discussed five methods to create PySpark DataFrame: list of tuples, tuple of lists, nested tuple, nested list use, and columns list to provide column names. There is no need to provide the column names list while creating PySpark DataFrame using dictionary.