
Configuring Cache on your ZFS pool
If you have been through our previous posts on ZFS basics you know by now that this is a robust filesystem. It performs checksums on every block of data being written on the disk and important metadata, like the checksums themselves, are written in multiple different places. ZFS might lose your data, but it is guaranteed to never give you back wrong data, as though it were the right one.
Most of the redundancy for a ZFS pool comes from the underlying VDEVs. The same is true for the storage pool’s performance. Both the read and write performance can improve vastly by the addition of high speed SSDs or NVMe devices. If you have used hybrid disks where an SSD and spinning disk are bundled as a single piece of hardware, then you know how bad the hardware level caching mechanisms are. ZFS is nothing like this, because of various factors, which we will explore here.
[adthrive-in-post-video-player video-id=”Ny5EnTsU” upload-date=”2020-02-21T15:31:18.000Z” name=”Configuring ZFS Cache” description=”Improve system performance with ZFS by configuring the cache for the filesystem” player-type=”collapse” override-embed=”true”]
There are two different caches that a pool can make use of:
- ZFS Intent Log, or ZIL, to buffer WRITE operations.
- ARC and L2ARC which are meant for READ operations.
Synchronous vs Asynchronous Writes
ZFS, like most other filesystems, tries to maintain a buffer of write operations in memory and then write it out to the disks instead of directly writing it to the disks. This is known as asynchronous write and it gives decent performance gains for applications that are fault tolerant or where data loss doesn’t do much damage. The OS simply stores the data in memory and tells the application, who requested the write, that the write is completed. This is the default behavior of many operating systems, even when running ZFS.
However, the fact remains that in case of system failure or power loss, all the buffered writes in the main memory are lost. So applications which desire consistency over performance can open files in synchronous mode and then the data is only considered to be written once it is actually on the disk. Most databases, and applications like NFS, do rely on synchronous writes all the time.
You can set the flag: sync=always to make synchronous writes the default behavior for any given dataset.
Of course, you may desire to have a good performance regardless of whether or not the files are in synchronous mode. That’s where ZIL comes into the picture.
ZFS Intent Log (ZIL) and SLOG devices
ZFS Intent Log refers to a portion of your storage pool that ZFS uses to store new or modified data first, before spreading it out throughout the main storage pool, stripping across all the VDEVs.
By default some small amount of storage is always carved out from the pool to act like ZIL, even when you are using just a bunch of spinning disks for your storage. However, you can do better if you have a small NVMe or any other type of SSD at your disposal.
The small and fast storage can be used as a Separate Intent Log (or SLOG), which is where the newly arrived data would be stored temporarily before being flushed to the larger main storage of the pool. To add a slog device run the command:
Where tank is the name of your pool, log is the keyword telling ZFS to treat the device ada3 as a SLOG device. Your SSD’s device node may not necessarily be ada3, use the correct node name.
Now you can check the devices in your pool as shown below:
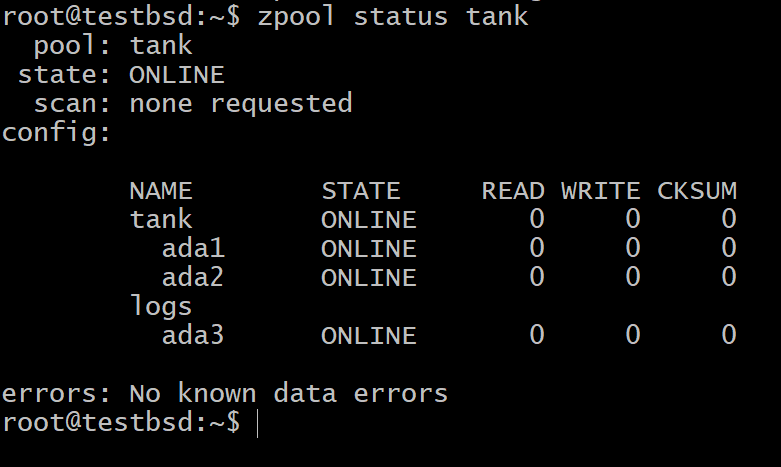
You may still be worried that the data in a non-volatile memory would fail, if the SSD fails. In that case, you can use multiple SSDs mirroring each other or in any RAIDZ configuration.
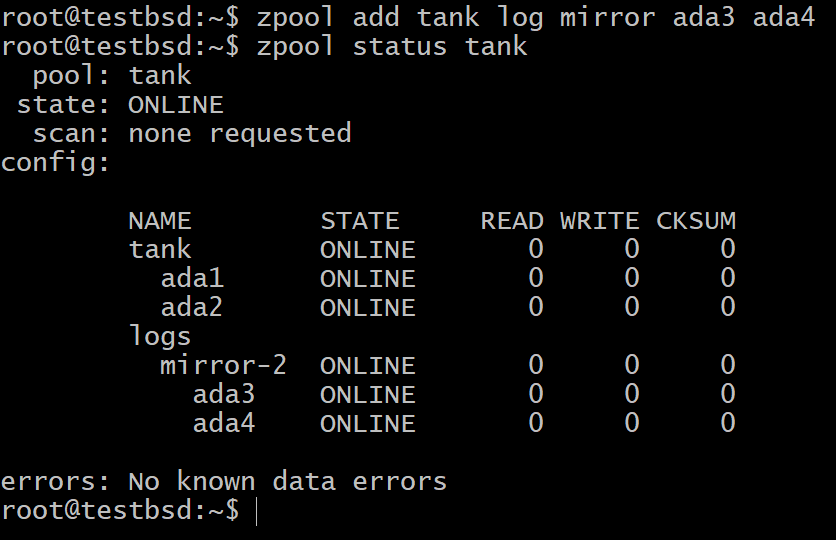
For most use cases, the small 16GB to 64GB of really fast and durable flash storage are the most suitable candidates for a SLOG device.
Adaptive Replacement Cache (ARC) and L2ARC
When trying to cache the read operations, our objective changes. Instead of making sure that we get good performance, as well as reliable transactions, now ZFS’ motive shifts to predicting the future. This means, caching the information that an application would require in the near future, while discarding the ones that will be needed furthest ahead in time.
To do this a part of main memory is used for caching data that was either used recently or the data is being accessed most frequently. That’s where the term Adaptive Replacement Cache (ARC) comes from. In addition to traditional read caching, where only the most recently used objects are cached, the ARC also pays attention to how often the data has been accessed.
L2ARC, or Level 2 ARC, is an extension to the ARC. If you have a dedicated storage device to act as your L2ARC, it will store all the data that is not too important to stay in the ARC but at the same time that data is useful enough to merit a place in the slower-than-memory NVMe device.
To add a device as the L2ARC to your ZFS pool run the command:
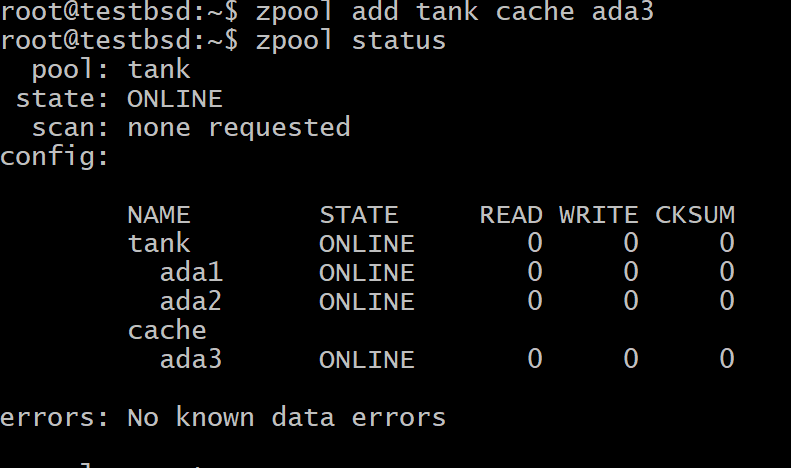
Where tank is your pool’s name and ada3 is the device node name for your L2ARC storage.
Summary
To cut a long story short, an operating system often buffers write operations in the main memory, if the files are opened in asynchronous mode. This is not to be confused with ZFS’ actual write cache, ZIL.
ZIL, by default, is a part of non-volatile storage of the pool where data goes for temporary storage before it is spread properly throughout all the VDEVs. If you use an SSD as a dedicated ZIL device, it is known as SLOG. Like any VDEV, SLOG can be in mirror or raidz configuration.
Read cache, stored in the main memory, is known as the ARC. However, due to the limited size of RAM, you can always add an SSD as an L2ARC, where things that can’t fit in the RAM are cached.