Amazon S3 inventory can be configured to generate reports for specific S3 objects by specifying the prefix. The inventory then can be sent to the destination bucket within the same account or a different account. Multiple S3 inventories can also be configured for the same S3 bucket with different S3 object prefixes, destination buckets and output file types. Also, you can specify whether the inventory file will be encrypted or not.
This blog will see how inventory can be configured in the S3 bucket using the AWS management console.
Creating inventory configuration
First, log into the AWS management console and go to the S3 service.
From the S3 console, go to the bucket for which you want to configure inventory.

Inside the bucket, go to the management tab.

Scroll down and go to the inventory configuration section. Click on the create inventory configuration button to create the inventory configuration.
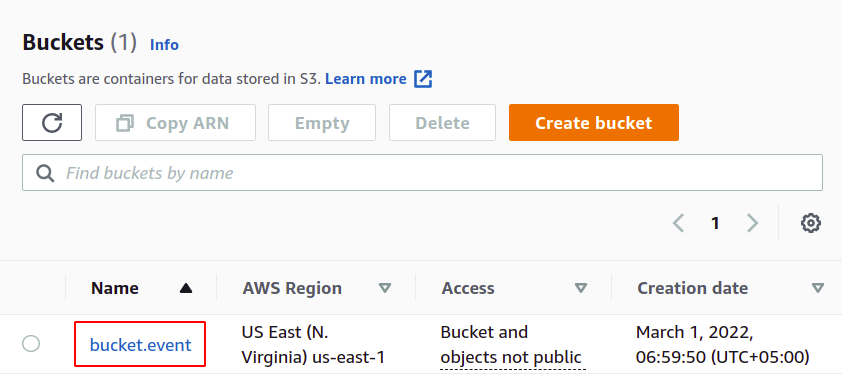
It will open a configuration page to configure inventory. First, add the inventory configuration name that must be unique inside the S3 bucket. Then provide the S3 object prefix if you want to limit the inventory to specific S3 objects. In order to cover all the objects in the S3 bucket, leave the prefix field empty.
For this demo, we will limit the inventory scope to the object with prefix server-logs.
Also, the inventory configuration can be limited to the current version, or the previous can also be covered under the inventory. For this demo, we will limit the inventory scope to the current version only.
After specifying the inventory scope, it will now ask for the report details. The report can be saved to the destination S3 bucket within or across the account. First, select whether you want to save the inventory reports to the S3 bucket in the same or different account. Then enter the name of the destination bucket or browse S3 buckets from the console.

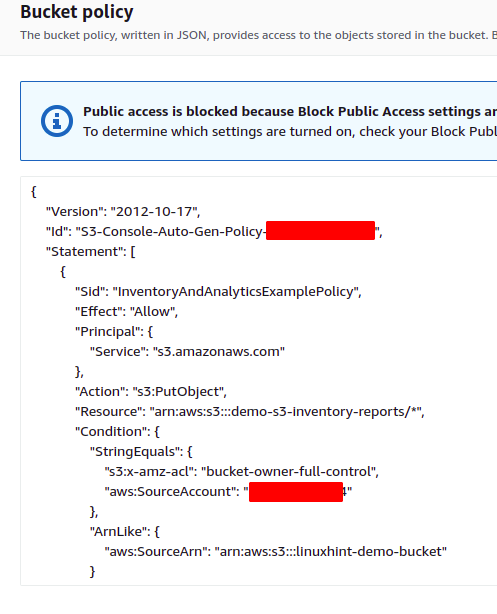
A bucket policy is automatically added to the destination bucket, which allows the source bucket to write data in the destination bucket. The following bucket policy will be added to the destination S3 bucket for this demo.

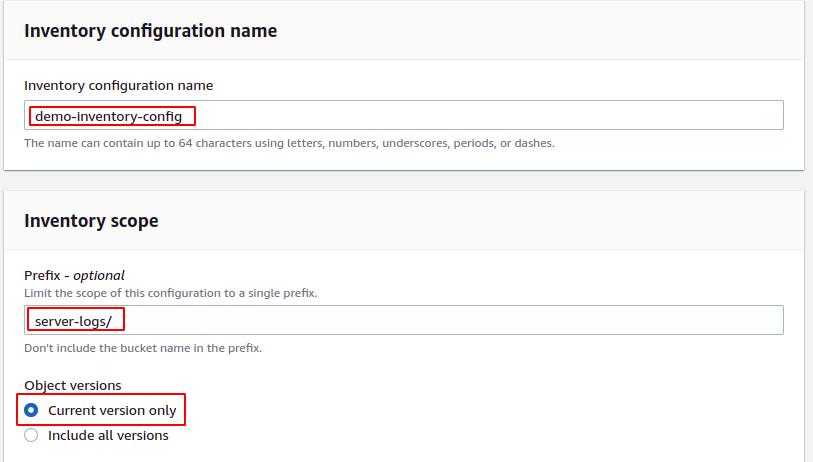
After specifying the destination S3 bucket for the inventory report, now provide the time period after which the inventory report will be generated. AWS S3 bucket can be configured to generate daily or weekly inventory reports. For this demo, we will select the daily report generation option.
The output formation option specifies in which format the inventory file will be generated. AWS S3 supports the following three output formats for inventory.
- CSV
- Apache ORC
- Apache Parquet
For this demo, we will select the CSV output format. The Status options sets the status of the inventory configuration. If you want to enable the S3 inventory configuration right after creating it, set this option to Enable.
The generated inventory reports can be encrypted on the server-side by enabling the server-side encryption option. You need to select either the KMS key or the customer-managed key if enabled. For this demo, we will not enable server-side encryption.

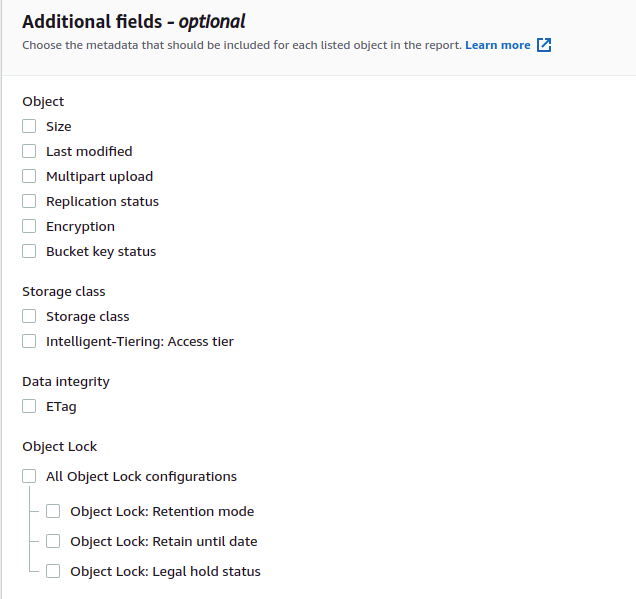
You can also customize the generated inventory report by adding additional fields to the report. AWS S3 inventory provides the configuration to add additional metadata to the inventory reports. Under the Additional fields section, select the fields that you want to add to the inventory report. For this demo, we will not select any additional fields.
Now click on the create button at the bottom of the configuration page to create the inventory configuration for the S3 bucket. It will create the inventory configuration and add a bucket policy to the destination bucket. Go to the destination bucket by clicking on the destination bucket URL.
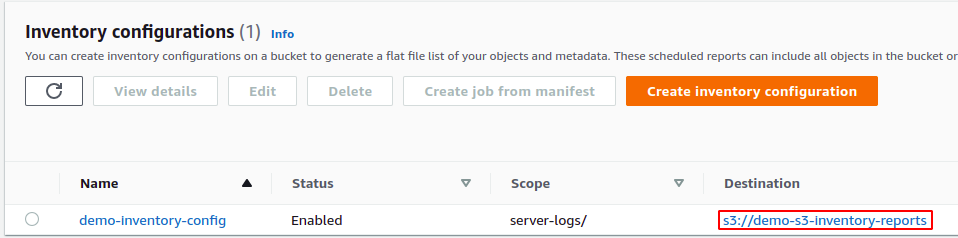
In the destination S3 bucket, go to the permissions tab.
Scroll down to the Bucket policy section, and there will be an S3 bucket policy that allows the source S3 bucket to pass inventory reports to the destination S3 bucket.
Now go to the source S3 bucket and create a server-logs directory. Upload a file to the directory by using the AWS S3 console.
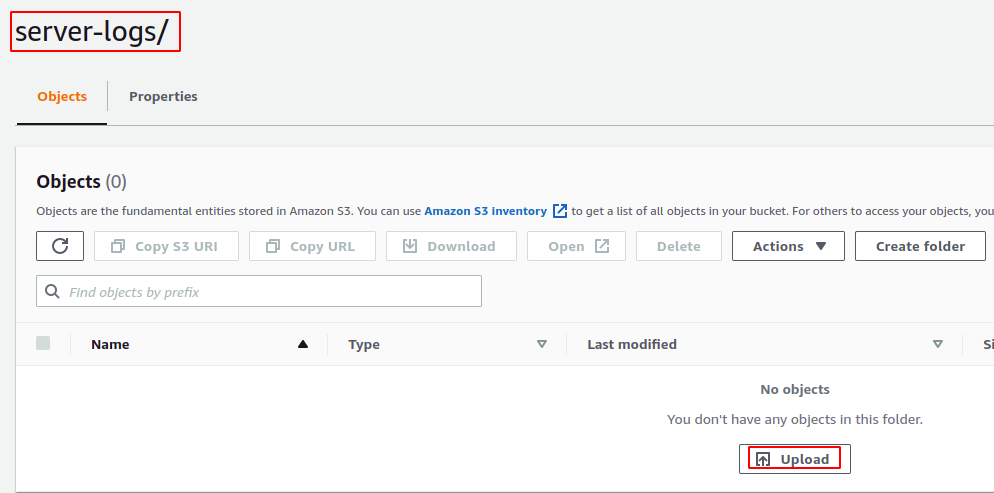
After uploading the file to the source S3 bucket, it may take upto 48 hours to generate the first inventory report. After the initial report, the next report will be generated by the time period specified by you in the inventory configuration.
Reading inventory from destination S3 bucket
After 48 hours of configuring the inventory for the S3 bucket, go to the destination S3 bucket, and the inventory report will be generated for the S3 bucket.
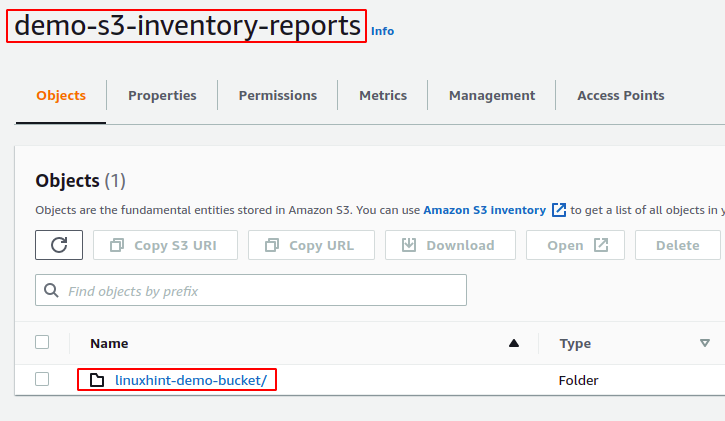
The reports for the inventory are generated in a specific directory structure in the S3 destination bucket. To see the directory structure, download the report directory and run the tree command inside the report directory.
ubuntu@ubuntu:~$ tree .
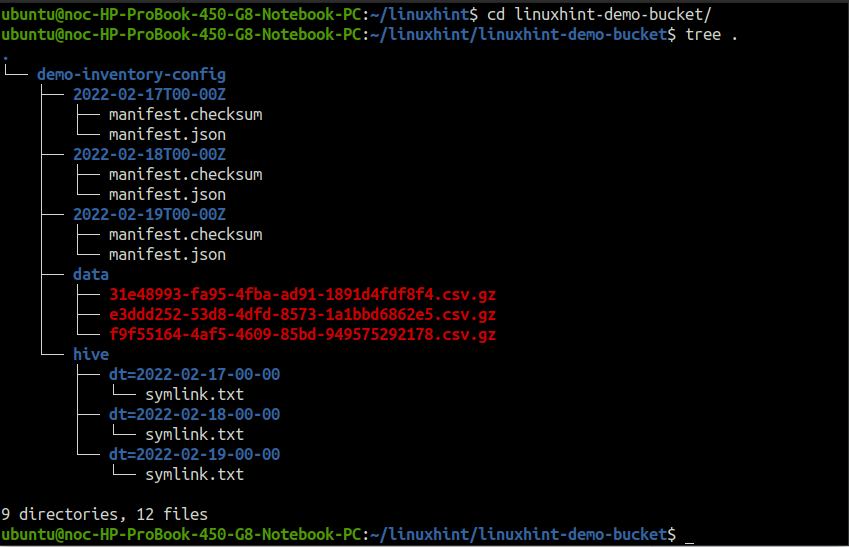
The demo-inventory-config directory (named after the inventory configuration name) inside the linuxhint-demo-bucket (named after source S3 bucket name) contains all the data related to the inventory report.
The data directory includes the CSV files compressed in gzip format. Unzip a file and cat it in the terminal.
ubuntu@ubuntu:~$ cat <file name>

The directories inside the demo-inventory-config directory, named after the date on which they are created, include the metadata of the inventory reports. Use the cat command to read the manifest.json file.

Similarly, the hive directory includes files that point to the inventory report of a specific date. Use the cat command to read any of the symlink.txt files.

Conclusion
AWS S3 provides inventory configuration to manage the storage and generate audit reports. S3 inventory can be configured for specific S3 objects specified by the S3 object prefix. Also, multiple inventory configurations can be created for a single S3 bucket. This blog describes the detailed procedure for creating S3 inventory configurations and reading the inventory reports from the S3 destination bucket.